zip
温度转换
TempStr = input("请输入带有符号的温度值: ")if TempStr[-1] in ["F", "f"]:C = (eval(TempStr[0:-1]) - 32) / 1.8print("转换后的温度是{:.2f}C".format(C))elif TempStr[-1] in ["C", "c"]:F = 1.8 * eval(TempStr[0:-1]) + 32print("转换后的温度是{:.2f}F".format(F))else:print("输入格式错误")"""请输入带有符号的温度值: 39C转换后的温度是102.20F"""
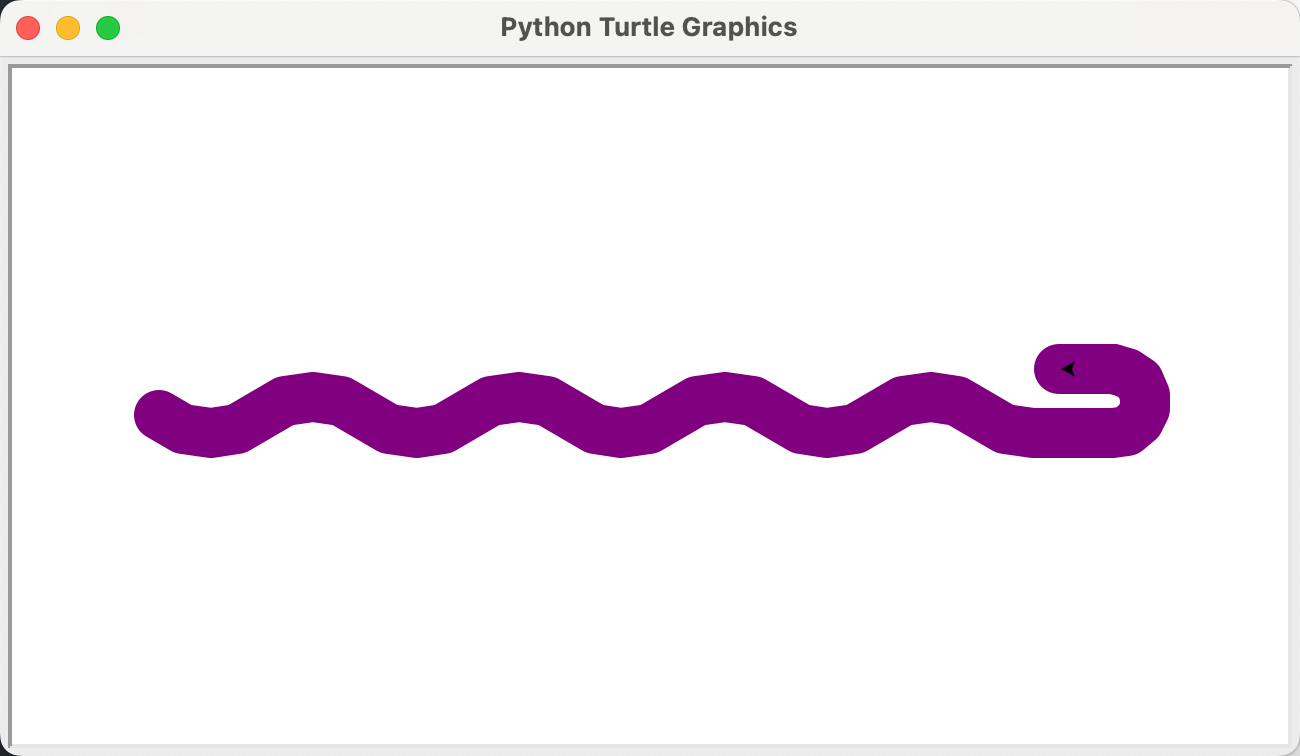
python 蟒蛇绘制
import turtleturtle.setup(650, 350, 200, 200)turtle.penup()turtle.fd(-250)turtle.pendown()turtle.pensize(25)turtle.pencolor("purple")turtle.seth(-40)for i in range(4):turtle.circle(40, 80)turtle.circle(-40, 80)turtle.circle(40, 80 / 2)turtle.fd(40)turtle.circle(16, 180)turtle.fd(40 * 2 / 3)turtle.done()
天天向上的力量
dayup = pow(1.001, 365)daydown = pow(0.999, 365)print("向上:{:.2f},向下:{:.2f}".format(dayup, daydown))# 向上:1.44,向下:0.69
dayfactor = 0.019dayup = pow(1 + dayfactor, 365)daydown = pow(1 - dayfactor, 365)print("向上:{:.2f},向下:{:.2f}".format(dayup, daydown))# 向上:962.89,向下:0.00
dayup = 1.0dayfactor = 0.01for i in range(365):if i % 7 in [6, 0]:dayup = dayup * (1 - dayfactor)else:dayup = dayup * (1 + dayfactor)print("工作日的力量:{:.2f} ".format(dayup))# 工作日的力量:4.63
def dayUP(df):dayup = 1for i in range(365):if i % 7 in [6, 0]:dayup = dayup * (1 - 0.01)else:dayup = dayup * (1 + df)return dayupdayfactor = 0.01while dayUP(dayfactor) < 37.78:dayfactor += 0.001print("工作日的努力参数是:{:.3f} ".format(dayfactor))# 工作日的努力参数是:0.019
文本进度条
import timescale = 10print("------执行开始------")for i in range(scale + 1):a = "*" * ib = "." * (scale - i)c = (i / scale) * 100print("{:^3.0f}%[{}->{}]".format(c, a, b))time.sleep(0.1)print("------执行结束------")"""------执行开始------0 %[->..........]10 %[*->.........]20 %[**->........]30 %[***->.......]40 %[****->......]50 %[*****->.....]60 %[******->....]70 %[*******->...]80 %[********->..]90 %[*********->.]100%[**********->]------执行结束------"""
import timefor i in range(101):print("\r{:3}%".format(i), end="")time.sleep(0.1)# 100%
import timescale = 50print("执行开始".center(scale // 2, "-"))start = time.perf_counter()for i in range(scale + 1):a = "*" * ib = "." * (scale - i)c = (i / scale) * 100dur = time.perf_counter() - startprint("\r{:^3.0f}%[{}->{}]{:.2f}s".format(c, a, b, dur), end="")time.sleep(0.1)print("\n" + "执行结束".center(scale // 2, "-"))"""-----------执行开始----------100%[**************************************************->]5.22s-----------执行结束----------"""
身体质量指数 BMI
height, weight = eval(input("请输入身高(米)和体重(公斤)[逗号隔开]: "))bmi = weight / pow(height, 2)print("BMI 数值为:{:.2f}".format(bmi))who = ""if bmi < 18.5:who = "偏瘦"elif 18.5 <= bmi < 25:who = "正常"elif 25 <= bmi < 30:who = "偏胖"else:who = "肥胖"print("BMI 指标为:国际'{0}'".format(who))"""请输入身高(米)和体重(公斤)[逗号隔开]: 1.66,66BMI 数值为:23.95BMI 指标为:国际'正常'"""
height, weight = eval(input("请输入身高(米)和体重(公斤)[逗号隔开]: "))bmi = weight / pow(height, 2)print("BMI 数值为:{:.2f}".format(bmi))nat = ""if bmi < 18.5:nat = "偏瘦"elif 18.5 <= bmi < 24:nat = "正常"elif 24 <= bmi < 28:nat = "偏胖"else:nat = "肥胖"print("BMI 指标为:国内'{0}'".format(nat))"""请输入身高(米)和体重(公斤)[逗号隔开]: 1.66,66BMI 数值为:23.95BMI 指标为:国内'正常'"""
height, weight = eval(input("请输入身高(米)和体重(公斤)[逗号隔开]: "))bmi = weight / pow(height, 2)print("BMI 数值为:{:.2f}".format(bmi))who, nat = "", ""if bmi < 18.5:who, nat = "偏瘦", "偏瘦"elif 18.5 <= bmi < 24:who, nat = "正常", "正常"elif 24 <= bmi < 25:who, nat = "正常", "偏胖"elif 25 <= bmi < 28:who, nat = "偏胖", "偏胖"elif 28 <= bmi < 30:who, nat = "偏胖", "肥胖"else:who, nat = "肥胖", "肥胖"print("BMI 指标为:国际'{0}', 国内'{1}'".format(who, nat))"""请输入身高(米)和体重(公斤)[逗号隔开]: 1.66,66BMI 数值为:23.95BMI 指标为:国际'正常', 国内'正常'"""
圆周率的计算
pi = 0N = 100for k in range(N):pi += (1/ pow(16, k)* (4 / (8 * k + 1) - 2 / (8 * k + 4) - 1 / (8 * k + 5) - 1 / (8 * k + 6)))print("圆周率值是: {}".format(pi))# 圆周率值是: 3.141592653589793
from random import randomfrom time import perf_counterDARTS = 1000 * 1000hits = 0.0start = perf_counter()for i in range(1, DARTS + 1):x, y = random(), random()dist = pow(x**2 + y**2, 0.5)if dist <= 1.0:hits = hits + 1pi = 4 * (hits / DARTS)print("圆周率值是: {}".format(pi))print("运行时间是: {:.5f}s".format(perf_counter() - start))"""圆周率值是: 3.141568运行时间是: 0.25680s"""
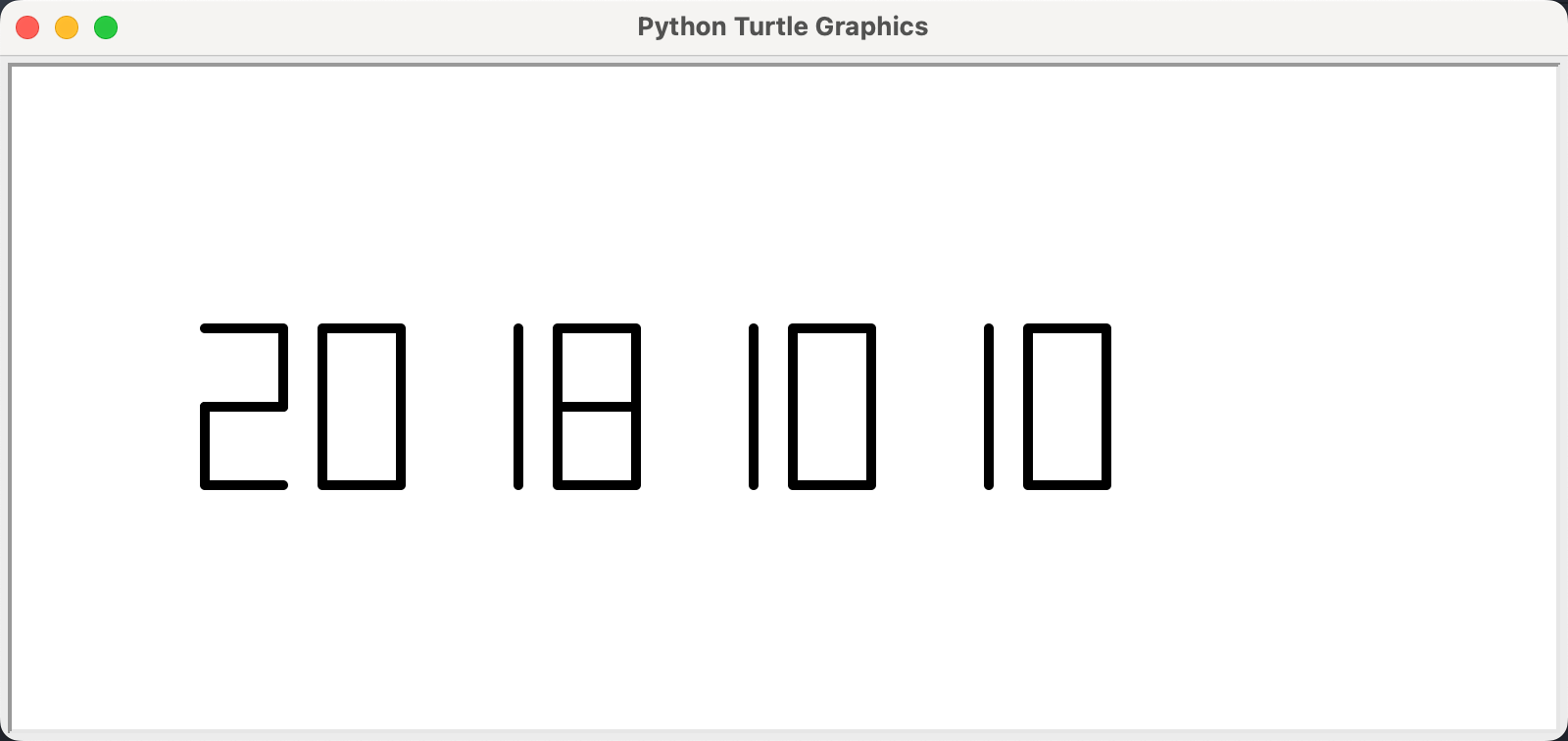
七段数码管绘制
import turtledef drawLine(draw): # 绘制单段数码管turtle.pendown() if draw else turtle.penup()turtle.fd(40)turtle.right(90)def drawDigit(digit): # 根据数字绘制七段数码管drawLine(True) if digit in [2, 3, 4, 5, 6, 8, 9] else drawLine(False)drawLine(True) if digit in [0, 1, 3, 4, 5, 6, 7, 8, 9] else drawLine(False)drawLine(True) if digit in [0, 2, 3, 5, 6, 8, 9] else drawLine(False)drawLine(True) if digit in [0, 2, 6, 8] else drawLine(False)turtle.left(90)drawLine(True) if digit in [0, 4, 5, 6, 8, 9] else drawLine(False)drawLine(True) if digit in [0, 2, 3, 5, 6, 7, 8, 9] else drawLine(False)drawLine(True) if digit in [0, 1, 2, 3, 4, 7, 8, 9] else drawLine(False)turtle.left(180)turtle.penup()turtle.fd(20)def drawDate(date): # 获得要输出的数字for i in date:drawDigit(eval(i)) # 通过eval()函数将数字变为整数def main():turtle.setup(800, 350, 200, 200)turtle.penup()turtle.fd(-300)turtle.pensize(5)drawDate("20181010")turtle.hideturtle()turtle.done()main()
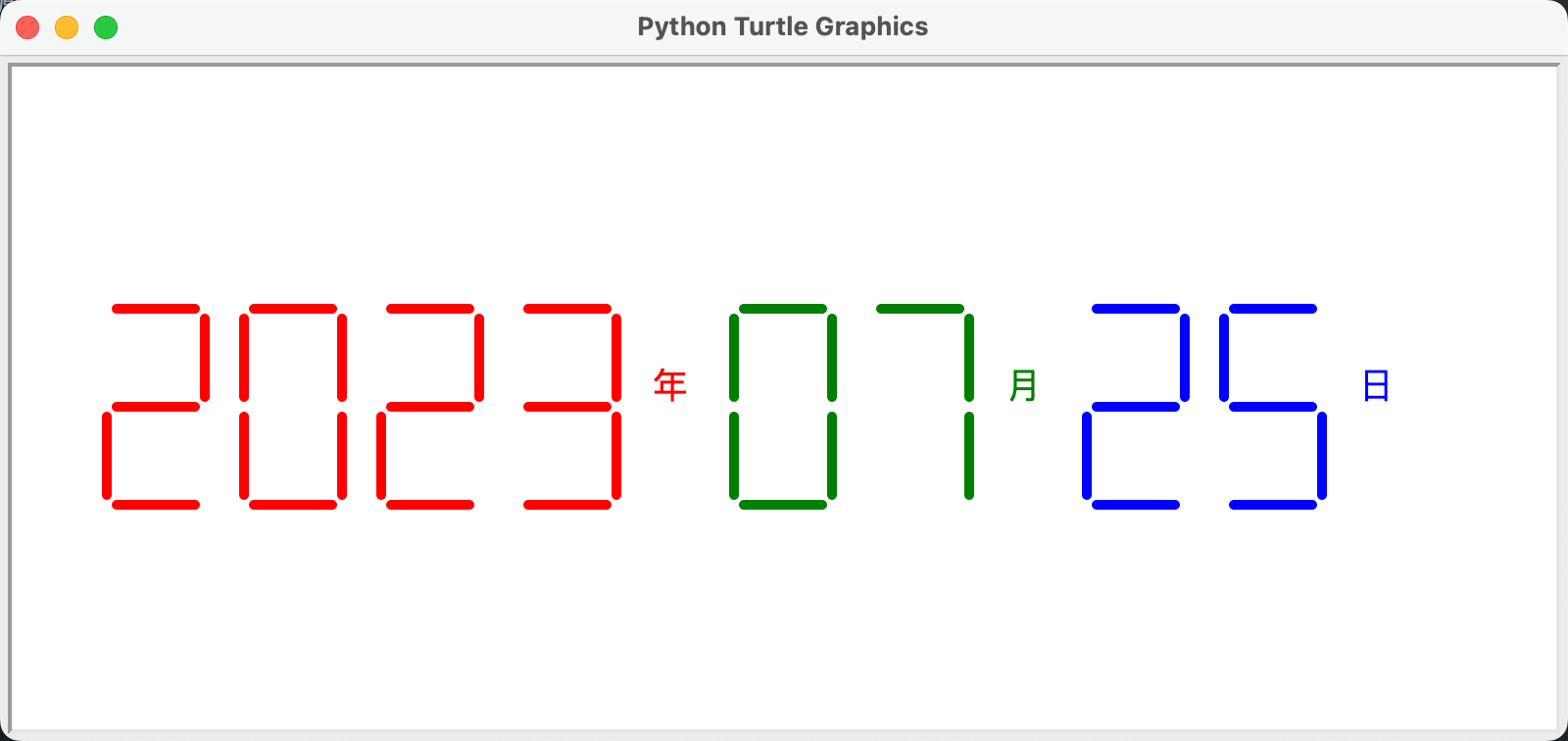
import turtle, timedef drawGap(): # 绘制数码管间隔turtle.penup()turtle.fd(5)def drawLine(draw): # 绘制单段数码管drawGap()turtle.pendown() if draw else turtle.penup()turtle.fd(40)drawGap()turtle.right(90)def drawDigit(d): # 根据数字绘制七段数码管drawLine(True) if d in [2, 3, 4, 5, 6, 8, 9] else drawLine(False)drawLine(True) if d in [0, 1, 3, 4, 5, 6, 7, 8, 9] else drawLine(False)drawLine(True) if d in [0, 2, 3, 5, 6, 8, 9] else drawLine(False)drawLine(True) if d in [0, 2, 6, 8] else drawLine(False)turtle.left(90)drawLine(True) if d in [0, 4, 5, 6, 8, 9] else drawLine(False)drawLine(True) if d in [0, 2, 3, 5, 6, 7, 8, 9] else drawLine(False)drawLine(True) if d in [0, 1, 2, 3, 4, 7, 8, 9] else drawLine(False)turtle.left(180)turtle.penup()turtle.fd(20)def drawDate(date):turtle.pencolor("red")for i in date:if i == "-":turtle.write("年", font=("Arial", 18, "normal"))turtle.pencolor("green")turtle.fd(40)elif i == "=":turtle.write("月", font=("Arial", 18, "normal"))turtle.pencolor("blue")turtle.fd(40)elif i == "+":turtle.write("日", font=("Arial", 18, "normal"))else:drawDigit(eval(i))def main():turtle.setup(800, 350, 200, 200)turtle.penup()turtle.fd(-350)turtle.pensize(5)# drawDate('2018-10=10+')drawDate(time.strftime("%Y-%m=%d+", time.gmtime()))turtle.hideturtle()turtle.done()main()
科赫雪花小包裹
import turtledef koch(size, n):if n == 0:turtle.fd(size)else:for angle in [0, 60, -120, 60]:turtle.left(angle)koch(size / 3, n - 1)def main():turtle.setup(800, 400)turtle.penup()turtle.goto(-300, -50)turtle.pendown()turtle.pensize(2)koch(600, 3) # 0阶科赫曲线长度,阶数turtle.hideturtle()turtle.done()main()
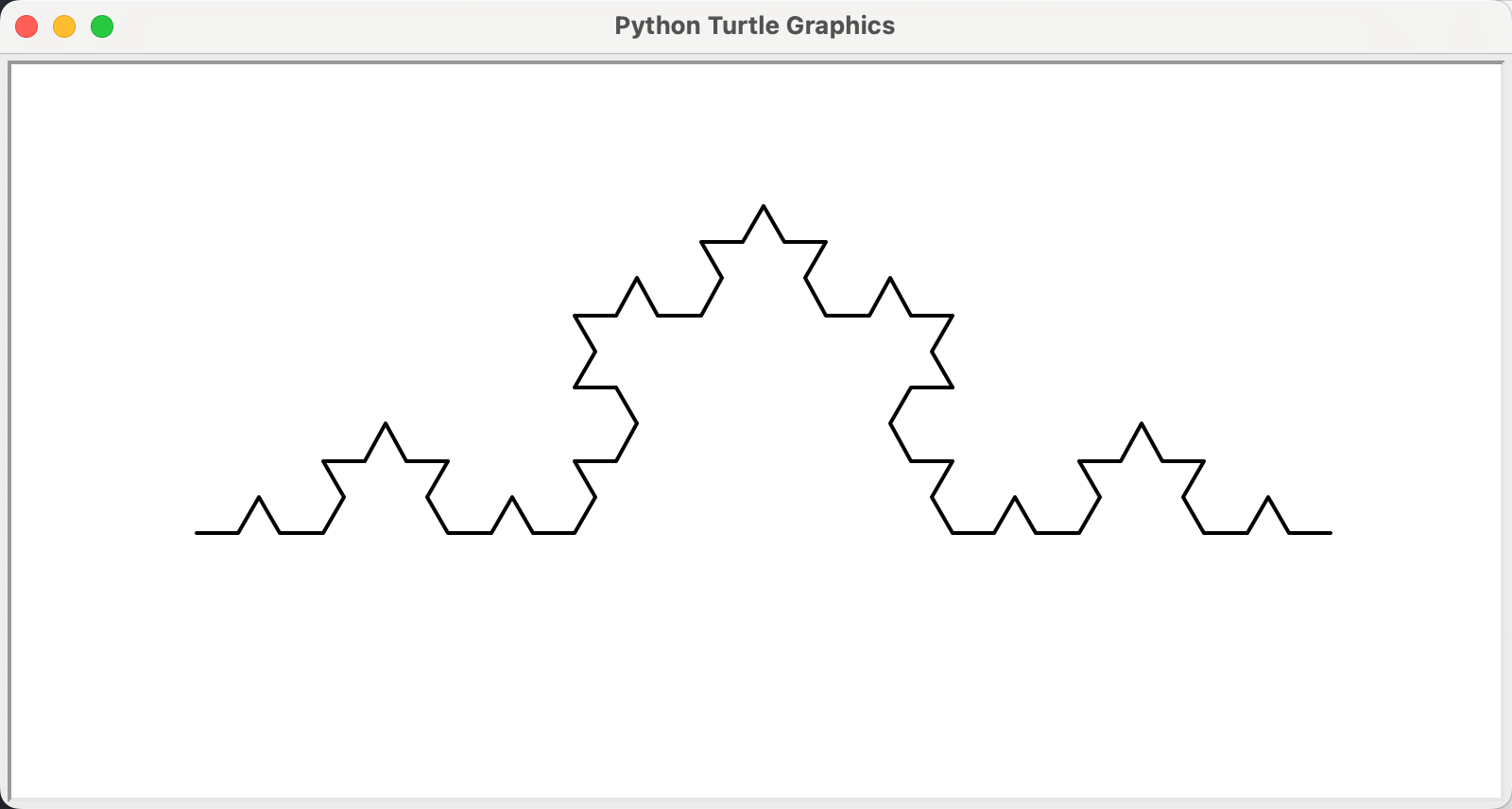
import turtledef koch(size, n):if n == 0:turtle.fd(size)else:for angle in [0, 60, -120, 60]:turtle.left(angle)koch(size / 3, n - 1)def main():turtle.setup(600, 600)turtle.penup()turtle.goto(-200, 100)turtle.pendown()turtle.pensize(2)level = 3 # 3阶科赫雪花,阶数koch(400, level)turtle.right(120)koch(400, level)turtle.right(120)koch(400, level)turtle.hideturtle()turtle.done()main()

基本统计值计算
def getNum(): # 获取用户不定长度的输入nums = []iNumStr = input("请输入数字(回车退出): ")while iNumStr != "":nums.append(eval(iNumStr))iNumStr = input("请输入数字(回车退出): ")return numsdef mean(numbers): # 计算平均值s = 0.0for num in numbers:s = s + numreturn s / len(numbers)def dev(numbers, mean): # 计算方差sdev = 0.0for num in numbers:sdev = sdev + (num - mean) ** 2return pow(sdev / (len(numbers) - 1), 0.5)def median(numbers): # 计算中位数sorted(numbers)size = len(numbers)if size % 2 == 0:med = (numbers[size // 2 - 1] + numbers[size // 2]) / 2else:med = numbers[size // 2]return medn = getNum() # 主体函数m = mean(n)print("平均值:{},方差:{:.2},中位数:{}.".format(m, dev(n, m), median(n)))"""请输入数字(回车退出): 1请输入数字(回车退出): 2请输入数字(回车退出): 3请输入数字(回车退出): 4请输入数字(回车退出): 5请输入数字(回车退出):平均值:3.0,方差:1.6,中位数:3."""
文本词频统计
def getText():txt = open("hamlet.txt", "r").read()txt = txt.lower()for ch in '!"#$%&()*+,-./:;<=>?@[\\]^_‘{|}~':txt = txt.replace(ch, " ") # 将文本中特殊字符替换为空格return txthamletTxt = getText()words = hamletTxt.split()counts = {}for word in words:counts[word] = counts.get(word, 0) + 1items = list(counts.items())items.sort(key=lambda x: x[1], reverse=True)for i in range(10):word, count = items[i]print("{0:<10}{1:>5}".format(word, count))"""the 1138and 965to 754of 669you 550i 542a 542my 514hamlet 462in 436"""
import jiebatxt = open("threekingdoms.txt", "r", encoding="utf-8").read()words = jieba.lcut(txt)counts = {}for word in words:if len(word) == 1:continueelse:counts[word] = counts.get(word, 0) + 1items = list(counts.items())items.sort(key=lambda x: x[1], reverse=True)for i in range(15):word, count = items[i]print("{0:<10}{1:>5}".format(word, count))"""曹操 953孔明 836将军 772却说 656玄德 585关公 510丞相 491二人 469不可 440荆州 425玄德曰 390孔明曰 390不能 384如此 378张飞 358"""
import jiebaexcludes = {"将军", "却说", "荆州", "二人", "不可", "不能", "如此"}txt = open("threekingdoms.txt", "r", encoding="utf-8").read()words = jieba.lcut(txt)counts = {}for word in words:if len(word) == 1:continueelif word == "诸葛亮" or word == "孔明曰":rword = "孔明"elif word == "关公" or word == "云长":rword = "关羽"elif word == "玄德" or word == "玄德曰":rword = "刘备"elif word == "孟德" or word == "丞相":rword = "曹操"else:rword = wordcounts[rword] = counts.get(rword, 0) + 1for word in excludes:del counts[word]items = list(counts.items())items.sort(key=lambda x: x[1], reverse=True)for i in range(10):word, count = items[i]print("{0:<10}{1:>5}".format(word, count))"""曹操 1451孔明 1383刘备 1252关羽 784张飞 358商议 344如何 338主公 331军士 317吕布 300"""
自动轨迹绘制
import turtle as tt.title("自动轨迹绘制")t.setup(800, 600, 0, 0)t.pencolor("red")t.pensize(5)# 数据读取datals = []f = open("data.txt")for line in f:line = line.replace("\n", "")datals.append(list(map(eval, line.split(","))))f.close()# 自动绘制for i in range(len(datals)):t.pencolor(datals[i][3], datals[i][4], datals[i][5])t.fd(datals[i][0])if datals[i][1]:t.rt(datals[i][2])else:t.lt(datals[i][2])t.done()
政府工作报告词云
import jiebaimport wordcloudf = open("新时代中国特色社会主义.txt", "r", encoding="utf-8")t = f.read()f.close()ls = jieba.lcut(t)txt = " ".join(ls)w = wordcloud.WordCloud(width=1000, height=700, background_color="white", font_path="msyh.ttc")w.generate(txt)w.to_file("grwordcloud.png")

import jiebaimport wordcloudf = open("关于实施乡村振兴战略的意见.txt", "r", encoding="utf-8")t = f.read()f.close()ls = jieba.lcut(t)txt = " ".join(ls)w = wordcloud.WordCloud(width=1000, height=700, background_color="white", font_path="msyh.ttc")w.generate(txt)w.to_file("grwordcloud.png")

import jiebaimport wordcloudf = open("新时代中国特色社会主义.txt", "r", encoding="utf-8")t = f.read()f.close()ls = jieba.lcut(t)txt = " ".join(ls)w = wordcloud.WordCloud(width=1000, height=700, background_color="white", font_path="msyh.ttc", max_words=15)w.generate(txt)w.to_file("grwordcloud.png")

import jiebaimport wordcloudf = open("关于实施乡村振兴战略的意见.txt", "r", encoding="utf-8")t = f.read()f.close()ls = jieba.lcut(t)txt = " ".join(ls)w = wordcloud.WordCloud(width=1000, height=700, background_color="white", font_path="msyh.ttc", max_words=15)w.generate(txt)w.to_file("grwordcloud.png")

import jiebaimport wordcloudfrom imageio import imreadmask = imread("fivestart.png")excludes = {}f = open("新时代中国特色社会主义.txt", "r", encoding="utf-8")t = f.read()f.close()ls = jieba.lcut(t)txt = " ".join(ls)w = wordcloud.WordCloud(width=1000, height=700, background_color="white", font_path="msyh.ttc", mask=mask)w.generate(txt)w.to_file("grwordcloudm.png")

import jiebaimport wordcloudfrom imageio import imreadmask = imread("fivestart.png")excludes = {}f = open("关于实施乡村振兴战略的意见.txt", "r", encoding="utf-8")t = f.read()f.close()ls = jieba.lcut(t)txt = " ".join(ls)w = wordcloud.WordCloud(width=1000, height=700, background_color="white", font_path="msyh.ttc", mask=mask)w.generate(txt)w.to_file("grwordcloudm.png")

import jiebaimport wordcloudfrom imageio import imreadmask = imread("chinamap.jpg")excludes = {}f = open("新时代中国特色社会主义.txt", "r", encoding="utf-8")t = f.read()f.close()ls = jieba.lcut(t)txt = " ".join(ls)w = wordcloud.WordCloud(width=1000, height=700, background_color="white", font_path="msyh.ttc", mask=mask)w.generate(txt)w.to_file("grwordcloudm.png")

import jiebaimport wordcloudfrom imageio import imreadmask = imread("chinamap.jpg")excludes = {}f = open("关于实施乡村振兴战略的意见.txt", "r", encoding="utf-8")t = f.read()f.close()ls = jieba.lcut(t)txt = " ".join(ls)w = wordcloud.WordCloud(width=1000, height=700, background_color="white", font_path="msyh.ttc", mask=mask)w.generate(txt)w.to_file("grwordcloudm.png")

体育竞技分析
from random import randomdef printIntro():print("这个程序模拟两个选手A和B的某种竞技比赛")print("程序运行需要A和B的能力值(以0到1之间的小数表示)")def getInputs():a = eval(input("请输入选手A的能力值(0-1): "))b = eval(input("请输入选手B的能力值(0-1): "))n = eval(input("模拟比赛的场次: "))return a, b, ndef simNGames(n, probA, probB):winsA, winsB = 0, 0for i in range(n):scoreA, scoreB = simOneGame(probA, probB)if scoreA > scoreB:winsA += 1else:winsB += 1return winsA, winsBdef gameOver(a, b):return a == 15 or b == 15def simOneGame(probA, probB):scoreA, scoreB = 0, 0serving = "A"while not gameOver(scoreA, scoreB):if serving == "A":if random() < probA:scoreA += 1else:serving = "B"else:if random() < probB:scoreB += 1else:serving = "A"return scoreA, scoreBdef printSummary(winsA, winsB):n = winsA + winsBprint("竞技分析开始,共模拟{}场比赛".format(n))print("选手A获胜{}场比赛,占比{:0.1%}".format(winsA, winsA / n))print("选手B获胜{}场比赛,占比{:0.1%}".format(winsB, winsB / n))def main():printIntro()probA, probB, n = getInputs()winsA, winsB = simNGames(n, probA, probB)printSummary(winsA, winsB)main()"""这个程序模拟两个选手A和B的某种竞技比赛程序运行需要A和B的能力值(以0到1之间的小数表示)请输入选手A的能力值(0-1): 0.5请输入选手B的能力值(0-1): 0.5模拟比赛的场次: 1000竞技分析开始,共模拟1000场比赛选手A获胜548场比赛,占比54.8%选手B获胜452场比赛,占比45.2%这个程序模拟两个选手A和B的某种竞技比赛程序运行需要A和B的能力值(以0到1之间的小数表示)请输入选手A的能力值(0-1): 0.5请输入选手B的能力值(0-1): 0.5模拟比赛的场次: 1000竞技分析开始,共模拟1000场比赛选手A获胜499场比赛,占比49.9%选手B获胜501场比赛,占比50.1%"""
第三方库安装脚本
import oslibs = {"numpy","matplotlib","pillow","sklearn","requests","jieba","beautifulsoup4","wheel","networkx","sympy","pyinstaller","django","flask","werobot","pyqt5","pandas","pyopengl","pypdf2","docopt","pygame",}try:for lib in libs:os.system("pip3 install " + lib)print("Successful")except:print("Failed Somehow")
霍兰德人格分析雷达图
import numpy as npimport matplotlib.pyplot as pltimport matplotlibmatplotlib.rcParams["font.family"] = "Hiragino Sans GB"radar_labels = np.array(["研究型(I)", "艺术型(A)", "社会型(S)", "企业型(E)", "常规型(C)", "现实型(R)", "研究型(I)"]) # 雷达标签,增加一个起始元素以与 angles 数组长度匹配nAttr = 6data = np.array([[0.40, 0.32, 0.35, 0.30, 0.30, 0.88],[0.85, 0.35, 0.30, 0.40, 0.40, 0.30],[0.43, 0.89, 0.30, 0.28, 0.22, 0.30],[0.30, 0.25, 0.48, 0.85, 0.45, 0.40],[0.20, 0.38, 0.87, 0.45, 0.32, 0.28],[0.34, 0.31, 0.38, 0.40, 0.92, 0.28],]) # 数据值data_labels = ("艺术家", "实验员", "工程师", "推销员", "社会工作者", "记事员")angles = np.linspace(0, 2 * np.pi, nAttr, endpoint=False)data = np.concatenate((data, [data[0]]))angles = np.concatenate((angles, [angles[0]]))fig = plt.figure(facecolor="white")plt.subplot(111, polar=True)plt.plot(angles, data, "o-", linewidth=1, alpha=0.2)plt.fill(angles, data, alpha=0.25)plt.thetagrids(angles * 180 / np.pi, radar_labels) # 移除 frac 参数plt.figtext(0.52, 0.95, "霍兰德人格分析", ha="center", size=20)legend = plt.legend(data_labels, loc=(0.94, 0.80), labelspacing=0.1)plt.setp(legend.get_texts(), fontsize="large")plt.grid(True)plt.savefig("holland_radar.jpg")plt.show()

玫瑰花绘制
import turtle as t# 定义一个曲线绘制函数def DegreeCurve(n, r, d=1):for i in range(n):t.left(d)t.circle(r, abs(d))# 初始位置设定s = 0.2 # sizet.setup(450 * 5 * s, 750 * 5 * s)t.pencolor("black")t.fillcolor("red")t.speed(100)t.penup()t.goto(0, 900 * s)t.pendown()# 绘制花朵形状t.begin_fill()t.circle(200 * s, 30)DegreeCurve(60, 50 * s)t.circle(200 * s, 30)DegreeCurve(4, 100 * s)t.circle(200 * s, 50)DegreeCurve(50, 50 * s)t.circle(350 * s, 65)DegreeCurve(40, 70 * s)t.circle(150 * s, 50)DegreeCurve(20, 50 * s, -1)t.circle(400 * s, 60)DegreeCurve(18, 50 * s)t.fd(250 * s)t.right(150)t.circle(-500 * s, 12)t.left(140)t.circle(550 * s, 110)t.left(27)t.circle(650 * s, 100)t.left(130)t.circle(-300 * s, 20)t.right(123)t.circle(220 * s, 57)t.end_fill()# 绘制花枝形状t.left(120)t.fd(280 * s)t.left(115)t.circle(300 * s, 33)t.left(180)t.circle(-300 * s, 33)DegreeCurve(70, 225 * s, -1)t.circle(350 * s, 104)t.left(90)t.circle(200 * s, 105)t.circle(-500 * s, 63)t.penup()t.goto(170 * s, -30 * s)t.pendown()t.left(160)DegreeCurve(20, 2500 * s)DegreeCurve(220, 250 * s, -1)# 绘制一个绿色叶子t.fillcolor("green")t.penup()t.goto(670 * s, -180 * s)t.pendown()t.right(140)t.begin_fill()t.circle(300 * s, 120)t.left(60)t.circle(300 * s, 120)t.end_fill()t.penup()t.goto(180 * s, -550 * s)t.pendown()t.right(85)t.circle(600 * s, 40)# 绘制另一个绿色叶子t.penup()t.goto(-150 * s, -1000 * s)t.pendown()t.begin_fill()t.rt(120)t.circle(300 * s, 115)t.left(75)t.circle(300 * s, 100)t.end_fill()t.penup()t.goto(430 * s, -1070 * s)t.pendown()t.right(30)t.circle(-600 * s, 35)t.done()


若有收获,就点个赞吧
0 人点赞
