4.3 编程实战
求1到100之间的所有素数

冒泡排序
折半查找
兔子问题
时钟
数据分析
notes
常规法子 | 求 1 到 100 之间的所有素数
#include <stdio.h>int main() {int i, j, is_prime;for (i = 2; i <= 100; i++) {is_prime = 1; // 假设 i 是素数for (j = 2; j < i; j++) {if (i % j == 0) { // 如果 i 能被 j 整除,则 i 不是素数is_prime = 0;break;}}if (is_prime) { // 如果 i 是素数,则打印出来printf("%d ", i);}}printf("\n");return 0;}/* 运行结果:2 3 5 7 11 13 17 19 23 29 31 37 41 43 47 53 59 61 67 71 73 79 83 89 97*/
埃氏筛法(Sieve of Eratosthenes) | 4.3.1 视频结尾提到的优化解法 | 求 1 到 100 之间的所有素数
埃氏筛法(Sieve of Eratosthenes)是一种用于求解素数的算法,它的基本思想是:从 2 开始,将每个素数的倍数标记为合数,直到遍历到给定的范围为止。
#include <stdio.h>#define N 100int main() {int i, j, is_prime[N + 1];// 初始化数组for (i = 2; i <= N; i++) {is_prime[i] = 1; // 假设所有数都是素数}// 标记合数for (i = 2; i <= N; i++) {if (is_prime[i]) { // 如果 i 是素数for (j = i * 2; j <= N; j += i) {is_prime[j] = 0; // 标记 i 的倍数为合数}}}// 输出素数for (i = 2; i <= N; i++) {if (is_prime[i]) {printf("%d ", i);}}printf("\n");return 0;}/* 运行结果:2 3 5 7 11 13 17 19 23 29 31 37 41 43 47 53 59 61 67 71 73 79 83 89 97*/
解释:
#define N 100在上面的示例中,我们首先定义了一个常量 N,表示要求解的范围为从 2 到 N 的所有素数。int is_prime[N + 1];然后,我们定义了一个名为 is_prime 的 布尔数组,用于记录每个数是否为素数。is_prime[i] = 1;在初始化数组时,我们将所有的数都假设为素数。is_prime[j] = 0;接着,我们从 2 开始遍历数组,如果遇到素数,则将它的倍数标记为合数,这里我们可以直接从 i 的倍数开始,因为它们已经被之前的素数标记为合数了。最后,我们输出未被标记为合数的数即为素数。
注意:
- 这种方法虽然效率比较高,但是需要额外的空间来记录每个数是否为素数
- 如果要求解比较大的范围的素数,可能需要使用更高效的算法或者优化算法的实现
算法思想的核心:找出 1-N 中所有非素数,剩下的就都是素数了。
#include <math.h>#include <stdio.h>int main() {const int n = 100;int isPrim[n] = {0}; // 默认所有数是非素数int i, j;for (i = 2; i < sqrt(n); ++i) {if (isPrim[i] == 0)for (j = 2 * i; j <= n; j += i)isPrim[j] = 1; // 将每个素数的倍数标记为合数}for (i = 2; i <= n; ++i)if (isPrim[i] == 0) {printf("%d ", i);}return 0;}/* 运行结果:2 3 5 7 11 13 17 19 23 29 31 37 41 43 47 53 59 61 67 71 73 79 83 89 97*/
欧拉筛法(Sieve of Euler) | 求 1 到 100 之间的所有素数
欧拉筛法的基本思想是:对于每个合数(即非素数),只会在最小质因子筛选时被筛掉,在后续的枚举过程中不会再次被筛选。因此,在筛质数时,只需要考虑每个数的最小质因子,即第一个能整除它的质数。
欧拉筛法的基本步骤:
- 初始化:先将所有数标记为素数(或者不标记任何数),并且保留每个数的最小质因数,和一个素数列表 primes。
- 筛除合数:从 2 开始逐个枚举每个数,如果这个数是素数,则将其添加到素数列表 primes 中,并标记其倍数为合数,并记录这个合数的最小质因子,如果这个数的最小质因子就是它本身,则跳过。
- 输出结果:最终得到的素数列表即为筛选出的所有质数。
#include <stdio.h>#include <stdbool.h>#define MAX_N 100000int primes[MAX_N]; // 存放素数的数组bool is_prime[MAX_N]; // 标志数组:判断某个数是否为素数int num_primes = 0; // 当前素数的个数// 欧拉筛法void euler_sieve(int n) {is_prime[0] = is_prime[1] = false; // 标记 0 和 1 不为素数for (int i = 2; i <= n; i++) {if (is_prime[i] == true) {primes[num_primes++] = i;}for (int j = 0; j < num_primes && i * primes[j] <= n; j++) {is_prime[i * primes[j]] = false;if (i % primes[j] == 0) break; // 如果 i 除以当前素数得到余数为 0,说明 i 的最小质因子为 primes[j],因此跳出循环}}}int main() {int n = 100;for (int i = 0; i <= n; i++) {is_prime[i] = true; // 默认所有数一开始都是素数}euler_sieve(n);for (int i = 0; i < num_primes; i++) {printf("%d ", primes[i]);}return 0;}
冒泡排序
冒泡排序是一种简单、直观的排序算法,其基本思想是 将要排序的元素按照大小关系进行比较并交换,每一次遍历可以找到待排序序列中最大或最小的元素,重复这个过程直到整个序列有序。
冒泡排序的时间复杂度是O(n^2),它虽然简单易懂,但对于大规模数据的排序效率较低,不适合大规模数据的排序。
下面是冒泡排序的伪代码:
- 初始化:设待排序元素的数列为
a[1], a[2], ..., a[N]。 - 外循环:从第一个元素开始,依次比较相邻两个元素的大小,如果前一个元素比后一个元素大(或小,根据实际需求而定),则交换这两个元素的位置。依次遍历整个数列,最终得到最大(或最小)的元素,放置在数列的末尾(或开头)。
- 内循环:继续从第一个元素开始,重复第2步,但这次不再包括最后一个元素。重复这个过程,直到整个数列有序。
- 输出结果:最终得到的有序数列即为排序结果。
冒泡排序流程示意图: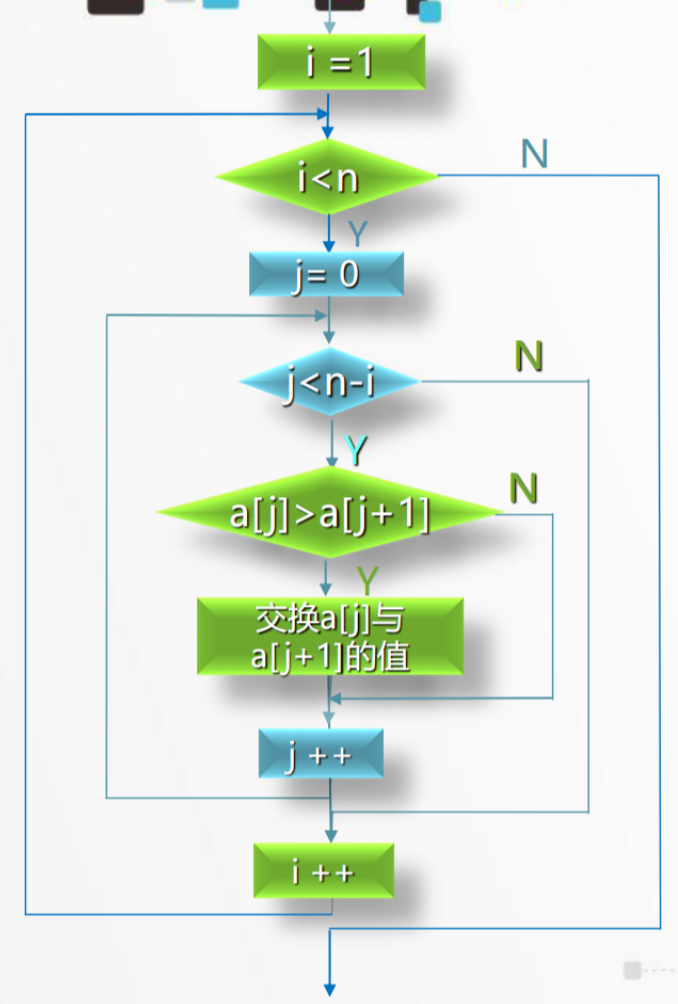
#include <stdio.h>int main() {int a[6] = {16, 8, 4, 32, 5, 9};int temp;for (int i = 1; i < 6; ++i)for (int j = 0; j < 6 - i; j++)if (a[j] > a[j + 1]) {temp = a[j];a[j] = a[j + 1];a[j + 1] = temp;}for (int i = 0; i <= 5; i++)printf("%d ", a[i]);return 0;}/* 运行结果:4 5 8 9 16 32*/
#include <stdio.h>void bubble_sort(int a[], int n) {int i, j, temp;for (i = 0; i < n - 1; i++) { // 外循环for (j = 0; j < n - 1 - i; j++) { // 内循环if (a[j] > a[j + 1]) { // 如果前一个值比后一个值大,则交换它们的位置temp = a[j];a[j] = a[j + 1];a[j + 1] = temp;}}}}int main() {int a[5] = {16, 8, 4, 32, 5};int i;bubble_sort(a, 5);for (i = 0; i < 5; i++) {printf("%d ", a[i]);}return 0;}/* 运行结果:4 5 8 16 32*/
i < n - 1 外循环
- 在外循环中,我们依次遍历整个数列,每次找到一个最大的元素,并将其放到数组的后面;
- 外层循环每跑一趟,确定一个最值,一共要跑 n-1 趟
- 以 5 个数
{16, 8, 4, 32, 5}为例,一共需要跑 4 趟,即可确保数组是有序的 i == 0第 1 趟确定第 1 大的值 32,并将其丢到数组的倒数第 1 个位置i == 1第 2 趟确定第 2 大的值 16,并将其丢到数组的倒数第 2 个位置i == 2第 3 趟确定第 3 大的值 8,并将其丢到数组的倒数第 3 个位置i == 3第 4 趟确定第 4 大的值 5,并将其丢到数组的倒数第 4 个位置
- 以 5 个数
j < n - 1 - i 内循环
- 在内循环中,我们对相邻的元素进行比较,如果前一个元素比后一个元素大,则交换它们的位置,直到找到最大的元素;
- 内层循环,每跑一趟,比较一对数据,根据此时已经明确的最值数量,决定需要跑多少趟
- 以 5 个数
{16, 8, 4, 32, 5}为例 i == 0时,明确的最值数量为 0,此时需要把前面的 5 个数都比较一遍,共比较 4 次i == 1时,明确的最值数量为 1,此时需要把前面的 4 个数都比较一遍,共比较 3 次i == 2时,明确的最值数量为 2,此时需要把前面的 3 个数都比较一遍,共比较 2 次i == 3时,明确的最值数量为 3,此时需要把前面的 2 个数都比较一遍,共比较 1 次
- 以 5 个数
#include <stdio.h>void bubble_sort(int a[], int n) {int i, j, temp;int flag = 1; // 标志变量 flag,初始值为 truefor (i = 0; i < n - 1 && flag == 1; i++) { // 外循环flag = 0; // 每次循环开始时,将 flag 设为 falsefor (j = 0; j < n - 1 - i; j++) { //内循环if (a[j] > a[j + 1]) { // 如果前一个值比后一个值大,则交换它们的位置temp = a[j];a[j] = a[j + 1];a[j + 1] = temp;flag = 1; // 如果进行了交换操作,将 flag 设为 true}}}}int main() {int a[5] = {16, 8, 4, 32, 5};int i;bubble_sort(a, 5);for (i = 0; i < 5; i++) {printf("%d ", a[i]);}return 0;}/* 运行结果:4 5 8 16 32*/
核心:加标记,判断后续的交换是否有必要进行,以减少交换次数。
如果某一次的内层循环跑完,都没有发生两数交换的情况,那么意味着:
- 该数组已经处于有序状态,此时就没有必要再进行后续的比较了。
flag = 1;这条语句将不会被执行,flag的值将保持为0,外层循环条件不满足,直接结束后续的所有流程。
折半查找(二分查找)
- 折半查找(Binary Search),也被称为 二分查找,是一种常用的查找算法。
- 核心思想:将待查找的元素与已知的中间元素进行比较,从而逐步缩小查找范围,最终找到待查元素所在的位置。
- 前提:待查找的序列必须有序
这里我们假设序列是升序排列的,下面是折半查找具体的实现步骤:
- 初始化:设待查找元素为 x,数组名为 a,开始时,设置左右两个游标 left 和 right,分别指向数组左右两端,即 left = 0,right = n - 1。
- 折半查找:在每一次查找时:
- 计算中间元素的位置 mid
mid = (left + right) / 2
- 将 x 与 a[mid] 进行比较
- 如果 x 等于 a[mid],则找到了要查找的元素
- 如果 x 大于 a[mid],则表明要查找的元素在
[mid + 1, right]的区间内,更新left = mid + 1 - 如果 x 小于 a[mid],则表明要查找的元素在
[left, mid - 1]的区间内,更新right = mid - 1
- 计算中间元素的位置 mid
- 结束查找:当 left > right 时,表明数组中不存在 x,查找结束。
#include <stdio.h>int main() {int data[10] = {23, 37, 45, 54, 65, 78, 82, 87, 89, 94};int target = 88;int len = sizeof(data) / sizeof(data[0]), low = 1, high = len, mid;mid = (low + high) / 2;while (low <= high) {if (data[mid] == target) {printf("数组中 %d 的下标是 %d\n", target, mid);return 0;} else if (data[mid] > target) {high = mid - 1;} else {low = mid + 1;}mid = (low + high) / 2;}printf("数组中不存在 %d\n", target);return 0;}/* 运行结果:数组中不存在 88*/#include <stdio.h>int main() {int data[10] = {23, 37, 45, 54, 65, 78, 82, 87, 89, 94};int target = 78;int len = sizeof(data) / sizeof(data[0]), low = 1, high = len, mid;mid = (low + high) / 2;while (low <= high) {if (data[mid] == target) {printf("数组中 %d 的下标是 %d\n", target, mid);return 0;} else if (data[mid] > target) {high = mid - 1;} else {low = mid + 1;}mid = (low + high) / 2;}printf("数组中不存在 %d\n", target);return 0;}/* 运行结果:数组中 78 的下标是 5*/
#include <stdio.h>int binary_search(int a[], int n, int x) {int left = 0, right = n - 1; // 定义左右两个游标while (left <= right) { // 只要游标没有相撞,就不断查找int mid = (left + right) / 2; // 计算中间位置if (a[mid] == x) // 找到了return mid;else if (a[mid] > x) // 中间值 > 目标元素right = mid - 1; // 说明目标元素位于 左 侧的区间中 [ left, mid - 1 ]else // 中间值 <= 目标元素left = mid + 1; // 说明目标元素位于 右 侧的区间中 [ mid + 1, right ]}return -1;}int main() {int a[8] = {1, 3, 4, 6, 8, 9, 11, 13};int n = sizeof(a) / sizeof(a[0]); // 计算数组长度int x = 6; // 查找的目标成员int index = binary_search(a, n, x);if (index == -1)printf("数组中不存在%d\n", x);elseprintf("数组中 %d 的下标是 %d\n", x, index);return 0;}/* 运行结果:数组中 6 的下标是 3*/
求 Fibonacci 数
问:什么是 Fibonacci 数?
- 第 1 个数为 1
- 第 2 个数为 1
- 头两个数为 1
- 第 3 个数为 2
- 从第三个数开始,每个数等于前两数之和
- 第 4 个数为 3
- 第 5 个数为 5
- 第 6 个数为 8
- 第 7 个数为 13
- 第 8 个数为 21
- 第 9 个数为 34
- ……
#include <stdio.h>int main() {const int n = 10;int f[n], i;f[1] = 1;f[2] = 1;printf("%4d%4d", f[1], f[2]);for (i = 3; i < n; i++) {f[i] = f[i - 1] + f[i - 2];printf("%4d", f[i]);}return 0;}/* 运行结果:1 1 2 3 5 8 13 21 34*/
课件中的这种做法,使用到了数组类型,相当于将每一项的值都给存下来了,随着值的不断增多,数组中装的成员也将越来越多,需要的空间也会越来越大。
#include <stdio.h>int Fibonacci(int n) {if (n <= 0)return -1; // 输入的数据不合法if (n == 1 || n == 2)return 1; // 当 n 等于 1 或 2 时,斐波那契数为 1return Fibonacci(n - 1) + Fibonacci(n - 2); // 定义递归式,并进行递推}int main() {int n = 10;printf("f(%d) = %d\n", 1, Fibonacci(1));printf("f(%d) = %d\n", 2, Fibonacci(2));for (int i = 3; i < n; i++) {int result = Fibonacci(i);if (result == -1)printf("输入数据不合法!");elseprintf("f(%d) = %d\n", i, result);}return 0;}/* 运行结果:f(1) = 1f(2) = 1f(3) = 2f(4) = 3f(5) = 5f(6) = 8f(7) = 13f(8) = 21f(9) = 34*/
在以上代码中,我们定义了函数 Fibonacci 进行递推求解斐波那契数列的第 n 项值。
- 当输入的 n 小于或等于 0 时,返回 -1,代表输入数据不合法;当 n 等于 1 或 2 时,返回1;
- 当 n 大于等于 3 时,通过递归计算 f(n-1) 和 f(n-2) 的和,并返回结果;
#include <stdio.h>int Fibonacci(int n) {if (n <= 0)return -1; // 输入的数据不合法if (n == 1 || n == 2)return 1; // 当 n 等于 1 或 2 时,斐波那契数为 1int f1 = 1, f2 = 1, f3 = 0;for (int i = 3; i <= n; i++) {f3 = f1 + f2; // 定义递推式f1 = f2;f2 = f3; // 进行向后滚动}return f3;}int main() {int n = 10;printf("f(%d) = %d\n", 1, Fibonacci(1));printf("f(%d) = %d\n", 2, Fibonacci(2));for (int i = 3; i < n; i++) {int result = Fibonacci(i);if (result == -1)printf("输入数据不合法!");elseprintf("f(%d) = %d\n", i, result);}return 0;}/* 运行结果:f(1) = 1f(2) = 1f(3) = 2f(4) = 3f(5) = 5f(6) = 8f(7) = 13f(8) = 21f(9) = 34*/
f1、f2 这两个变量中,始终存放着当前位的前两位的值。假设当前要计算的是 f(x),那么 f1 就是 f(x - 2),f2 就是 f(x - 1)。
清屏
清空屏幕并将光标移动到屏幕左上角
system("CLS")- 是 C 语言中的一个系统函数调用
- 常用来清空屏幕从而让控制台窗口中的输出信息更加清晰易读
- 该函数在 Windows 操作系统中可用
system("clear")Linux 或 Mac 系统中应使用system("clear")函数调用来实现同样的功能<stdlib.h>头文件中包含了 C 语言标准库中的system函数的声明
#include <stdio.h>#include <stdlib.h> // 包含 system 函数的声明int main(){printf("输出一些信息......\n");// system("CLS"); // 清空控制台屏幕system("clear");printf("屏幕清空之后,输出一些其它信息......\n");return 0;}/* 运行结果:屏幕清空之后,输出一些其它信息...... */
时钟题目描述
需求:定义一个时钟结构体类型,然后编程实现将时钟模拟显示在屏幕上
扩展:获取本机当前时间,修改程序,实现实时显示本机当前时间
休眠
Sleep 和 sleep 是两个不同的函数,用于在不同的操作系统中进行程序的休眠。
SleepSleep函数是 Windows 操作系统中的一个函数,定义在 Windows API 中- 用于使当前线程进入指定的时间(以 毫秒 为单位)的休眠状态
- 阻塞当前线程 并 限制系统的 CPU 资源使用
- 在使用时需要包含头文件
<windows.h>
sleepsleep函数是 Linux 或 Unix 操作系统中的一个函数- 可以将当前线程阻塞指定的 秒数
- 在使用时需要包含头文件
<unistd.h>
注意误差问题
Sleep函数的精度会受到系统负载的影响,因此在 Windows 操作系统中,使用Sleep函数进行短时间的休眠时可能会出现误差。sleep函数则并不受到这种影响。同时,Linux 操作系统也提供了usleep函数,它的单位是微秒,同样可以用于实现更准确的程序休眠。
#include <stdio.h>#include <unistd.h>int main() {printf("开始休眠 5s\n");sleep(5); // 休眠 5 秒printf("休眠结束!\n"); // => 这条语句在 5 秒后才会打印return 0;}/* 运行结果:开始休眠 5s休眠结束!*/
缓冲区
缓冲区(Buffer)是 计算机系统中用于存储数据的一段内存空间,用来 临时存放输入/输出数据的中转站,缓解输入/输出设备和计算机之间速度不匹配的问题,提高数据传输的效率。
在计算机系统中,输入/输出设备的速度通常比内存和处理器的速度慢很多,因此当程序需要进行输入/输出操作时,为了提高效率,会先将数据存储到缓冲区中,然后再由系统将缓冲区中的数据传输到输入/输出设备中。这样,输入/输出设备就不需要等待计算机的处理速度,而是可以按照缓冲区中数据的速度进行数据传输,从而提高了系统的性能。
缓冲区在计算机系统中广泛应用,比如在 👇🏻 下面这些场景中都会使用到缓冲区
- 文件读写
- 网络通信
- 视频音频播放
- ……
缓冲区的大小和使用方式都会对系统的性能和效率产生影响,因此在设计和优化系统时,需要考虑缓冲区的大小和使用方式,以达到最优的效果。
刷新缓冲区,将缓冲区中的数据输出到屏幕上
fflush(stdout) 是 C 语言标准库中的一个函数,它的作用是刷新输出缓冲区,并将缓冲区中的数据立即输出到标准输出设备,比如屏幕、终端等。
在 C 语言程序中,输出到标准输出设备的数据并不是立即显示在屏幕上,而是先存放在输出缓冲区中,当缓冲区满了、程序结束或者遇到 fflush 函数时,才将缓冲区中的数据输出到标准输出设备。如果程序没有输出足够的数据,缓冲区就不会满,输出数据也不会被显示。这时候,使用 fflush(stdout) 函数可以立即刷新输出缓冲区,将缓冲区中的数据输出到屏幕上。
在编写需要实时显示的程序时,比如显示进度条、实时输出时间等,使用 fflush(stdout) 函数可以确保输出数据能够及时显示在屏幕上,而不是等待缓冲区满或者程序结束时才输出。
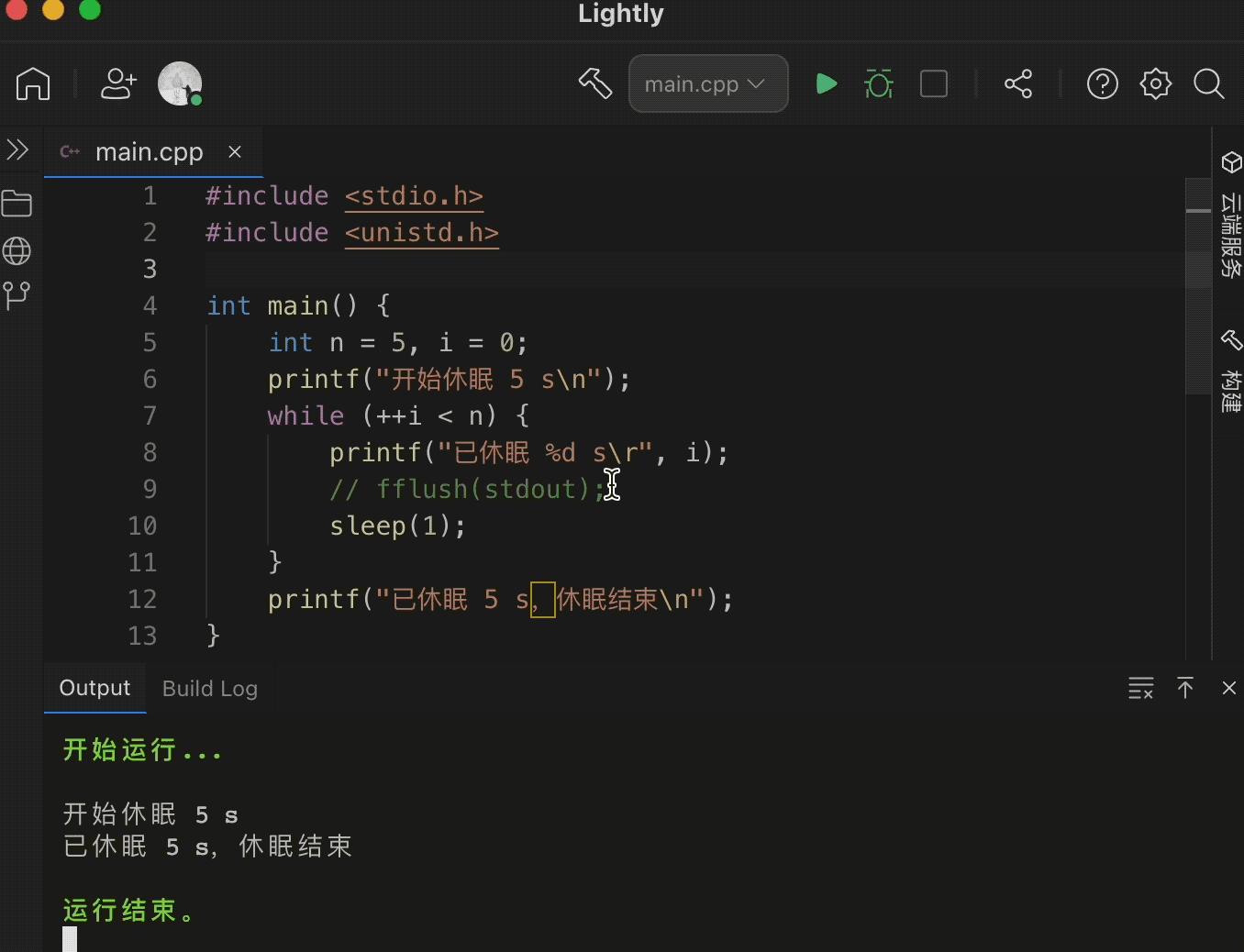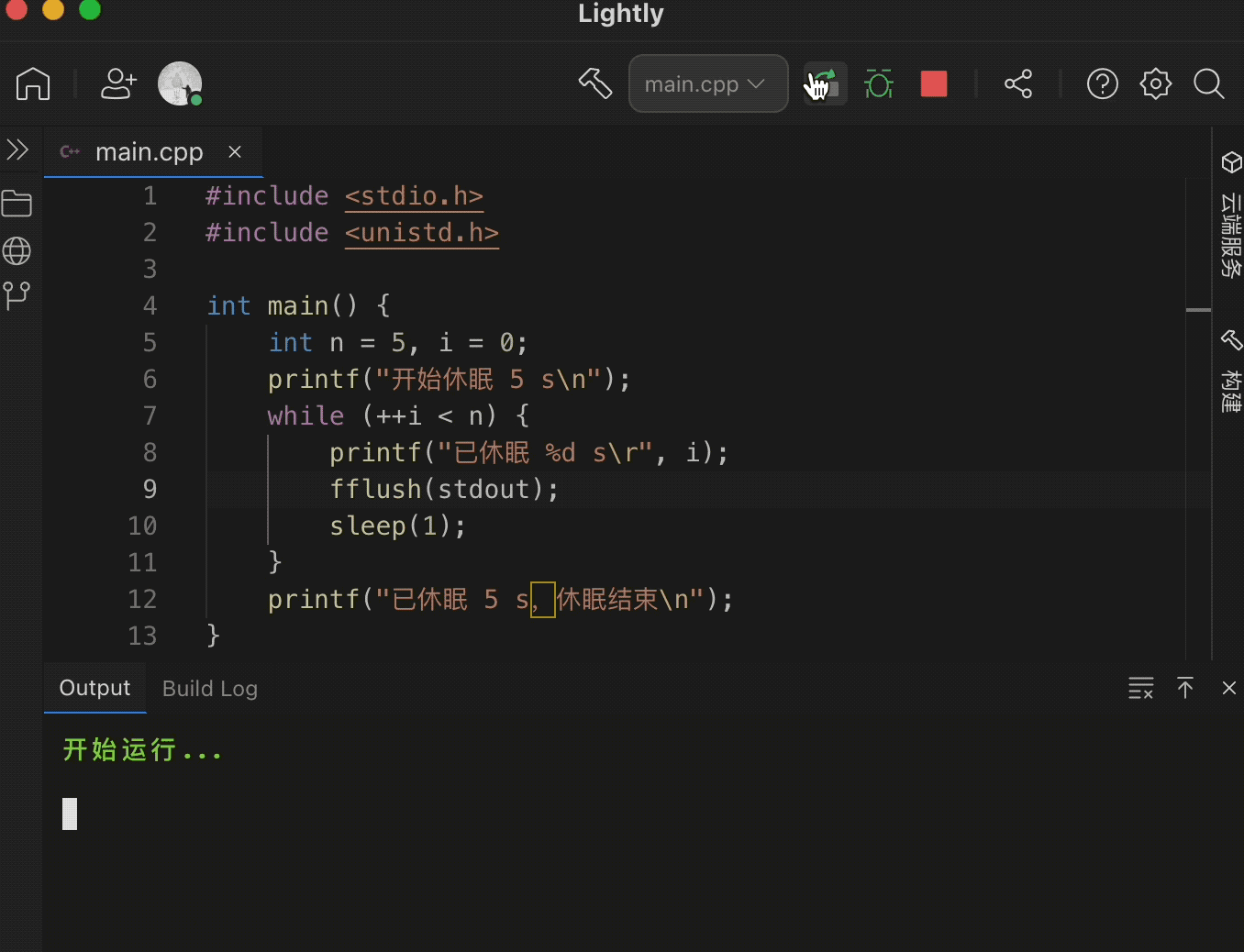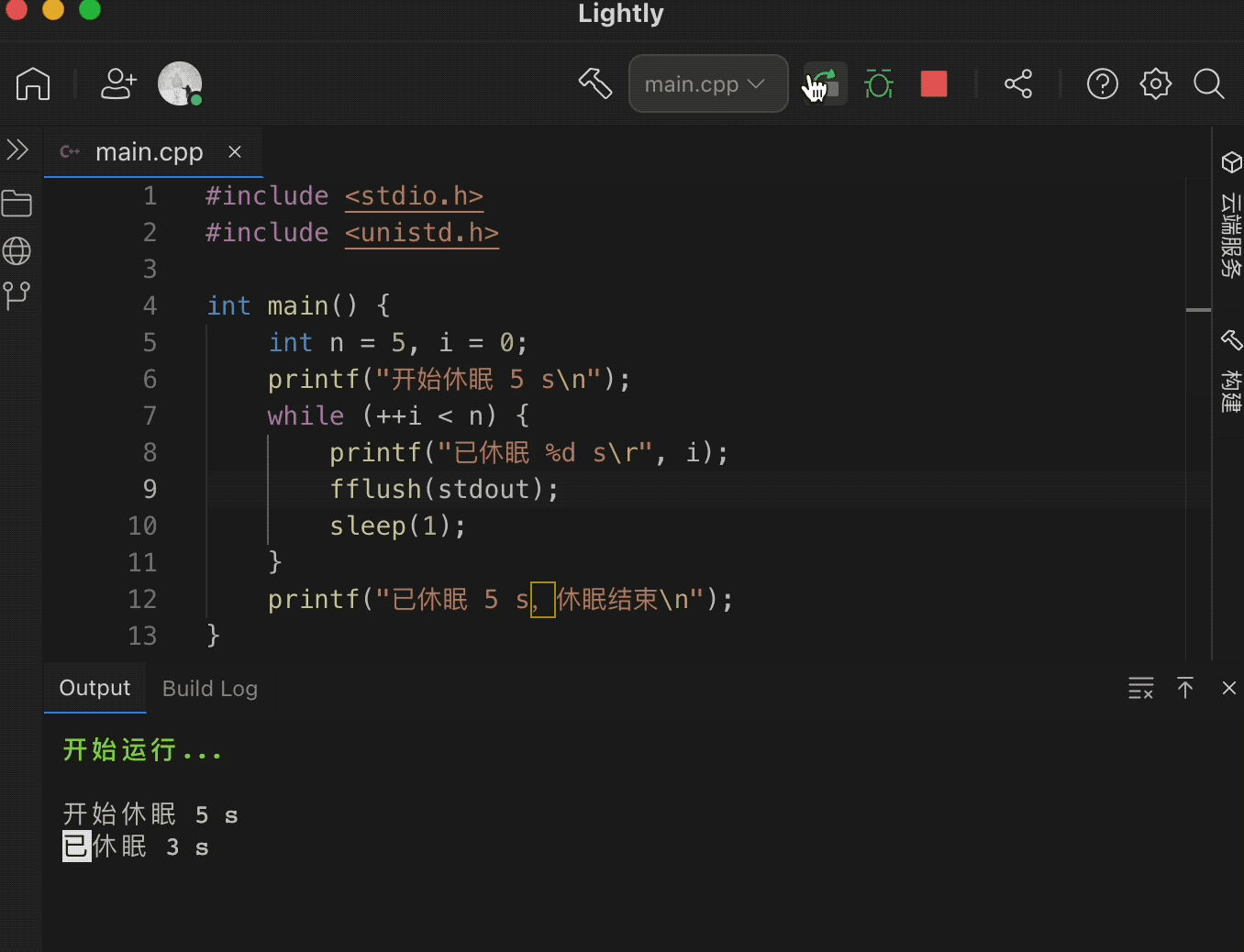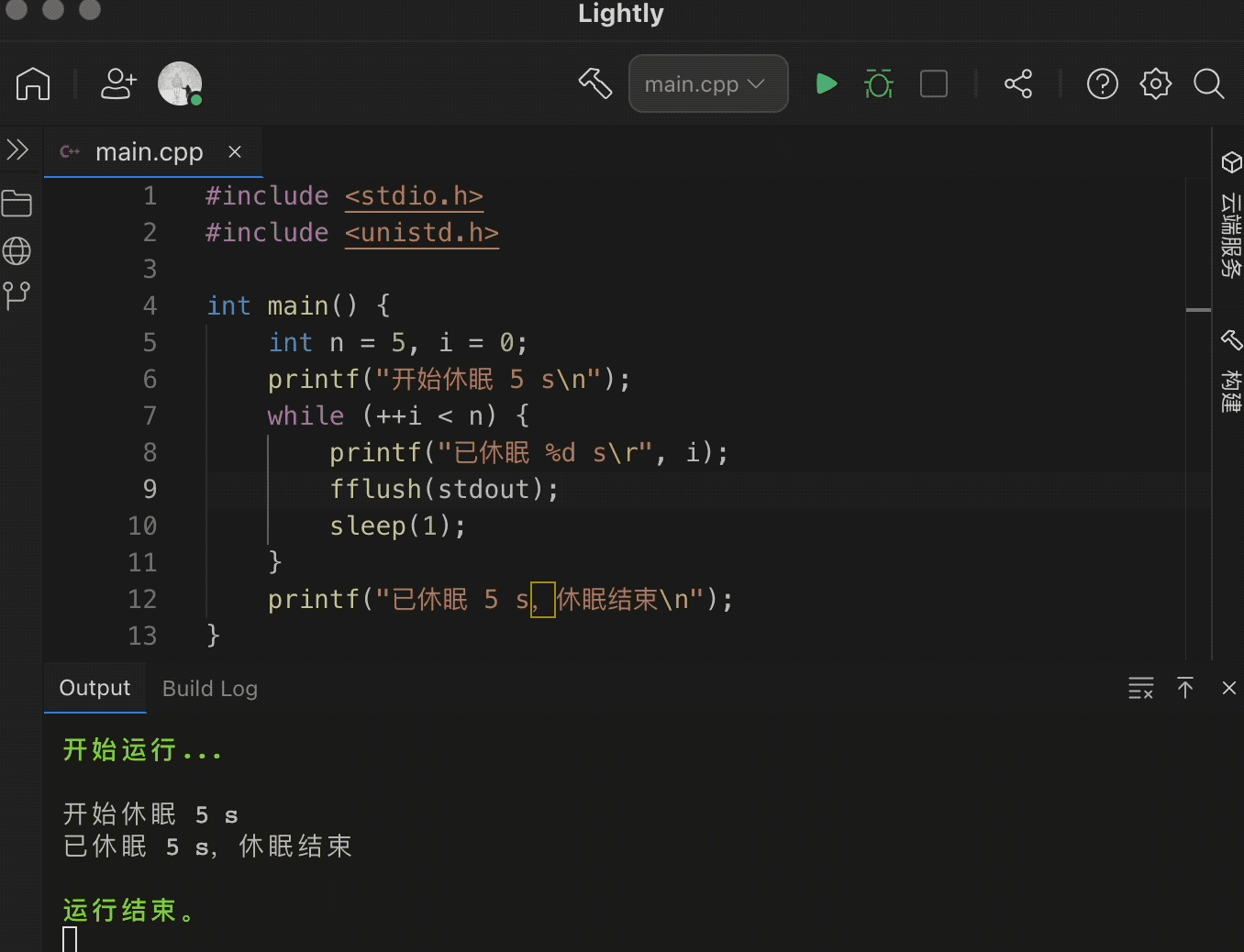
#include <stdio.h>#include <unistd.h>int main() {int n = 5, i = 0;printf("开始休眠 5 s\n");while (++i < n) {printf("已休眠 %d s\r", i);fflush(stdout);sleep(1);}printf("已休眠 5 s,休眠结束\n");}
fflush(stdout);
如果没有这条语句,那么我们要输出的内容,将会堆积在缓冲区中,当循环结束时,才会一并输出。具体效果见下图 👇🏻
time
- time 函数声明:
time_t time(time_t* timer); - 参数
- 如果 timer 不为 NULL,则表示需要 将当前时间的秒数存储到 timer 指向的变量中,同时函数也会返回当前时间的秒数
- 如果 timer 为 NULL,则表示不需要返回时间值,函数直接返回当前时间的秒数
- 返回值
- time 函数返回值为 time_t 类型的数据,即整数型数据,表示当前时间距离格林威治时间 1970 年 1 月 1 日 0 时 0 分 0 秒的时间戳(time stamp)。
- 例如:函数返回值为
1679376100267时,表示当前时间为2023/3/21 13:21:40。 - time_t 是 C 语言标准库中 用于表示时间值的类型
- 打印 time_t 类型的数据可以使用
%ld作为格式控制字符
- time 是 C 语言标准库中的一个函数,它的作用是 获取当前系统时间的秒数
- 这个时间戳也被称为“UNIX时间戳”
应用场景:
- 计时器
- 日志记录
- 时间戳生成
- 事件处理
- ……
获取当前时间的方法不止这一种,还有其他的一些函数和方法,比如:
- gettimeofday
- clock
- localtime
- ……
#include <stdio.h>#include <time.h>int main() {time_t current_time = time(NULL);printf("当前时间戳为:%ld\n", current_time);return 0;}/* 运行结果:当前时间戳为:1679552034*/
localtime
- 函数声明:
struct tm *localtime(const time_t *timer); - 参数
timer是指向以秒为单位的time_t时间值的 指针
- 返回值
- 一个指向
struct tm结构体类型的指针 struct tm结构体类型包含有关时间(年、月、日等)的信息
- 一个指向
localtime是 C 语言标准库中用于处理时间的函数之一- 作用是将 time_t 类型的时间值转换为当地时间(local time)
struct tm 结构体定义如下:
struct tm {int tm_sec; /* 秒数(0~59)*/int tm_min; /* 分钟数(0~59)*/int tm_hour; /* 小时数(0~23)*/int tm_mday; /* 日数(1~31)*/int tm_mon; /* 月数(0~11)*/int tm_year; /* 年数(自 1900 年起)*/int tm_wday; /* 一周中的第几天(0~6,0 表示星期天)*/int tm_yday; /* 一年中的第几天(0~365)*/int tm_isdst; /* 夏令时标识符(-1 表示无夏令时信息,0 表示无夏令时,正数表示有夏令时)*/};
localtime 函数的返回值为一个指向 struct tm 结构体的指针,指针指向的结构体包含有关时间的各个部分的信息。
本章要实现的“时钟”demo,需要用到的就是 struct tm 结构体身上的:
- 时
tm_hour - 分
tm_min - 秒
tm_sec
#include <stdio.h>#include <time.h>int main() {// 获取当前时间time_t timestamp = time(NULL);struct tm* tm_local = localtime(×tamp);// 输出时分秒printf("当前时间: %02d:%02d:%02d\n",tm_local->tm_hour,tm_local->tm_min,tm_local->tm_sec);return 0;}/*当前时间: 06:17:55*/
补充:有关指针的更多内容,会在第 5 章详细介绍,现在只要知道我们可以通过上述这种方式,拿到当下时间数据即可。
时钟
#include <stdio.h>#include <windows.h>struct clock {int hour;int minute;int second;};typedef struct clock CLOCK;int main() {CLOCK t = {0, 0, 0};int n = 100, i = 0;char c;while (++i < n) {t.second++;if (t.second >= 60) {t.second = 0;t.minute++;}if (t.minute >= 60) {t.minute = 0;t.hour++;}if (t.hour >= 24)t.hour = 0;printf("%2d:%2d:%2d\r", t.hour, t.minute, t.second);Sleep(1000);}}
这段程序丢到 windows 设备上可以正常跑,Linux 上不存在 windows.h、Sleep,所以在 Linux 上是没法运行的。
#include <cstdlib>#include <stdio.h>#include <unistd.h>struct clock {int hour;int minute;int second;};typedef struct clock CLOCK;int main() {CLOCK t = {0, 0, 0};int n = 100, i = 0;char c;while (++i < n) {t.second++;if (t.second >= 60) {t.second = 0;t.minute++;}if (t.minute >= 60) {t.minute = 0;t.hour++;}if (t.hour >= 24)t.hour = 0;printf("%02d:%02d:%02d", t.hour, t.minute, t.second);system("clear");// printf("%02d:%02d:%02d\r", t.hour, t.minute, t.second);fflush(stdout); // 刷新缓冲区sleep(1);}}/* 运行结果:00:00:17*/
实时更新效果:两种写法,效果是非常类似的
- 写法 1:
\rprintf("%02d:%02d:%02d\r", t.hour, t.minute, t.second);- 使用
\r控制字符将光标移动到行首,以便实现实时更新的效果
- 写法 2:
system("clear");printf("%02d:%02d:%02d", t.hour, t.minute, t.second);- 每次输出之前先清屏
system("clear");,以便实现实时更新的效果
fflush(stdout);
- 刷新缓冲区
- 使用 fflush 函数刷新输出缓冲区,保证信息能够及时显示
扩展:实时显示系统当前时间
#include <stdio.h>#include <time.h>#include <unistd.h>int main() {while (1) {time_t current_time = time(NULL); // 获取当前时间struct tm* tm = localtime(¤t_time); // 将当前时间转换为本地时间int hour = tm->tm_hour; // 获取小时数int minute = tm->tm_min; // 获取分钟数int second = tm->tm_sec; // 获取秒数printf("%02d:%02d:%02d\r", hour, minute, second); // 输出时分秒信息fflush(stdout); // 刷新缓冲区sleep(1); // 等待1秒}return 0;}/* 运行结果:03:02:17*/
由于 localtime 函数返回的是一个指向 struct tm 结构体类型的指针,因此需要使用 -> 运算符来访问其成员,如 local_time->tm_year 来访问年份信息。
课件源码
#include <stdio.h>typedef struct student {char grade[5];char department[3];char major[3];char cclass[3];char number[4];} student;int main() {char number[14];student s;int i;scanf("%s", number);for (i = 0; i < 4; ++i)s.grade[i] = number[i];s.grade[i] = '\0';s.department[0] = number[i++];s.department[1] = number[i++];s.department[2] = '\0';s.major[0] = number[i++];s.major[1] = number[i++];s.major[2] = '\0';s.cclass[0] = number[i++];s.cclass[1] = number[i++];s.cclass[2] = '\0';s.number[0] = number[i++];s.number[1] = number[i++];s.number[2] = number[i++];s.number[3] = '\0';printf("学院:%s;专业:%s;年级:%s;班:%s;学号:%s\n", s.department, s.major,s.grade, s.cclass, s.number);}/* 运行结果:2015060204030学院:06;专业:02;年级:2015;班:04;学号:030*/
使用结构体存储学生信息
#include <stdio.h>typedef struct student {int grade;char department[32];char major[32];char cclass[32];char number[32];} student;int main() {student s = {.grade = 2022,.department = "计算机科学与技术",.major = "软件工程",.cclass = "1班",.number = "20220001",};printf("年级:%d\n", s.grade);printf("学院:%s\n", s.department);printf("专业:%s\n", s.major);printf("班级:%s\n", s.cclass);printf("学号:%s\n", s.number);return 0;}/* 运行结果:年级:2022学院:计算机科学与技术专业:软件工程班级:1班学号:20220001 */
#include <stdio.h>typedef struct student {char nickName[20];int grade;char department[32];char major[32];char cclass[32];char number[32];} student;int main() {student s = {0};printf("请输入学生信息:\n");printf("昵称:");scanf("%s", s.nickName);printf("年级:");scanf("%d", &s.grade);printf("学院:");scanf("%s", s.department);printf("专业:");scanf("%s", s.major);printf("班级:");scanf("%s", s.cclass);printf("学号:");scanf("%s", s.number);printf("\n学生信息如下:\n");printf("昵称:%s\n", s.nickName);printf("年级:%d\n", s.grade);printf("学院:%s\n", s.department);printf("专业:%s\n", s.major);printf("班级:%s\n", s.cclass);printf("学号:%s\n", s.number);return 0;}/* 运行结果:请输入学生信息:昵称:Tdahuyou年级:2018学院:信息技术学院专业:物联网工程班级:B18-1学号:1820573学生信息如下:昵称:Tdahuyou年级:2018学院:信息技术学院专业:物联网工程班级:B18-1学号:1820573*/
4.4 华为 CloudIDE
删除重复字符
00:00:32 | 题目要求
00:01:53 | 输入输出
第四章实验 | 成绩管理系统
notes
练习 1:删除字符串中连续的重复字符
实现删除字符串中连续的重复字符(除字母和数字)。
描述:
输入为字符串,将字符串中连续重复的,不是字母且不是数字的字符删去,然后输出处理后的字符串。
要求:
输入字符串最长 50 个字符,之后截断,只输出处理后的字符串。
算法要点:
- 先用字符数组存储字符串
- 逐个判断字符是否为字母或者数字
- 使用两个下标指针移动赋值操作
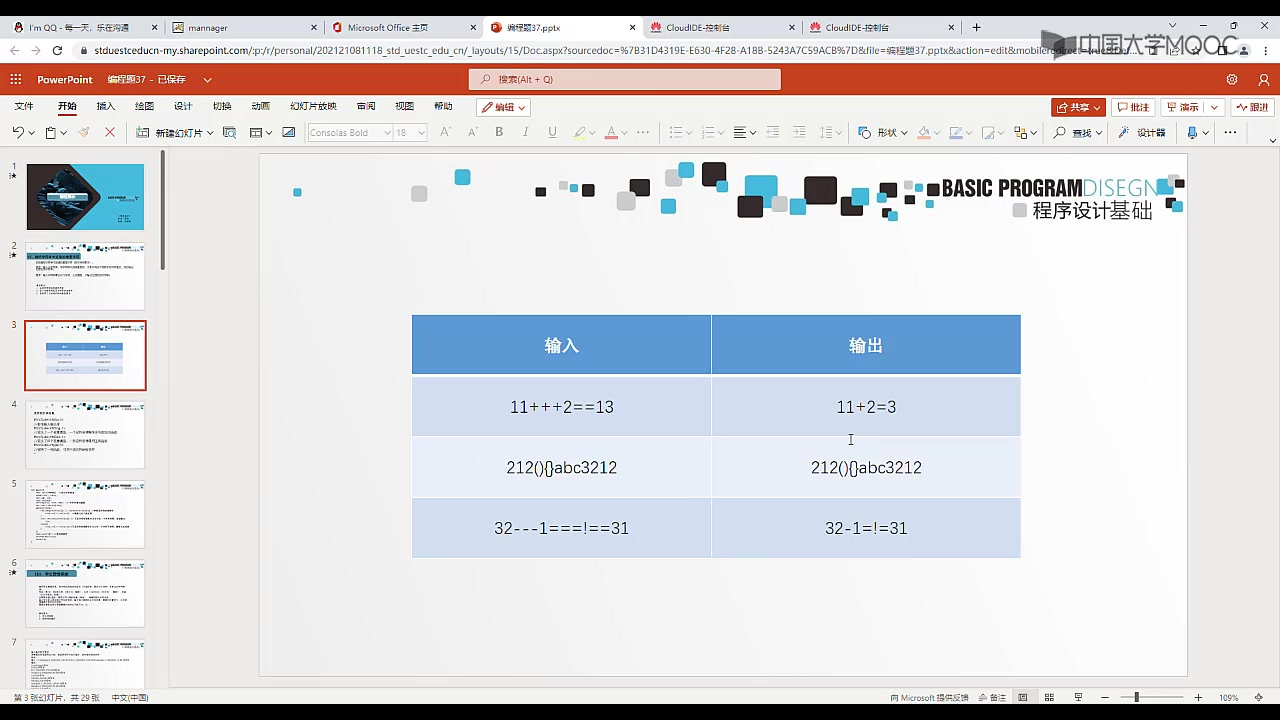
| 输入 | 输出 |
| —- | —- |
|
11+++2==13|11+2=3| |212(){}abc3212|212(){}abc3212| |32---1===!==31|32-1=!=31|
#include <ctype.h>#include <stdbool.h>#include <stdio.h>#include <string.h>// 判断字符是否为字母或数字bool is_letter_or_digit(char c) { return isalpha(c) || isdigit(c); }int main() {char input[51];// 从输入读取最多 50 个字符的字符串fgets(input, 51, stdin);int length = strlen(input);// 去除换行符,如果存在if (input[length - 1] == '\n') {input[length - 1] = '\0';length--;}char result[51]; // 存放删除连续字符后的字符串内容int result_index = 0;// 遍历输入字符串for (int i = 0; i < length; ++i) {// 如果是字母或数字,直接添加到结果字符串if (is_letter_or_digit(input[i])) {result[result_index++] = input[i];} else {// 如果不是字母或数字,将字符添加到结果字符串,然后跳过连续的相同字符result[result_index++] = input[i];while (i < length - 1 && !is_letter_or_digit(input[i + 1]) &&input[i] == input[i + 1]) {i++;}}}// 添加字符串结束符result[result_index] = '\0';// 输出处理后的字符串printf("%s\n", result);return 0;}/* 运行结果:11+++2==1311+2=13212(){}abc3212212(){}abc321232---1===!==3132-1=!=31*/
#include <ctype.h>#include <stdbool.h>#include <stdio.h>#include <string.h>bool is_letter_or_digit(char c) { return isalpha(c) || isdigit(c); }int main() {char input[51];fgets(input, 51, stdin);int length = strlen(input);if (input[length - 1] == '\n') {input[length - 1] = '\0';length--;}char result[51];int result_index = 0;// 简化 for 循环的循环体写法for (int i = 0; i < length; ++i) {result[result_index++] = input[i];if (is_letter_or_digit(input[i])) continue;while (i < length - 1 && input[i] == input[i + 1]) i++;}result[result_index] = '\0';printf("%s\n", result);return 0;}
// 使用到的库 👇🏻#include <stdio.h> // 标准输入输出库#include <string.h> // 定义了一个变量类型、一个宏和各种操作字符数组的函数#include <stdlib.h> // 定义了四个变量类型、一些宏和各种通用工具函数#include <ctype.h> // 提供了一些函数,可用于测试和映射字符int main() {char strs[10000]; // 定义字符数组scanf("%s", strs);int i = 0, j = 1;char res[51];strncpy(res, strs, 50); // 字符串拷贝函数int len = strlen(res);while (j < len) {if (isdigit(strs[j]) || isalpha(strs[j])) { // 判断是字母或者数字res[++i] = res[j++]; // 赋值之后下标后移} else if (res[i] == res[j]) { // 不是字母或者数字且与之前一个字符相同,直接跳过j++;} else {res[++i] = res[j++]; // 不是字母或者数字且与之前一个字符不相同,赋值之后后移}};res[++i] = '\0'; // 添加结束符printf("%s", res);return 0;}
#include <stdio.h>#include <string.h>#include <stdlib.h>#include <ctype.h>int main() {char strs[10000];scanf("%s", strs);int i = 0, j = 1;char res[51];strncpy(res, strs, 50);int len = strlen(res);while (j < len) {if (isdigit(strs[j]) || isalpha(strs[j])) res[++i] = res[j++];else if (res[i] == res[j]) j++;else res[++i] = res[j++];};res[++i] = '\0';printf("%s", res);return 0;}
strncpy(res, strs, 50);
在处理字符串时,直接使用了 strncpy 函数将原始输入字符串截断并复制到 res 数组中。
这样可以避免在循环中处理换行符。
版本 1 中,需要在循环外部对换行符进行处理。
练习 2:学生管理系统
编写学生管理系统,其中学生的信息有姓名(汉语拼音,最多 20 个字符,长度 21 的字符数组),性别(男/女,用 1 表示男,2 表示女,整数)、生日(19850101(年月日),整数)、身高(以 m 为单位,实数),还需要处理 C 语言、微积分两门课的成绩(整数)。
请编写程序实现功能:输入学生的人数和每个学生的信息;输出每门课程的总平均成绩、最高分和最低分,以及获得最高分的学生的信息。需要注意的是某门课程最高分的学生可能不只一人。
算法要点:
- 定义结构体
- 结构体的遍历
输入输出格式要求:身高输出时保留两位小数,请按照例子中进行输出,请勿输出其他字符
测试用例:
| 输入 | 输出 |
|---|---|
3 zhangsan 1 19910101 1.85 85 90 lisi 1 19920202 1.56 89 88 wangwu 2 19910303 1.6 89 90 |
```markdown |
C_average:87 C_max:89 lisi 1 19920202 1.56 89 88 wangwu 2 19910303 1.60 89 90 C_min:85 Calculus_average:89 Calculus_max:90 zhangsan 1 19910101 1.85 85 90 wangwu 2 19910303 1.60 89 90 Calculus_min:88
|| `2 lisi 1 19920202 1.56 89 88 wangwu 2 19910303 1.6 89 90` | ```markdownC_average:89C_max:89lisi 1 19920202 1.56 89 88wangwu 2 19910303 1.60 89 90C_min:89Calculus_average:89Calculus_max:90wangwu 2 19910303 1.60 89 90Calculus_min:88
|
| 1 wangwu 2 19910303 1.6 89 90 | ```markdown
C_average:89
C_max:89
wangwu 2 19910303 1.60 89 90
C_min:89
Calculus_average:90
Calculus_max:90
wangwu 2 19910303 1.60 89 90
Calculus_min:90
|```cpp#include <stdio.h>#include <stdbool.h>// 定义学生结构体typedef struct {char name[21]; // 姓名int gender; // 性别int birthdate; // 生日float height; // 身高int c_score; // C 语言成绩int calculus_score; // 微积分成绩} Student;int main() {int n;scanf("%d", &n); // 输入学生人数Student students[n]; // 定义学生结构体数组// 输入每个学生的信息for (int i = 0; i < n; i++) {scanf("%s %d %d %f %d %d", students[i].name, &students[i].gender, &students[i].birthdate, &students[i].height, &students[i].c_score, &students[i].calculus_score);}int c_min = 101, c_max = -1, calculus_min = 101, calculus_max = -1;float c_sum = 0, calculus_sum = 0;// 计算每门课程的总成绩、最高分和最低分for (int i = 0; i < n; i++) {c_sum += students[i].c_score;calculus_sum += students[i].calculus_score;if (students[i].c_score > c_max) c_max = students[i].c_score;if (students[i].c_score < c_min) c_min = students[i].c_score;if (students[i].calculus_score > calculus_max) calculus_max = students[i].calculus_score;if (students[i].calculus_score < calculus_min) calculus_min = students[i].calculus_score;}// 输出结果printf("C_average:%.0f\n", c_sum / n);printf("C_max:%d\n", c_max);// 输出获得 C 语言最高分的学生信息for (int i = 0; i < n; i++) {if (students[i].c_score == c_max) {printf("%s %d %d %.2f %d %d\n", students[i].name, students[i].gender, students[i].birthdate, students[i].height, students[i].c_score, students[i].calculus_score);}}printf("C_min:%d\n", c_min);printf("Calculus_average:%.0f\n", calculus_sum / n);printf("Calculus_max:%d\n", calculus_max);// 输出获得微积分最高分的学生信息for (int i = 0; i < n; i++) {if (students[i].calculus_score == calculus_max) {printf("%s %d %d %.2f %d %d\n", students[i].name, students[i].gender, students[i].birthdate, students[i].height, students[i].c_score, students[i].calculus_score);}}printf("Calculus_min:%d\n", calculus_min);return 0;}
一些细微的差异:
printf("C_average:%.0f\n", c_sum / n);如果是这种写法,那么 (85 + 89 + 89) / 3 打印结果是 88,而测试用例的结果是 87printf("C_average:%d\n", int(c_sum / n));如果要确保和测试保持统一,这里可以改写为这种写法
3 zhangsan 1 19910101 1.85 85 90 lisi 1 19920202 1.56 89 88 wangwu 2 19910303 1.6 89 90C_average:88C_max:89lisi 1 19920202 1.56 89 88wangwu 2 19910303 1.60 89 90C_min:85Calculus_average:89Calculus_max:90zhangsan 1 19910101 1.85 85 90wangwu 2 19910303 1.60 89 90Calculus_min:882 lisi 1 99920202 1.56 89 88 wangwu 2 19910303 1.6 89 90C_average:89C_max:89lisi 1 99920202 1.56 89 88wangwu 2 19910303 1.60 89 90C_min:89Calculus_average:89Calculus_max:90wangwu 2 19910303 1.60 89 90Calculus_min:881 wangwu 2 19910303 1.6 89 90C_average:89C_max:89wangwu 2 19910303 1.60 89 90C_min:89Calculus_average:90Calculus_max:90wangwu 2 19910303 1.60 89 90Calculus_min:90

若有收获,就点个赞吧
0 人点赞
