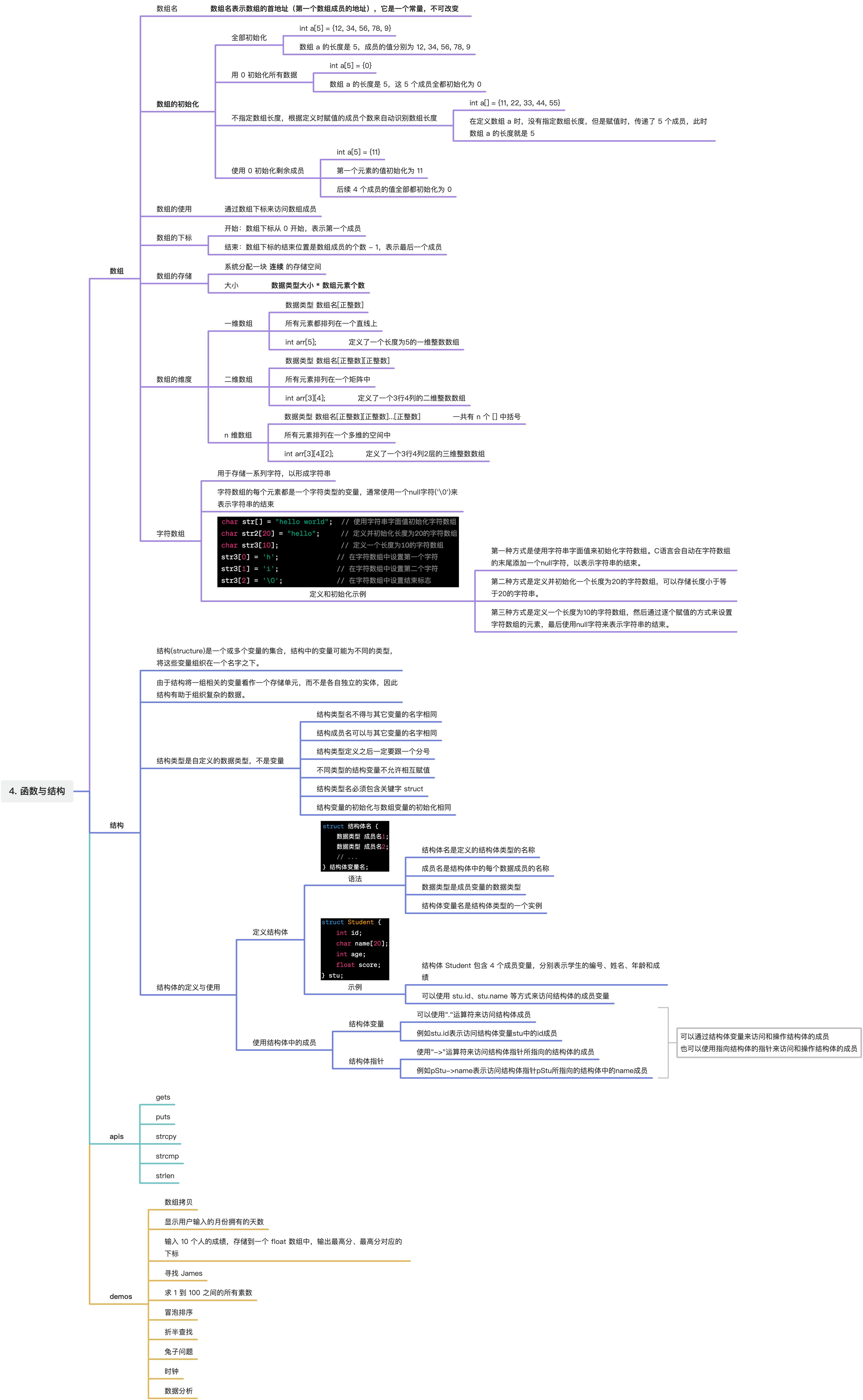
课件
思维导图
4.1 数组
引言
一维数组基础理论
 00:00:21 | demo | 找出最高分
00:00:21 | demo | 找出最高分

假设 10 人:
按照我们之前学习的基本数据类型,很可能会直接定义 10 个变量来存这 10 个人的成绩。但是,如果成员过多,我们还是按照传统方式,一个人定义一个变量去存储,显然就不合适了。

正确的做法是使用数组
00:02:10 | 定义数组
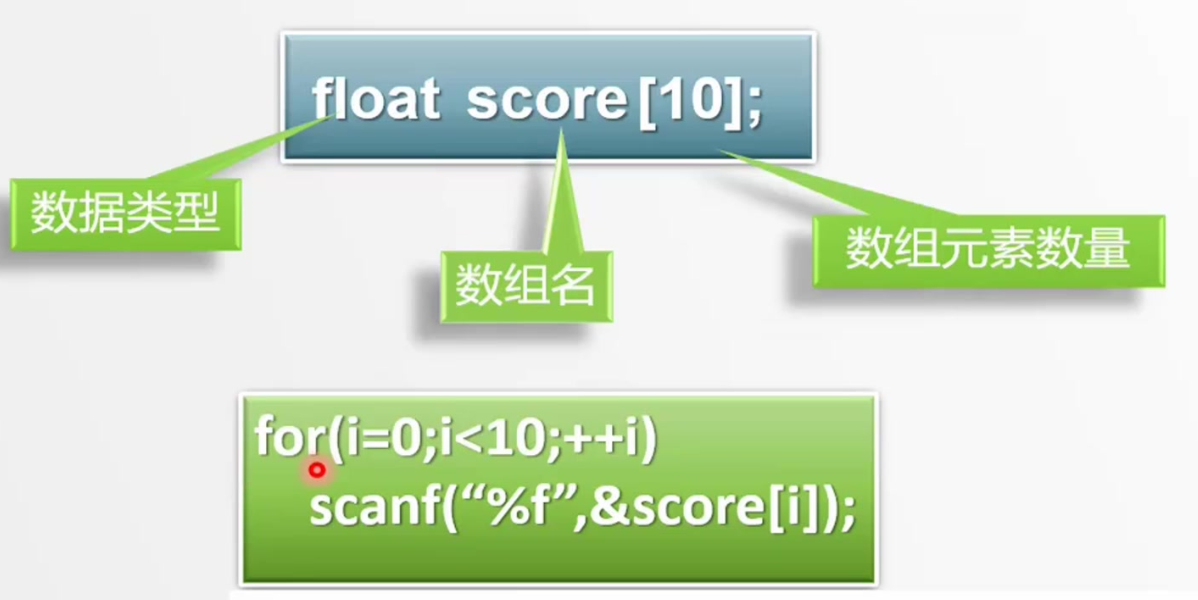
注意:
- 数组中的所有成员的类型都是一致的
- 在定义数组的同时,就需要初始化数组的长度

定义数组时初始化数组:
int a[5] = { 12, 34, 56, 78, 9 };- 全部初始化
int a[5] = { 0 };- 用 0 初始化所有数据
int a[] = { 11, 22, 33, 44, 55 };[]内不写数组长度,根据初始化时成员个数来设置数组长度,存入几个成员,长度就是几
int a[5] = { 11 };- 第一个成员初始化为 11,后续全部用 0 初始化
a[0] == 11a[1]a[2]a[3]a[4]都是 0
00:08:24 | 访问一维数组的成员


00:09:19 | 一维数组的存储

理解数组成员在内存中的存储机制:

这就是为什么 数组 可以 快 速通过 下标访问 数组成员的原因
00:11:31 | 【例1】如何使两个数组的值相等?

这种做法是错误的:

PS:这种做法在 JS 中是正确的……
正确的做法:
00:13:35 | 【例2】显示用户输入的月份拥有的天数(不包括闰年的月份)

源码: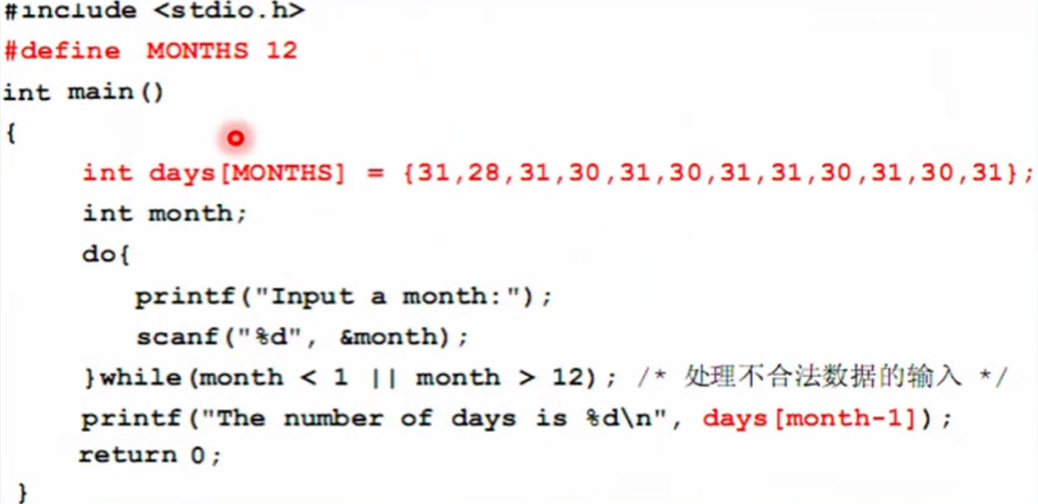
一维数组实例
00:00:47 | 题目描述

00:01:17 | debug

错误 1:定义数组的时候,数组的长度必须是一个常量,这里我们传入的 n 是一个变量,这是错误的。
解决方式:将 n 定义为一个常量
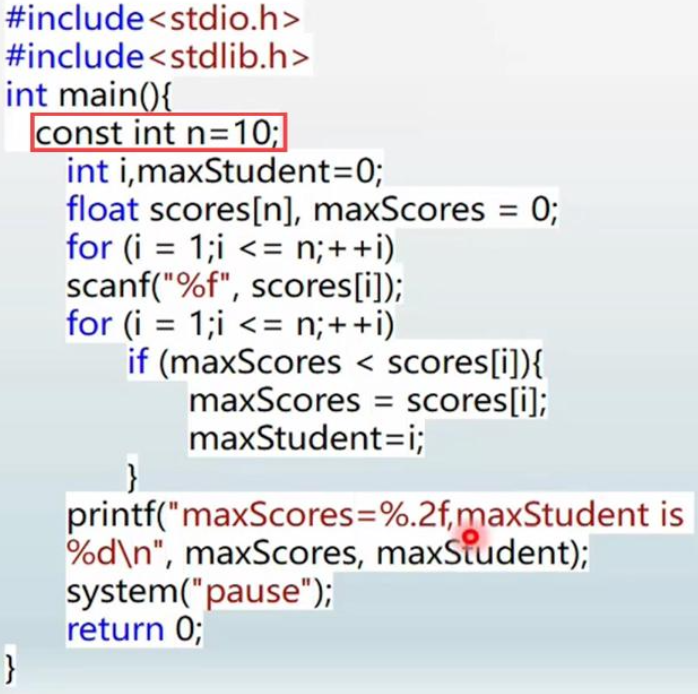
注意:这种写法是存在兼容性的,在 .cpp 结尾的文件中可行,但是在 .c 结尾的文件中不可行。
错误 2:下标越界,数组的下标是从 0 开始的,如果下标取到数组长度值,那么下标会越界。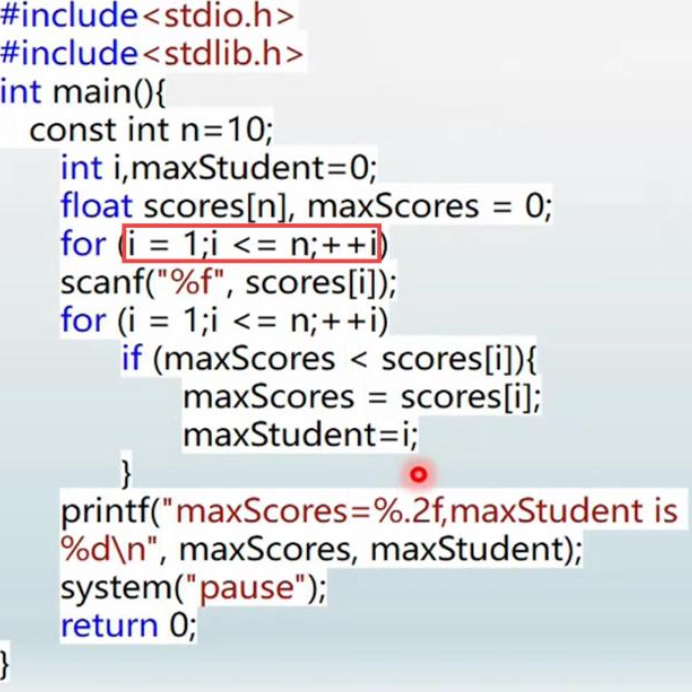
错误 3:这一部分需要使用取地址符,正确写法:&scores[i]
二维数组
字符数组
notes
简述
理解数组名 👉🏻 5.2 指针与数组
数组类型 和 结构体类型 的应用场景举例
- 数据存储和处理:
- 数组可以用来存储和处理大量的数据,如存储学生的成绩、存储一个城市的人口数据等。
- 结构体可以用来存储一个对象的多个属性,如一个人的姓名、年龄、性别等。
- 算法实现:
- 数组可以用来实现排序算法、查找算法等。
- 结构体可以用来实现树、图等数据结构。
- 图形处理:
- 数组可以用来存储图像数据
- 结构体可以用来表示一个点、一条线、一个多边形等
- 网络编程:
- 数组可以用来存储和处理网络数据,如 TCP/IP 协议中的数据包。
- 结构体可以用来表示网络数据包的头部、负载等。
- 数据库编程:
- 数组可以用来存储查询结果集
- 结构体可以用来表示表的一条记录
- 游戏编程:
- 数组可以用来存储游戏地图、存档等数据
- 结构体可以用来表示游戏中的角色、武器等
综上,掌握好数组和结构是非常有必要的,数组和结构是编程中非常基础和重要的数据结构,可以用来解决各种不同的问题。
补充:几乎所有高级语言都有类似“数组”、“结构体”这样的概念,它们的特点几乎都是一样的。要知道这玩意掌握好之后,是一劳永逸的就对了。
理解数组名
在 C 语言中,对于数组名,我们需要知道以下几点:
- 数组名表示数组首元素的地址
- 数组名是一个指向数组第一个元素的指针
- 数组名是常量,因此不能被重新赋值
- 由于数组名是常量,无法直接赋值,所以 无法通过数组名来直接拷贝数组
- 可以将数组名看做是一个“常量”指针(不能修改其指向)
- 数组元素可以使用下标来访问,也可以使用指针来访问
一维数组
定义一维数组的语法:type arrayName[arraySize];
type- 数组元素的数据类型
- 数组中所有成员的类型都是 type 类型
arrayName:数组名arraySize:数组成员的个数
int myArray[10]; // 定义一个由 10 个整数组成的数组 myArrayfloat prices[5]; // 定义一个由 5 个浮点数组成的数组 prices
对于数组,我们还需要知道以下概念:
- 数组成员:数组中的每一个元素
- 连续存储
- 数组在内存空间中的存储是 连续 的
- 只要是数组,那么它在内存中的存储机制就是连续存储的,无论维度是多少
- 数组下标
- 从 0 开始,到数组长度减 1 的位置
- 第一个成员下标是
0 - 最后一个成员下标是
数组长度 - 1
- 越界错误:如果使用一个超过数组长度或小于 0 的下标值进行访问,就会产生越界错误。
#include <stdio.h>int main() {int arr[5] = {1, 2, 3, 4, 5}; // 定义一个数组并初始化// 访问数组中的元素printf("arr[0] = %d\n", arr[0]);printf("arr[1] = %d\n", arr[1]);printf("arr[2] = %d\n", arr[2]);printf("arr[3] = %d\n", arr[3]);printf("arr[4] = %d\n", arr[4]);// 修改数组中的元素arr[2] = 10;printf("arr[2] = %d\n", arr[2]);return 0;}/* 运行结果:arr[0] = 1arr[1] = 2arr[2] = 3arr[3] = 4arr[4] = 5arr[2] = 10*/
#include <stdio.h>int main() {int arr[5] = {11}; // 第一个成员初始化为 11,后续成员都缺省了,对于缺省的部分,会全部用 0 初始化printf("arr[0] = %d\n", arr[0]);printf("arr[1] = %d\n", arr[1]);printf("arr[2] = %d\n", arr[2]);printf("arr[3] = %d\n", arr[3]);printf("arr[4] = %d\n", arr[4]);return 0;}/* 运行结果:arr[0] = 11arr[1] = 0arr[2] = 0arr[3] = 0arr[4] = 0*/
#include <stdio.h>int main() {int arr[] = {1, 2, 3, 4, 5}; // [] 内不写数组长度,根据初始化时成员个数来设置数组长度,存入几个成员,长度就是几int len = sizeof(arr) / sizeof(arr[0]); // 计算长度printf("数组的长度为:%d\n", len); // 5printf("数组的 第一个成员:%d\n", arr[0]); // 1printf("数组的 最后一个成员:%d\n", arr[len - 1]); // 5return 0;}/* 运行结果:数组的长度为:5数组的 第一个成员:1数组的 最后一个成员:5*/
计算数组长度:sizeof(arr) / sizeof(arr[0])
sizeof(arr)获取整个数组 arr 所占用的总字节数sizeof(arr[0])获取一个数组成员所占用的字节数- 有关数组长度计算的详细描述 👉🏻 链接
数组拷贝
需求:
现在有一个 int arr[5] = {1, 2, 3, 4, 5}; arr 数组,我们需要拷贝一份值一模一样的数组 arr_copy。
int arr[5] = {1, 2, 3, 4, 5}, arr_copy[5];// 定义俩长度为 5 的整型数组 arr、arr_copyarr_copy = arr; // error// 数组名 arr_copy 是常量,无法被重新赋值
#include <stdio.h>int main() {int arr[] = {1, 2, 3, 4, 5};int arr_copy[5];// 逐个拷贝arr_copy[0] = arr[0];arr_copy[1] = arr[1];arr_copy[2] = arr[2];arr_copy[3] = arr[3];arr_copy[4] = arr[4];arr_copy[2] = 30; // 修改拷贝之后的数组,并不会影响到原数组 arrprintf("原数组:");for (int i = 0; i < 5; i++) {printf("%d ", arr[i]);}printf("\n拷贝数组:");for (int i = 0; i < 5; i++) {printf("%d ", arr_copy[i]);}return 0;}/* 运行结果:原数组:1 2 3 4 5拷贝数组:1 2 30 4 5*/
#include <stdio.h>int main() {int arr[] = {1, 2, 3, 4, 5};int arr_copy[5];int len = sizeof(arr) / sizeof(arr[0]);// 通过循环赋值拷贝for (int i = 0; i < len; i++) {arr_copy[i] = arr[i];}arr_copy[2] = 30; // 修改拷贝之后的数组,并不会影响到原数组 arrprintf("原数组:");for (int i = 0; i < 5; i++) {printf("%d ", arr[i]);}printf("\n拷贝数组:");for (int i = 0; i < 5; i++) {printf("%d ", arr_copy[i]);}return 0;}/* 运行结果:原数组:1 2 3 4 5拷贝数组:1 2 30 4 5*/
数组拷贝的实现方式还有很多,上述记录的这两种方式是最为基础的实现方式。
打印用户输入的月份拥有的天数(不考虑闰年)
#include <stdio.h>int main() {int month;printf("请输入月份:");scanf("%d", &month);switch (month) {case 1:case 3:case 5:case 7:case 8:case 10:case 12:printf("%d 月有 31 天\n", month);break;case 4:case 6:case 9:case 11:printf("%d 月有 30 天\n", month);break;case 2:printf("%d 月有 28 天\n", month);break;default:printf("输入的月份无效\n");break;}return 0;}/* 运行结果:请输入月份:33 月有 31 天请输入月份:99 月有 30 天请输入月份:22 月有 28 天请输入月份:24输入的月份无效*/
输入 3 人成绩,输出成绩最高的人
#include <stdio.h>int main() {const int totalCount = 3;int scores[totalCount];int max_score = 0;int max_index = 0;// 输入 3 个人的成绩printf("请输入 3 个人的成绩:\n");for (int i = 0; i < totalCount; i++) {printf("第 %d 个人的成绩:", i + 1);scanf("%d", &scores[i]);}// 找到最高分及所在位置for (int i = 0; i < totalCount; i++) {if (scores[i] > max_score) {max_score = scores[i];max_index = i + 1;}}// 输出结果printf("最高分为:%d,所在位置为第 %d 个人\n", max_score, max_index);return 0;}/* 运行结果:请输入 3 个人的成绩:第 1 个人的成绩:30第 2 个人的成绩:90第 3 个人的成绩:60最高分为:90,所在位置为第 2 个人*/
scanf("%d", &scores[i]); 等效写法 scanf("%d", scores+i);
如何区分数组的维度
一个数组的维数可以 通过数组定义时方括号 **[]** 的数量来确定。
例:
- 一个一维数组在定义时只有一个方括号
- 一个二维数组则有两个方括号
通常情况下,方括号的数量对应着数组的维度。
定义多维数组的语法
type array_name[size1][size2]...[sizeN];
type数组元素的类型array_name表示数组名size1、size2直到sizeN表示每一维数组的大小
例:
- 定义一个二维数组 arr,它有 3 行 4 列,元素类型为 int:
int arr[3][4]; - 定义一个三维数组 cube,它有 2 个 3 行 4 列的二维数组,元素类型为 double:
double cube[2][3][4]; - …… 依此类推,可以定义任意维度的数组
二维数组与多维数组
#include <stdio.h>int main() {int arr[3][4]; // 定义一个 3 行 4 列的二维数组// 初始化二维数组的值for (int i = 0; i < 3; i++) { // 遍历行for (int j = 0; j < 4; j++) { // 遍历列arr[i][j] = (i + 1) * (j + 1);}}// 遍历二维数组并输出每个元素的值printf("二维数组的值为:\n");for (int i = 0; i < 3; i++) { // 遍历行for (int j = 0; j < 4; j++) { // 遍历列printf("%d ", arr[i][j]);}printf("\n");}return 0;}/* 运行结果:二维数组的值为:1 2 3 42 4 6 83 6 9 12*/
#include <stdio.h>int main() {int arr[2][3][4] = {{{1, 2, 3, 4},{5, 6, 7, 8},{9, 10, 11, 12}},{{13, 14, 15, 16},{17, 18, 19, 20},{21, 22, 23, 24}}};// 遍历数组for (int i = 0; i < 2; i++) { // 2 层for (int j = 0; j < 3; j++) { // 3 行for (int k = 0; k < 4; k++) { // 4 列printf("%d ", arr[i][j][k]);}printf("\n");}printf("\n");}return 0;}/* 运行结果:1 2 3 45 6 7 89 10 11 1213 14 15 1617 18 19 2021 22 23 24*/
数组初始化时缺省信息
缺省成员:
- 整型数组:缺省初始化为
0 - 字符型数组:缺省初始化为
'\0' - 浮点型数组:缺省初始化为
0.0
缺省长度:会根据实际在赋值时,赋值的成员个数来自动推断数组的长度。
#include <stdio.h>int main() {int arr1[5] = {1, 2, 3}; // 未给出初始值的元素被自动初始化为0int arr2[5] = {0}; // 所有元素都被初始化为0int arr3[5] = {1}; // 第一个元素为1,其他元素被初始化为0int arr4[] = {1, 2, 3, 4, 5}; // 不指定数组长度,根据初始值自动推导数组长度printf("arr1: ");for (int i = 0; i < 5; i++) {printf("%d ", arr1[i]);}printf("\n");printf("arr2: ");for (int i = 0; i < 5; i++) {printf("%d ", arr2[i]);}printf("\n");printf("arr3: ");for (int i = 0; i < 5; i++) {printf("%d ", arr3[i]);}printf("\n");printf("arr4: ");for (int i = 0; i < 5; i++) {printf("%d ", arr4[i]);}printf("\n");return 0;}/* 运行结果:arr1: 1 2 3 0 0arr2: 0 0 0 0 0arr3: 1 0 0 0 0arr4: 1 2 3 4 5*/
这个程序中定义了4个整型数组,分别是 arr1、arr2、arr3 和 arr4,并且分别使用不同的方式进行了初始化。会发现在初始化的时候:
- 如果缺省了初始化成员,那么会自动补零
- 如果初始化的时候没有指定数组的长度,那么会根据我们赋值的成员个数来决定该数组的长度是多少
#include <stdio.h>int main() {int arr[3][4] = {{1, 2}, {4}, {5, 6, 7}};// 打印二维数组中的元素printf("arr:\n");for (int i = 0; i < 3; i++) {for (int j = 0; j < 4; j++) {printf("%d ", arr[i][j]);}printf("\n");}return 0;}/* 运行结果:arr:1 2 0 04 0 0 05 6 7 0*/
Q:初始化二维数组的时候可以省略列数嘛?
不可以
- 在定义二维数组时,可以省略行数,但必须指定列数。
- 原因:在初始化二维数组时,如果省略列数,则编译器无法确定每一行的元素个数,因此不能够正确地分配存储空间。
- 在初始化数组的时候,如果我们能够明确数组的结构,最好不要省略,一开始就写清楚。
使用 sizeof 计算数组的长度
计算公式:
#include <stdio.h>int main() {int arr[5] = {1, 2, 3, 4, 5};int size = sizeof(arr);int length = sizeof(arr) / sizeof(int);printf("数组 arr 占用的存储空间为 %d 字节\n", size);printf("数组 arr 的长度为 %d\n", length);return 0;}/* 运行结果:数组 arr 占用的存储空间为 20 字节数组 arr 的长度为 5*/
#include <stdio.h>int main() {int arr[3][4];// 计算数组占用的存储空间大小size_t arr_size = sizeof(arr);printf("数组的大小为 %lu 字节。\n", arr_size);// 计算每个元素占用的存储空间大小size_t elem_size = sizeof(arr[0][0]);printf("每个元素占用 %lu 字节。\n", elem_size);// 计算数组中元素的个数size_t num_elems = arr_size / elem_size;printf("数组中包含 %lu 个元素。\n", num_elems);return 0;}/* 运行结果:数组的大小为 48 字节。每个元素占用 4 字节。数组中包含 12 个元素。*/
使用一维数组字面量给二维数组初始化
#include <stdio.h>int main() {int arr[][3] = {1, 2, 3, 4, 5, 6, 7};const int ROWS = sizeof(arr) / sizeof(arr[0]);const int COLS = sizeof(arr[0]) / sizeof(int);for (int i = 0; i < ROWS; i++) {for (int j = 0; j < COLS; j++) {printf("%d ", arr[i][j]);}printf("\n");}printf("数组有 %d 行,%d 列。\n", ROWS, COLS);return 0;}/* 运行结果:1 2 34 5 67 0 0数组有 3 行,3 列。*/
int arr[][3] = {1, 2, 3, 4, 5, 6, 7};
- 这行代码的作用是定义了一个 3 行 3 列的二维数组,并对其中的元素进行了初始化,缺省位自动补零。
- 列:这行代码定义了一个二维数组 arr,它有两个维度,第一个维度未指定大小,第二个维度(列)为 3。
- 行:由于第一个维度未指定大小,编译器会根据初始化列表中提供的元素个数自动计算出数组的行数,这里的初始化列表中提供了 7 个元素,所以第一个维度(行)的大小被自动计算为 3(向上取整,确保所有成员都能装下)。
存储空间:
sizeof(arr)整个 arr 数组的存储空间sizeof(arr[0])一行中所有成员的存储空间sizeof(int)、sizeof(arr[0][0])一个成员的存储空间
string.h 中常见的字符串处理函数
string.h 库中提供了很多常用的 字符串处理函数,下面列举一些常用的函数及其功能:
**strlen()**函数:用于求一个字符串的长度。**strcpy()**函数:用于将一个字符串复制到另一个字符串中。**strcat()**函数:用于将一个字符串拼接到另一个字符串的尾部。**strcmp()**函数:用于比较两个字符串是否相等。strncpy()函数:用于将一个字符串的一部分复制到另一个字符串中。strncat()函数:用于将一个字符串的一部分拼接到另一个字符串的尾部。strncmp()函数:用于比较两个字符串的前 n 个字符是否相等。strchr()函数:用于在一个字符串中查找指定字符的位置。strrchr()函数:用于在一个字符串中查找指定字符的最后一个位置。strstr()函数:用于在一个字符串中查找指定子字符串的位置。strtok()函数:用于分解一个字符串成为一组子字符串。memset()函数:用于将一段内存赋值为指定的值。memcpy()函数:用于将一段内存复制到另一段内存中。memcmp()函数:用于比较两段内存是否相等。
这些字符串处理函数大多数都比较常用,并且都是标准 C 库函数,使用起来非常方便。
注意:
- 在使用这些函数的过程中,需要注意参数的类型和数量,以及要处理的字符串的长度和结尾符等因素。
- 在使用这些函数时,应该注意避免出现内存泄漏、缓冲区溢出等问题,并将代码编写得简洁、高效、易于维护。
用于输出字符、字符串的格式控制字符%c、%s
%c:用于输出单个字符。%s:用于输出一个字符串。
字符串和字符数组之间的关系
问:字符串是字符数组?
答:是的
字符串本质上就是一串以空字符 **'\0'** 结尾的一组字符序列,因此可以使用字符数组来存储和操作字符串。
问:字符数组是字符串?
答:不一定
得看字符数组的结尾字符是不是空字符 '\0'
- 如果结尾字符是
'\0'那么可以将这个字符数组视作一个字符串 - 如果结尾字符不是
'\0'那么该字符数组就不是一个字符串
字符数组是由一组字符组成的数组,每个字符占用一个字节的存储空间,结尾字符不一定是空字符 **'\0'**。
strlen
函数声明:size_t strlen(const char *s);
const char *s是一个指向字符型(即字符串)的指针,表示待计算长度的字符串size_t是一个无符号整数类型,用于表示字符串的长度
#include <stdio.h>#include <string.h>int main() {char str[] = "Hello";size_t len = strlen(str);printf("字符串的长度为 %lu。\n", len);return 0;}/* 运行结果:字符串的长度为 5。*/
char str[] = "Hello";、char str[] = {'H', 'e', 'l', 'l', 'o', '\0'}; 两种写法是等效的。
#include <stdio.h>#include <string.h>int main() {char str[] = {'H', 'e', 'l', 'l', 'o', '\0'};size_t len = strlen(str);printf("字符串的长度为 %lu。\n", len);return 0;}/* 运行结果:字符串的长度为 5。*/
strlen 的返回结果依旧是 5,可见 '\0' 结尾字符并不会被计入长度。
#include <stdio.h>#include <string.h>int main() {char str[] = {'H', 'e', 'l', '\0', 'l', 'o', '\0'};size_t len = strlen(str);printf("字符串的长度为 %lu。\n", len);return 0;}/* 运行结果:字符串的长度为 3。*/
如果字符串中包含 '\0' 字符,strlen 函数会返回 '\0' 字符前的字符数
注意:
- strlen 函数的参数必须是一个以
'\0'结尾的字符串,否则行为是未定义的 - 如果字符串中包含
'\0'字符,strlen 函数会返回'\0'字符前的字符数 - strlen 函数计算字符串长度时,不包括
'\0'终止符 - 如果传递给 strlen 函数的指针是空指针
null,则会引发未定义的行为
strcpy
- 函数声明:
char *strcpy(char *dest, const char *src); dest目标字符串src源字符串- 用于将源字符串 src 复制到目标字符串 dest 中,并返回目标字符串的指针。
- dest 指向的字符串必须具有足够的空间来存放 src 中的所有字符,包括字符串结束符 \0。否则,strcpy() 函数可能会导致缓冲区溢出,从而破坏程序的内存空间。
#include <stdio.h>#include <string.h>int main() {char src[] = "hello world";char dest[20];printf("调用 strcpy 之前:\n");printf("src = [%s]\n", src);printf("dest = [%s]\n", dest);strcpy(dest, src);printf("调用 strcpy 之后:\n");printf("src = [%s]\n", src);printf("dest = [%s]\n", dest);return 0;}/* 运行结果:调用 strcpy 之前:src = [hello world]dest = []调用 strcpy 之后:src = [hello world]dest = [hello world]*/
strcat
- 函数声明:
char *strcat(char *dest, const char *src); dest目标字符串src源字符串- 作用:将源字符串 src 拼接到目标字符串 dest 的末尾
- 返回:指向 dest 的指针
#include <stdio.h>#include <string.h>int main() {char str1[10] = "Hello, ";char str2[] = "world!";printf("[%s] 的长度是:%lu\n", str1, strlen(str1));strcat(str1, str2);printf("[%s] 的长度是:%lu\n", str1, strlen(str1));return 0;}/* 运行结果:[Hello, ] 的长度是:7[Hello, world!] 的长度是:13*/
尽管最终的结果是符合我们预期的,但是上述代码是存在问题的。
因为 str1 只有 10 个字符的空间,但是将 "Hello, " 和 "world!" 两个字符串拼接在一起后会超过这个空间,从而导致未定义的行为。
补充:虽然结果是符合预期的,看似也没出现什么问题,这主要是因为我们的程序规模小,总共就这么几行代码,所以破坏一些内存结构也不会出现什么问题。如果规模大了,这种做法会导致一些内存中存储的数据被抹掉,后果是不堪设想的。
为了修复这个问题,需要将 str1 的空间扩大到足够容纳两个字符串拼接后的结果。
#include <stdio.h>#include <string.h>int main() {char str1[20] = "Hello, ";char str2[] = "world!";printf("[%s] 的长度是:%lu\n", str1, strlen(str1));strcat(str1, str2);printf("[%s] 的长度是:%lu\n", str1, strlen(str1));return 0;}/* 运行结果:[Hello, ] 的长度是:7[Hello, world!] 的长度是:13*/
strcmp
- 函数声明:
int strcmp(const char *s1, const char *s2); - 作用:用于比较两个字符串的大小
- 返回值:
strcmp()函数会逐个比较两个字符串中的字符,直到出现不同字符或字符串结束符为止。当出现不同字符时,函数会根据字符的 ASCII 码或 Unicode 码将两个字符做差,并将差作为比较结果返回。- 如果 s1 小于 s2,则返回值为 负数
- 如果 s1 等于 s2,则返回值为 零
- 如果 s1 大于 s2,则返回值为 正数
#include <stdio.h>#include <string.h>int main() {char s1[] = "world";char s2[] = "hello";char s3[] = "world";int result1, result2, result3;result1 = strcmp(s1, s2); // 将较大的字符串排在前面,返回正整数result2 = strcmp(s2, s3); // 将较小的字符串排在前面,返回负整数result3 = strcmp(s1, s3); // 两个字符串相同,返回0printf("result1 = %d\n", result1);printf("result2 = %d\n", result2);printf("result3 = %d\n", result3);return 0;}/* 运行结果:result1 = 15result2 = -15result3 = 0*/
从上述结果来看,可以得出以下公式:
至于为何是首字母,主要是因为第一个字母就是不同的字符。
#include <stdio.h>#include <string.h>int main() {printf("'b' - 'a' = %d\n", 'b' - 'a');printf("'a' - 'b' = %d\n", 'a' - 'b');printf("'w' - 'h' = %d\n", 'w' - 'h');printf("'h' - 'w' = %d\n", 'h' - 'w');return 0;}/* 运行结果:'b' - 'a' = 1'a' - 'b' = -1'w' - 'h' = 15'h' - 'w' = -15*/
#include <stdio.h>#include <string.h>int main() {printf("strcmp(\"abc\", \"aaa\") = %d\n", strcmp("abc", "aaa"));printf("strcmp(\"aaa\", \"aba\") = %d\n", strcmp("aaa", "aba"));printf("strcmp(\"abc\", \"aba\") = %d\n", strcmp("abc", "aba"));printf("strcmp(\"abb\", \"aba\") = %d\n", strcmp("abb", "aba"));printf("strcmp(\"ab\", \"aba\") = %d\n", strcmp("ab", "aba"));return 0;}/* 运行结果:strcmp("abc", "aaa") = 1strcmp("aaa", "aba") = -1strcmp("abc", "aba") = 1strcmp("abb", "aba") = 1strcmp("ab", "aba") = -1*/
结合 strcmp 的功能描述,我们得知它的返回值应该是:“两个字符串第一个不同字符的 ASCII 码值之差。”
但是,实际的测试结果可能与描述不符:
- 符合预期
strcmp("abc", "aaa") = 1- 比较到下标为 1 的位置,发现了第一个不同的字符
- str1 在该位置的字符是
'b' - str2 在该位置的字符是
'a' - 最终返回值是
'b' - 'a'也就是1
- 不符合预期
strcmp("abc", "aba") = 1- 比较到下标为 2 的位置,发现了第一个不同的字符
- str1 在该位置的字符是
'c' - str2 在该位置的字符是
'a' - 最终返回值是
'c' - 'a'也就是2但是实际返回的是1
不过无论如何,自测下来,结果的正负号是没有问题的
- 如果 s1 小于 s2,则返回值为 负数
- 如果 s1 等于 s2,则返回值为 零
- 如果 s1 大于 s2,则返回值为 正数
字符数组初始化的多种方式
#include <stdio.h>#include <string.h>int main() {// 直接初始化,这种做法,编译器会自动为我们在字符串的最后追加一个 '\0' 结尾符。char str1[] = "Hello, world!";// 使用 strcpy 函数初始化char str2[20];strcpy(str2, str1);char str3[20];strcpy(str3, "Hello, world!");// 逐个赋值,需要手动添加结尾的结束符 '\0' 【容易出错,不建议使用】char str4[20];for (int i = 0; i <= 12; i++) {str4[i] = "Hello, world!"[i];}str4[13] = '\0';char str5[20];for (int i = 0; i <= strlen(str1); i++) {str5[i] = str1[i];}str5[13] = '\0';printf("str1: %s\n", str1);printf("str2: %s\n", str2);printf("str3: %s\n", str3);printf("str4: %s\n", str4);printf("str5: %s\n", str5);return 0;}/* 运行结果:str1: Hello, world!str2: Hello, world!str3: Hello, world!str4: Hello, world!str5: Hello, world!*/
注意:
- 保证字符数组足够长
- 注意结尾符的问题
gets、fgets
- gets 函数声明:
char *gets(char *str); - 作用:
gets()函数用于从标准输入设备(例如键盘)获取一行字符串,并将该字符串存储到指定的字符数组str中。 - 注意:
gets()函数 不进行缓冲区溢出检查,因此容易出现安全问题,因此 C11 已将该函数标记为过时。- 通常应该尽量使用安全的输入函数,例如
fgets()函数。
- fgets 函数声明:
char *fgets(char *str, int size, FILE *stream); - 作用:同 gets 函数
- 参数:
str是一个字符数组指针,用于存储读取到的字符串;size是一个整型变量,指定字符数组的最大容量;stream是一个文件指针,指定从哪个流(例如标准输入、文件等)中读取数据;
- 返回值:
- 如果读取成功,则会返回读取到的字符串指针
- 如果读取失败,返回 NULL
- 注意:
fgets()函数会把换行符也读入字符串中,因此需要在字符串末尾去掉换行符if (str[strlen(str) - 1] == '\n') { str[strlen(str) - 1] = '\0'; }
#include <stdio.h>int main() {char str[100];printf("请输入一行字符串:");fgets(str, 100, stdin);printf("你输入的是:%s\n", str);return 0;}/* 运行结果:请输入一行字符串:hello world! 123 abc你输入的是:hello world! 123 abc*/
error: use of undeclared identifier ‘gets’
由于直接使用 gets 出现了报错 error: use of undeclared identifier 'gets'
这个错误提示是因为使用了 C 语言标准库函数 gets(),但是在较新的 C 语言标准(C11 及之后的版本)中,gets() 函数已被废弃,不再被推荐使用。因此,在使用较新的编译器时,编译器会给出警告或错误提示。
推荐使用较新的函数 fgets() 来代替 gets(),fgets() 具有更好的安全性和可控性,使用方法类似,例如:
fgets(str, sizeof(str), stdin);
sizeof(str) 表示字符数组 str 的大小stdin 表示标准输入流,即从控制台获取用户输入
注意:fgets() 函数会把换行符也读入字符串中,因此需要在字符串末尾去掉换行符。可以使用以下代码去掉换行符:
if (str[strlen(str) - 1] == '\n') {str[strlen(str) - 1] = '\0';}
补充:有关
fgets的更多内容,在介绍后续知识点时还会详细说明……
puts
- 函数声明:
int puts(const char *str); - 作用:用于将一个字符串输出到标准输出设备(例如屏幕)该函数会自动在字符串的末尾添加换行符
\n,从而保证输出格式的正确性。 - 注意:
puts()函数不会检查字符串是否超出了缓冲区长度- 在使用该函数输出字符串时,需要确保字符串长度不会超过目标缓冲区的长度
- 如果需要更加安全的字符串输出函数,可以使用
printf()或fwrite()函数。
#include <stdio.h>int main() {char str[] = "Hello, world!";puts(str);return 0;}/* 运行结果:Hello, world!*/
字符串的结束标志
'\0'
4.1.5 练习 | 寻找 James
需求:查找以 James 开头的人名。
#include <stdio.h>#include <stdlib.h>#include <string.h>int main() {const int n = 20, m = 5;char name[][n] = {"Kate.Wate", "James.Tan", "Bull.Ben","Jimes.Tide", "James.Ting", "K.James.T"};char James[] = "James";int i, j, len = strlen("James");for (i = 0; i < m; ++i) {for (j = 0; j < len; ++j) {if (name[i][j] != James[j])break;}if (j == len) {printf("%s has James\n", name[i]);}}return 0;}/* 运行结果:James.Tan has JamesJames.Ting has James*/
扩展:查找名字中含有 James 的成员。
提示:可以使用 strcmp 函数来比较,如果匹配上子串 James 那么将返回 0
#include <stdio.h>#include <string.h>int main() {const int MAX_LEN = 20;const char SUBSTR[] = "James";const int SUBSTR_LEN = strlen(SUBSTR);char name[][MAX_LEN] = {"Kate.Wate", "James.Tan", "Bull.Ben","Jimes.Tide", "James.Ting", "K.James.T"}; // name 相当于一个二维数组const int num_names = sizeof(name) / sizeof(name[0]); // 一共多少个名字for (int i = 0; i < num_names; i++) {int name_len = strlen(name[i]);for (int j = 0; j < name_len - SUBSTR_LEN + 1; j++) {if (strncmp(&name[i][j], SUBSTR, SUBSTR_LEN) == 0) {printf("%s has %s\n", name[i], SUBSTR);break;}}}return 0;}/* 运行结果:James.Tan has JamesJames.Ting has JamesK.James.T has James*/
4.2 结构
结构
notes
结构类型
- 结构(Structure)类型是 C 语言中一种 自定义 的 复合 数据类型。
- 结构 将一组相关的变量看作一个存储单元,而不是各自独立的实体
- 结构有助于组织复杂的数据
struct是用于定义结构体的关键字- 通过
struct关键字可以将多个变量打包为一个复合类型的数据结构,方便对这些变量进行管理和维护
struct 关键字的语法格式:
struct structure_name {member_type1 member_name1;member_type2 member_name2;...member_typeN member_nameN;} struct_instance;
structure_name表示结构体的名称。member_type1、member_type2、……、member_typeN表示结构体的成员类型。member_name1、member_name2、……、member_nameN表示结构体的成员名称。struct_instance是结构体的实例(或称对象),用于在程序中创建并操作结构体。

定义一个学生结构,要求该结构中存放学生的 id、姓名 name、分数 score
#include <stdio.h>#include <string.h>// 定义结构体struct Student {int id;char name[20];float score;} stu;int main() {// 写 | 接头体实例 stu 中的成员stu.id = 1000;strcpy(stu.name, "Alice");stu.score = 95.5;// 读 | 结构体实例 stu 中的成员printf("学生信息:\n");printf("学号:%d\n", stu.id);printf("姓名:%s\n", stu.name);printf("分数:%.1f\n", stu.score);return 0;}/* 运行结果:学生信息:学号:1000姓名:Alice分数:95.5*/
在上述代码中,我们使用 struct 关键字定义了一个名为 Student 的结构体,其中包含三个成员变量:
id表示学号name表示姓名score表示分数
在 main() 函数中,我们声明了一个结构体实例 stu,通过 . 运算符为结构体的成员赋值,并输出了结构体实例的信息。
结构体初始化的多种方式
#include <stdio.h>struct {int id;char name[20];float score;} stu = {1001, "Alice", 95.5};// 定义了一个 匿名结构体,并在定义时即可完成成员变量的初始化,然后将其赋给了 stu。int main() {printf("学生信息:\n");printf("学号:%d\n", stu.id);printf("姓名:%s\n", stu.name);printf("分数:%.1f\n", stu.score);return 0;}/* 运行结果:学生信息:学号:1000姓名:Alice分数:95.5*/
#include <stdio.h>//定义结构体struct Student {int id;char name[20];float score;} stu = { .id = 1000, .name = "Alice", .score = 95.5 };// 使用成员初始化列表的方式,直接为结构体成员变量分别指定初始值,其中使用了点 . 运算符引用结构体成员变量。int main() {printf("学生信息:\n");printf("学号:%d\n", stu.id);printf("姓名:%s\n", stu.name);printf("分数:%.1f\n", stu.score);return 0;}/* 运行结果:学生信息:学号:1000姓名:Alice分数:95.5*/
#include <stdio.h>struct Student {int id;char name[20];float score;};struct Student stu = {1001, "Alice", 95.5};// 我们使用 {} 直接给结构体成员变量赋值,在定义结构体实例 stu 时即可完成初始化。int main() {printf("学生信息:\n");printf("学号:%d\n", stu.id);printf("姓名:%s\n", stu.name);printf("分数:%.1f\n", stu.score);return 0;}/* 运行结果:学生信息:学号:1000姓名:Alice分数:95.5*/
#include <stdio.h>//定义结构体struct Student {int id;char name[20];float score;};struct Student temp = {1000, "Alice", 95.5};struct Student stu = temp;// 先定义了一个名为 temp 的结构体变量,并给其成员变量赋值,然后将 temp 的值赋给了 stu,实现了 stu 的初始化。int main() {printf("学生信息:\n");printf("学号:%d\n", stu.id);printf("姓名:%s\n", stu.name);printf("分数:%.1f\n", stu.score);return 0;}/* 运行结果:学生信息:学号:1000姓名:Alice分数:95.5*/
结构体的拷贝
- 数组无法直接拷贝:前面我们学习过数组,知道数组名表示的是数组的首地址,是一个不可改变的常量,所以即便是对于同类型的数组,我们也没法通过数组名来直接完成拷贝。
- 结构体可以直接拷贝:在结构体中,同类型的结构体之间是可以允许直接赋值的。
#include <stdio.h>//定义结构体struct Student {int id;char name[20];float score;};struct Student temp = {1000, "Alice", 95.5};struct Student stu = temp;int main() {// 不同结构体之间的数据互不影响temp.score++;stu.id = 1001;printf("stu 学生信息:\n");printf("学号:%d\n", stu.id);printf("姓名:%s\n", stu.name);printf("分数:%.1f\n", stu.score);printf("temp 学生信息:\n");printf("学号:%d\n", temp.id);printf("姓名:%s\n", temp.name);printf("分数:%.1f\n", temp.score);return 0;}/* 运行结果:stu 学生信息:学号:1001姓名:Alice分数:95.5temp 学生信息:学号:1000姓名:Alice分数:96.5*/
注意:
- 类型要求相同:同类型的结构体可以直接拷贝,拷贝时会将结构体的所有成员逐一复制到目标结构体中
- 指针共享问题:如果结构体中包含指针成员,直接拷贝可能会导致指针指向的内存地址被多个结构体共享,从而产生潜在的问题
课件题目 | 录入学生信息,并根据语文成绩降序
请帮老师写一个程序,要求存储本年级 100 个学生的姓名,学号,语文,数学,外语三门课程成绩,并 根据语文成绩递减排序,按名次输出所有学生信息。
100 个太多了些,先输 4 个意思意思就好……
#include <stdio.h>#include <stdlib.h>const int n = 4, m = 20;typedef struct student {char name[m];int id;float chinese;float english;float math;} student;int main() {student s[n], tmp;int i, max, j;for (i = 0; i < n; ++i)scanf("%s%d%f%f%f", s[i].name, &s[i].id, &s[i].chinese, &s[i].english,&s[i].math);for (i = 0; i < n; ++i) {max = i;for (j = i + 1; j < n; ++j)if (s[j].chinese > s[max].chinese)max = j;tmp = s[i];s[i] = s[max];s[max] = tmp;}for (i = 0; i < n; ++i)printf("%s %d %.2f %.2f %.2f\n", s[i].name, s[i].id, s[i].chinese,s[i].english, s[i].math);}/* 运行结果:张三 1 87 45 90李四 2 100 44 92王五 3 34 66 87wu 4 72 89 78李四 2 100.00 44.00 92.00张三 1 87.00 45.00 90.00wu 4 72.00 89.00 78.00王五 3 34.00 66.00 87.00*/

若有收获,就点个赞吧
0 人点赞
