课件
6.1 认识函数
认识函数
notes
实现成绩管理系统
⚠️ 这个 demo 中涉及到不少后续的相关知识点
grades.txt 是存放学生成绩的一个本地文件,文件内容如下:
1001,张三,60,44,331002,李四,85,90,801003,王五,88,99,55
#include <algorithm>#include <codecvt>#include <cstdio>#include <fstream>#include <iomanip>#include <iostream>#include <locale>#include <sstream>#include <string>struct Student {int id;std::string name;int chinese;int math;int foreign_language;int total;float average;};// void read_students_data(const std::string &file_name,// std::vector<Student> &students) {// std::ifstream file(file_name);// if (!file.is_open()) {// std::cerr << "Error opening file!" << std::endl;// exit(1);// }// std::string line;// while (std::getline(file, line)) {// std::stringstream ss(line);// Student student;// std::string field;// std::getline(ss, field, ',');// student.id = std::stoi(field);// std::getline(ss, student.name, ',');// std::getline(ss, field, ',');// student.chinese = std::stoi(field);// std::getline(ss, field, ',');// student.math = std::stoi(field);// std::getline(ss, field, ',');// student.foreign_language = std::stoi(field);// student.total = student.chinese + student.math + student.foreign_language;// student.average = static_cast<float>(student.total) / 3;// students.push_back(student);// }// file.close();// }void print_students(const std::vector<Student> &students) {printf("%s\t%s\t%s\t%s\t%s\t%s\t%s\n", "学号", "姓名", "语文", "数学", "外语","总分", "平均分");for (const auto &student : students) {printf("%d\t%s\t%d\t%d\t%d\t%d\t%-.2f\n", student.id, student.name.c_str(),student.chinese, student.math, student.foreign_language,student.total, student.average);}}void print_failed_students(const std::vector<Student> &students) {std::vector<Student> failed_students;for (const auto &student : students) {if (student.average < 60) {failed_students.push_back(student);}}std::cout << "不及格学生名单:" << std::endl;print_students(failed_students);}void print_above_average_students(const std::vector<Student> &students) {float class_average = 0;for (const auto &student : students) {class_average += student.average;}class_average /= students.size();std::vector<Student> above_average_students;for (const auto &student : students) {if (student.average >= class_average) {above_average_students.push_back(student);}}std::cout << "全班平均分以上的学生名单:" << std::endl;print_students(above_average_students);}void print_grade_intervals(const std::vector<Student> &students) {// std::vector<int> grade_intervals(11, 0);int grade_intervals[11] = {0};for (const auto &student : students) {grade_intervals[static_cast<int>(student.average) / 10]++;}printf("各分数段的学生人数及所占百分比:\n");for (int i = 0; i <= 9; ++i) {double percentage = 100.0 * grade_intervals[i] / students.size();printf("%d - %d: %d (%.2f%%)\n", i * 10, i * 10 + 9, grade_intervals[i],percentage);}printf("%d - %d: %d (%.2f%%)\n", 100, 100, grade_intervals[10],100.0 * grade_intervals[10] / students.size());}void sort_students_by_total(std::vector<Student> &students) {std::sort(students.begin(), students.end(),[](const Student &a, const Student &b) { return a.total > b.total; });}void search_student(const std::vector<Student> &students, int search_id) {auto it =std::find_if(students.begin(), students.end(),[search_id](const Student &s) { return s.id == search_id; });if (it != students.end()) {int rank = std::distance(students.begin(), it) + 1;std::cout << "学号 " << search_id << " 的学生排名为: " << rank << std::endl;std::cout << "该学生的考试分数:" << std::endl;std::vector<Student> single_student = {*it};print_students(single_student);} else {std::cout << "未找到学号为 " << search_id << " 的学生。" << std::endl;}}int main() {std::vector<Student> students;read_students_data("grades.txt", students);// 功能1: 统计平均分的不及格人数并打印不及格学生名单print_failed_students(students);// 功能2: 统计成绩在全班平均分及平均分之上的学生人数并打印其学生名单print_above_average_students(students);// 功能3: 统计平均分的各分数段的学生人数及所占的百分比print_grade_intervals(students);// 功能4: 按总分成绩由高到低排出成绩的名次sort_students_by_total(students);// 功能5: 打印出名次表,表格内包括学生编号、各科分数、总分和平均分std::cout << "名次表:" << std::endl;print_students(students);// 功能6: 任意输入一个学号,能够查找出该学生在班级中的排名及其考试分数int search_id;std::cout << "请输入要查找的学生学号: ";std::cin >> search_id;search_student(students, search_id);return 0;}
不及格学生名单:学号 姓名 语文 数学 外语 总分 平均分1001 张三 60 44 33 137 45.67全班平均分以上的学生名单:学号 姓名 语文 数学 外语 总分 平均分1002 李四 85 90 80 255 85.001003 王五 88 99 55 242 80.67各分数段的学生人数及所占百分比:0 - 9: 0 (0.00%)10 - 19: 0 (0.00%)20 - 29: 0 (0.00%)30 - 39: 0 (0.00%)40 - 49: 1 (33.33%)50 - 59: 0 (0.00%)60 - 69: 0 (0.00%)70 - 79: 0 (0.00%)80 - 89: 2 (66.67%)90 - 99: 0 (0.00%)100 - 100: 0 (0.00%)名次表:学号 姓名 语文 数学 外语 总分 平均分1002 李四 85 90 80 255 85.001003 王五 88 99 55 242 80.671001 张三 60 44 33 137 45.67请输入要查找的学生学号: 1003学号 1003 的学生排名为: 2该学生的考试分数:学号 姓名 语文 数学 外语 总分 平均分1003 王五 88 99 55 242 80.67
小结:
- 使用 C 的打印方式还是 C++ 的打印方式:
- 在处理简单输出时,C++ 的 std::cout 是一个很好的选择
- 在需要精确控制输出格式的情况下,C 的 printf 函数可能会更适合
函数(function)
- 函数是 C 语言中模块化编程的最小单元,可以把每个函数看作一个模块(Module)
- 如把编程比作制造一台机器,函数就好比其零部件
- 可将这些“零部件”单独设计、调试、测试好,用时拿出来装配,再总体调试。
- 这些“零部件”可以是自己设计制造/别人设计制造/现成的标准产品
- 函数是指一段完成特定任务的、可独立调用的代码块
- 函数是程序的基本构成单元之一
- 函数能够接受零个或多个参数,可以返回值
- 函数可以具有副作用,如修改全局变量等
- 函数的组成:函数名、返回类型、参数列表和函数体四部分
- 函数名用于唯一标识一个函数
- 返回类型指定函数的返回值类型,可以是基本类型、指针类型、结构体类型等
- 参数列表用于指定函数的输入参数
- 函数体是一段可执行的代码块,实现具体的功能
- 函数调用:相当于执行函数体中的代码
- 函数执行完成后,可以返回一个值,或者不返回任何值
- 函数的分类:标准库函数、第三方库函数自定义函数
- 标准库函数:
- ANSI/ISO C 定义的标准库函数
- 符合标准的 C 语言编译器必须提供这些函数,函数的行为也要符合 ANSI/ISO C 的定义
- C 语言提供了许多标准函数库,这些函数库中包含了许多常用的函数
- 开发人员也可以自己编写函数库,以便在多个程序中复用自己的代码
- 第三方库函数
- 由其他厂商自行开发的C语言函数库
- 不在标准范围内,能扩充C语言的功能(图形、网络、数据库等)
- 自定义函数
- 自己定义的函数
- 包装后,也可成为函数库,供别人使用
- 标准库函数:
- 函数的执行流程
- main()也是函数,但稍微特殊一点点
- C程序的执行从main函数开始,一个函数可以调用其他函数,也可以被其他函数调用
- 调用其他函数后流程回到main函数
- 在main函数中结束整个程序运行
函数的定义(Function Definition)
- 函数(Function)是按给定的任务,把相关语句组织在一起的程序块,也称为例程或过程。
- 若干相关的函数可以合并成一个“模块”
- 一个C程序由一个或多个源程序文件组成
- 一个源程序文件由一个或多个函数组成
void 函数名 (void){// 声明语句序列// 可执行语句序列// ...return;}
- 函数无返回值,用 void 定义返回值类型
- 用 void 定义参数,表示没有参数
- 若函数的返回值类型为 void,则 return 语句后无需任何表达式
grades.txt 是存放学生成绩的一个本地文件,文件内容如下:
1001,张三,60,44,331002,李四,85,90,801003,王五,88,99,55
#include <stdio.h>typedef enum { success, fail } status;struct student {int id;char name[20];float chinese;float math;float foreign_language;};status ReadInfo(const char *name, struct student stu[], int *num) {status s = fail;int i = 0;FILE *fp = fopen(name, "r");if (fp == NULL)return s;while (fscanf(fp, "%d,%[^,],%f,%f,%f", &stu[i].id, stu[i].name,&stu[i].chinese, &stu[i].math,&stu[i].foreign_language) != EOF) {++i;}*num = i;s = success;fclose(fp);return s;}int main() {struct student stu[10];int num; // 行数if (ReadInfo("grades.txt", stu, &num) == success) {printf("%s\n", "成功读取到的 grades.txt 文件内容如下:");for (int i = 0; i < num; i++) {printf("%d, %s, %.2f, %.2f, %.2f\n", stu[i].id, stu[i].name,stu[i].chinese, stu[i].math, stu[i].foreign_language);}} else {printf("读取 grades.txt 文件失败\n");}return 0;}/* 运行结果:成功读取到的 grades.txt 文件内容如下:1001, 张三, 60.00, 44.00, 33.001002, 李四, 85.00, 90.00, 80.001003, 王五, 88.00, 99.00, 55.00 */
课件中的 ReadInfo 函数的写法

如果使用课件中的这种写法来读取学生信息的文件内容,那么存储学生信息的本地文件应该以二进制格式存储数据。每个学生的信息应该与 struct student 的定义严格对应,字段之间没有任何分隔符。文件中的数据顺序和结构体中的字段顺序应该一致。
文件中的数据应该是按照 int(学号)- char[20](姓名)- float(语文成绩)- float(数学成绩)- float(外语成绩)的顺序存储。每个字段都应该以其对应的数据类型的二进制形式存储,没有任何分隔符。
由于这种存储方式不便于人类阅读,因此在创建或编辑这类文件时,需要使用专门的工具或编写程序来实现。同时,由于不同操作系统和编译器对数据类型字节表示的处理可能存在差异,这种格式在跨平台使用时需要特别小心。
status ReadInfo(const char *name, struct student stu[], int *num)函数声明status函数返回值类型ReadInfo函数名称,函数名的命名需要注意语义化,通过函数名可以大致了解该函数的功能i、fp函数内部可以定义只能自己使用的变量,称内部变量return s;函数的返回语句,返回的数据 s 必须与函数返回值类型status保持一致(const char *name, struct student stu[], int *num)函数参数列表- 形参 1:
char *name数据类型是char *形参名称是name - 形参 2:
struct student stu[]数据类型是struct student []形参名称是stu - 形参 3:
int *num数据类型是int *形参名称是num
- 形参 1:
ReadInfo("grades.txt", stu, &num)函数调用,实参的数据类型需要与形参保持一致"grades.txt"实参 1stu实参 2&num实参 3
实现 Factorial
#include <stdio.h>long Fact(int n){int i;long result = 1;for (i = 2; i <= n; i++){result *= i;}return result;}int main(){int numbers[] = {0, 1, 4, 5};int length = sizeof(numbers) / sizeof(numbers[0]);for (int i = 0; i < length; i++){printf("Factorial of %d is: %ld\n", numbers[i], Fact(numbers[i]));}return 0;}/*运行结果:Factorial of 0 is: 1Factorial of 1 is: 1Factorial of 4 is: 24Factorial of 5 is: 120*/
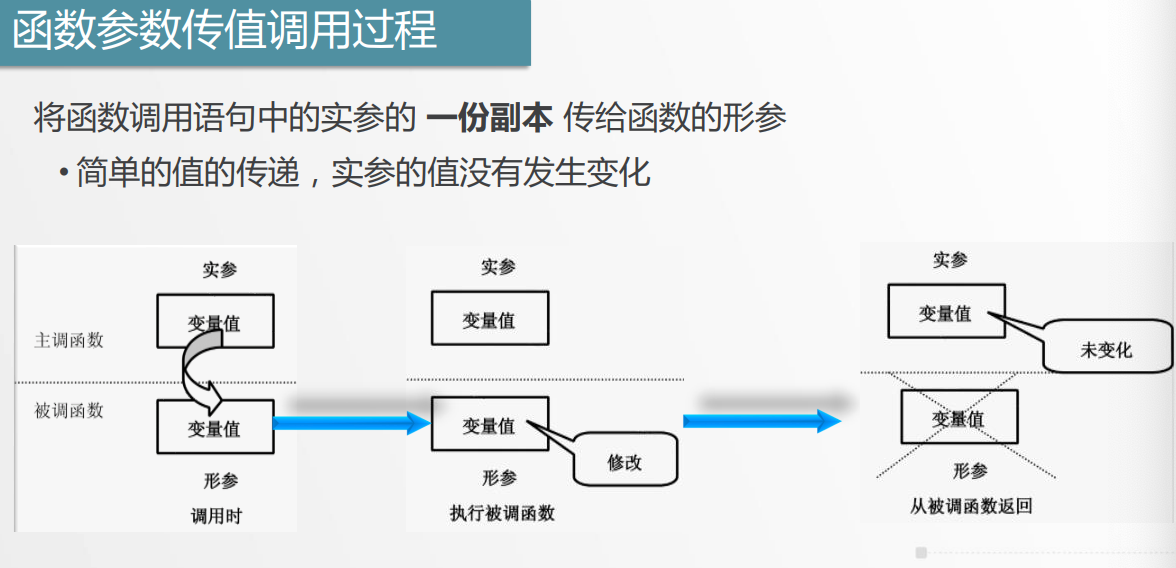
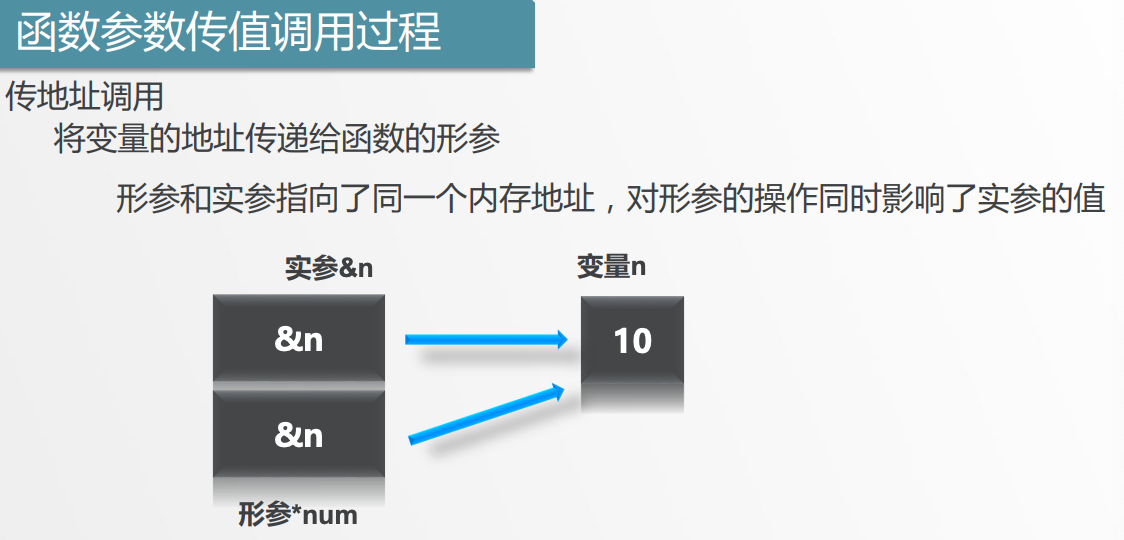
6.2 函数参数
函数参数与返回值1
函数参数与返回值2
notes
6.3 函数与数组

6.4 函数指针
6.5 函数与结构
6.6 递归函数
6.7 作用域与存储类型
6.8 模块化设计
6.9 编程实战
比较岁数-算法分析
比较岁数-实战
拿球
报数
逆序输出字符串
汉诺塔问题
6.10 命令行参数
6.11 游戏初步
(6.11.1)—6-myspriteGame.zip—6-myspriteGame.zip%22%2C%22size%22%3A842284%2C%22ext%22%3A%22zip%22%2C%22source%22%3A%22%22%2C%22status%22%3A%22done%22%2C%22download%22%3Atrue%2C%22taskId%22%3A%22u74e20fbd-da52-4407-afdd-cdccdccd291%22%2C%22taskType%22%3A%22upload%22%2C%22type%22%3A%22application%2Fzip%22%2C%22__spacing%22%3A%22both%22%2C%22mode%22%3A%22title%22%2C%22id%22%3A%22ufa95bd98%22%2C%22margin%22%3A%7B%22top%22%3Atrue%2C%22bottom%22%3Atrue%7D%2C%22card%22%3A%22file%22%7D)
补充:visualstudio2019建立游戏所需的win32项
精灵移动
键盘控制
多个精灵
碰撞检测与计分
6.12 华为CloudIDE开发与编程
子串查找
成绩管理系统
cloudIDE开发游戏
notes
练习 1:子串查找
补全函数 index(char s[], char t[]) 检查字符串 s 中是否包含字符串 t
- 若包含,则返回
t在s中的开始位置(下标值) - 否则送回
-1
int index(char s[], char t[]) {int i, j, k;for (i = 0; s[i] != '\0'; i++) {// 补全}return (-1);}int main() {static char src[256];static char dst[256];gets(src);gets(dst);printf("%d", index(src, dst));return 0;}
算法分析
已有代码分析:输入字符串 s 和 t,遍历字符串 s ,我们补充的是遍历的过程
算法设计:
- 从
s的首位开始,逐位与t的 首位 比较,相同则保存当前遍历的位置 x,然后进入步骤 2。若s已经遍历完了都没有首位相同的情况出现,则返回 -1 s从当前位置 y 开始、t从位置 0 开始逐位比较,若某个位置不同,则进入步骤 3,若t遍历完毕了且与s对应位置的字符全部相同,则返回位置 y,若s长度不足返回 -1- 从
s的位置 x 开始,逐位与t的首位比较,相同则保存当前遍历的位置 x,然后进入步骤 2。若s已经遍历完了都没有首位相同的情况出现,则返回 -1

输入案例
| S | T | 期待返回值 | 情况 |
|---|---|---|---|
| AAAAAA | AAAB | -1 | 没有子串 |
| AB | ABC | -1 | 串S不够长 |
| ABCCC | ABC | 0 | 最开始的位置匹配 |
| CCABC | ABC | 2 | 末尾匹配 |
| ASDSABCDA | ABC | 4 | 中间匹配 |
| ABABCDASDA | ABC | 2 | 中间匹配 |
#include <stdio.h>#include <stdlib.h>#include <string.h>// index 函数,检查字符串 s 中是否包含字符串 tint index(char s[], char t[]) {int i, j, k;// 遍历字符串 sfor (i = 0; s[i] != '\0'; i++) {// 如果遇到换行符,跳过if (s[i] == '\n') continue;// 从当前位置开始逐个比较字符for (j = i, k = 0; t[k] != '\0' && s[j] == t[k]; j++, k++) ;// 如果 t 遍历完毕(找到子串),或 t 仅剩一个换行符,返回当前位置 iif (t[k] == '\0' || (t[k] == '\n' && t[k + 1] == '\0')) return i;}// 如果未找到子串,返回 -1return (-1);}int main() {static char src[256];static char dst[256];// 读取两个字符串fgets(src, sizeof(src), stdin);fgets(dst, sizeof(dst), stdin);// 输出 index 函数的结果printf("%d", index(src, dst));return 0;}
注意事项:
- fgets:gets 在 C11 标准中已经被抛弃,在程序中建议使用 fgets 来替代 gets
- 换行符:在终端输入字符串的时候,我们输入完一个,然后会按下回车,此时会在字符串结束符
'\0'之前加上一个换行符\n,在处理字符串的时候,需要注意这个换行符 for (j = i, k = 0; t[k] != '\0' && s[j] == t[k]; j++, k++) ;注意结尾的分号,这是一条空语句。这部分是核心的匹配逻辑,在 s 中匹配 t,逐位比较,直到 t 结束或者出现不一致的字符if (t[k] == '\0' || (t[k] == '\n' && t[k + 1] == '\0')) return i;每次匹配结束后,进行检查,看看匹配结束的位置是否是 t 的末尾,也就是字符串 t 中的每一个字符是否都匹配上了,如果全都匹配上了则返回本次开始匹配的位置,否则移动到 s 字符串中的当前字符的下一个字符继续进行匹配
练习 1:子串查找 KMP 算法
#include <stdio.h>#include <stdlib.h>#include <string.h>void get_next(const char* pattern, int* next) {int p_len = strlen(pattern);int j = 0, k = -1;next[0] = -1;while (j < p_len - 1) {if (k < 0 || pattern[j] == pattern[k]) {++j;++k;next[j] = k;}else {k = next[k];}}}int kmp(const char* text, const char* pattern) {int t_len = strlen(text);int p_len = strlen(pattern);int* next = (int*)malloc(p_len * sizeof(int));if (!next) return -1;get_next(pattern, next);int i = 0, j = 0;while (i < t_len && j < p_len) {if (j < 0 || text[i] == pattern[j]) {++i;++j;}else {j = next[j];}}free(next);return j == p_len ? i - j : -1;}int main() {char text[100], pattern[100];scanf("%s%s", text, pattern);int pos = kmp(text, pattern);printf("%d\n", pos);return 0;}
对比 KMP 算法和 BF(暴力匹配)算法来实现字符串匹配功能
- KMP 算法是一种优化后的字符串匹配算法,它在匹配字符串时减少了不必要的比较,具有比 BF 算法更高的效率
- BF 算法则是一种最简单、最暴力的字符串匹配算法,通过逐一比较两个字符串中的每个字符来进行匹配,效率较低
从算法效率上来讲,使用 KMP 算法实现字符串匹配功能更好。不过在实际应用中,也需要考虑代码的易读性、可维护性等因素。从这个角度来讲,两种实现方式各有优缺点,具体需要根据实际情况进行选择。
练习 2:学生成绩管理
在第四章中的学生成绩管理 demo 的 4.4.2 第四章实验 | 成绩管理系统 基础上进行扩展,要求如下:
文件名称:char name[] = "stuScores.txt";
注意:第一个函数要求从文件 name 中读取数据,文件内容:第一个数据是学生人数 n;后面的数据是 n 个学生的详细信息,需要用 fread 依次读出人数及 n 个人的信息数据。读出的成绩数据并没有进行累加求和,需要您自己计算。
详细信息的数据格式:编号id,名字,语文成绩,数学成绩,英语成绩
需要实现的函数 **int ReadStuInfoFromFile(char *name, student **stu);**
- 输入参数:字符串 name 是要打开的文件名称
- 输出参数:stu 是读出的学生的详细信息
- 函数的返回值:学生人数,任何错误返回 0
分析:
- name 为打开的文件名,stu 为读出学生信息的结构体数组
- 通过 name 打开文件,读入内部的数据,转换为 student 结构体并存入 stu 数组中
- 任何错误返回 0,可能会出现的错误类型:
- 文件打开错误,返回的 File 指针为 NULL
- 学生人数 n 小于 1
- 申请空间时的错误
- 名字太长
- 分数不合理 (-29, 1200)
- 学生编号重复
需要实现的函数 **int NoPass(student stu[], int n, student **noPassStudent, int *m);**
- 输入参数:stu 是全班学生信息,n 是人数
- 输出参数:
- 3 科平均成绩不及格人名单 noPassStudent
- 不及格人数 m
- 返回值:操作成功返回 0,失败返回 -1
分析:
- 函数要求构建 3 科平均成绩不及格人名单 noPassStudent,并为不及格人数 m 赋值。即三科总成绩不足 180 的人归入不及格名单。
- 失败返回 -1,可能会出现的错误类型:
- 输入的 n 小于 1,输入 n 错误
- 输入的 stu 为 NULL
需要实现的函数 **int Pass(student stu[], int n, student **PassStudent, int *m);**
- 输入参数:stu 是全班学生信息,n 是人数
- 输出参数:3 科平均成绩及格人名单 PassStudent,及格人数 m
- 返回值:操作成功返回 0,失败返回 -1
分析:noPass 函数中的 <180 改为 >=180 即可
需要实现的函数 **int SortStudents(student stu[], int n);**
- 输入参数:stu 是全班学生信息,n 是人数
- 输出参数:按照总分/平均分排序后的结果也存储在 stu 中
- 返回值:操作成功返回 0,失败返回 -1
分析:使用冒泡函数进行排序
失败返回 -1,可能会出现的错误类型:
- 输入的 n 小于 1
- 输入的 stu 为 NULL
需要实现的函数 **int SearchStudent(student stu[], int n, int id, int *rank, student *rstu);**
- 输入参数:stu 是全班学生信息,n 是人数,id 是待查找的学号
- 输出参数:rank 是在班上的排名,rstu 是这个学生的详细信息
- 返回值:查找成功返回 0,失败返回 -1
分析:先遍历得到学生信息
失败返回 -1,可能会出现的错误类型:
- 输入的 n 小于 1
- 输入的 stu 为 NULL

若有收获,就点个赞吧
0 人点赞
