本篇将会给大家介绍一些基础的推荐算法,并以其中基于物品的协同过滤算法为例,详细讲解如何找到用户最感兴趣的内容,从而实现个性化精准推送。文中介绍的推荐算法大部分源自于《推荐系统实践》一书,书中还详细讲述的通过分析用户行为,形成用户标签并构建用户画像的详细过程,大家可以结合书中的要点和本篇实践一起了解。
一. 几种推荐算法
1.基于内容推荐算法
基于用户感兴趣的物品A,找到和A内容信息相近的物品B
(1)找到物品A的内容信息
(2)找到与内容信息相近的物品B
运用:这种推荐算法多数运用在简单的推荐列表上,当用户看了物品A立刻展示推荐关联的物品B,不需要通过大量计算反馈。但由于其局限性并不能精准推荐出用户所喜欢的内容。
2.基于用户的协同过滤算法(UserCF)
这种算法给用户推荐和他兴趣相似的其他用户喜欢的物品。
基于用户的协同过滤算法主要包括两个步骤:
(1)找到和目标用户兴趣相似的用户集合。
(2)找到这个集合中的用户喜欢的,且目标用户没有听说过的物品推荐给目标用户。
运用:UserCF的推荐结果着重于反映和用户兴趣相似的小群体的热点,即更社会化,反映了用户所在的小型兴趣群体中物品的热门程度
3.基于物品的协同过滤算法(ItemCF)
这种算法给用户推荐和他之前喜欢的物品相似的物品。
基于物品的协同过滤算法主要分为两步:
(1)计算物品之间的相似度。
(2)运用:ItemCF的推荐结果着重于维系用户的历史兴趣,即更个性化,反映了用户自己的兴趣传承
4.隐语义模型算法(LFM)
通过隐含特征联系用户兴趣和物品
LFM是一种基于机器学习的方法,具有比较好的理论基础。这个方法和基于邻域的方法相比有更强的理论基础、离线计算空间、时间的复杂度,并且可以实现在线实时推荐。
5.其他推荐算法
(1)基于图的推荐算法
其基本思想是将用户行为数据表示为一系列的二元组。基于用户行为二分图,给用户u推荐物品,可以转化为计算用户顶点u和与所有物品顶点i之间的相关性,然后取与用户没有直接边相连的物品,按照相关性的高低生成推荐列表。
(2)基于关联规则的推荐
反映一个事物与其他事物之间的相互依存性和关联性,常用于实体商店或在线电商的推荐系统:通过对顾客的购买记录数据库进行关联规则挖掘,最终目的是发现顾客群体的购买习惯的内在共性。
(3)基于知识推荐
使用用户知识和产品知识, 通过推理什么产品能满足用户需求来产生推荐。这种推荐系统不依赖于用户评分等关于用户偏好的历史数据, 故其不存在冷启动方面的问题。基于知识的推荐系统响应用户的即时需求, 当用户偏好发生变化时不需要任何训练。
二. 选择适合的算法
根据使用场景选择不同的算法,如果是为简单的物品或者商品详情页底部设计推荐功能,即可使用“基于内容推荐算法”,根据当前物品的内容信息推荐相关的物品,当然这个并非是个性化推荐,但确实使用最广的一种推荐方式。若你的网站是做知识培训的,那可以尝试构建基于知识的推荐,这种推荐方式根据用户需求及用户所处知识阶段进行推荐,更贴合所在场景。
而本篇我主要介绍“基于物品的协同过滤算法”,这个算法与“基于用户的协同过滤算法”共同被称为“基于邻域的协同过滤算法”。下面,我们对这类算法进行简单的介绍。
1.基于邻域的协同过滤算法
从字面上理解“邻域”在数学上指的是“邻域是一个特殊的区间,以点a为中心点任何开区间称为点a的邻域,记作U(a)”,我们可以简单的理解为某个集合点中的左右相邻区间。而“协同过滤”在百度百科上解释为“利用某兴趣相投、拥有共同经验之群体的喜好来推荐用户感兴趣的信息”。那么“基于邻域的协同过滤算法”总结一下就是基于某个维度的相邻区间中利用兴趣相投或共同经验的群体的喜好,找到用户感兴趣的信息。
从某个维度,我们常用用户或者物品所组成的集合区间,所以基于邻域的算法分为两大类,一类是基于用户的协同过滤算法,另一类是基于物品的协同过滤算法。而基于邻域的算法是推荐系统中最基本的算法,该算法不仅在学术界得到了深入研究,而且在业界得到了广泛应用。非常多的个性化推荐算法多使用或混合使用了基于领域的协同过滤算法。可能一些大厂会在这个算法的基础上加入机器学习的理念,克服这个算法本身的缺点。
2.用户画像与基于邻域的推荐算法
大家一定记得上一篇向大家介绍了用户画像,我们通过用户行为分析,拆解成用户标签,并组合成了用户画像。而利用该用户画像,我们就可以使用基于邻域的推荐算法,因为这个算法最核心的一步就是找到用户的兴趣点。
而我们的用户画像就可以满足这个要求,我们可以通过用户画像计算用户之前的相似度,再推荐另外一个用户感兴趣的内容,这就是“基于用户的协同过滤算法”;我们也可以通过用户画像计算出用户感兴趣的物品相似的物品,这就是“基于物品的协同过滤算法”。
再者我们可以混合一起使用。不管怎么说,我在上一篇就提到了构建用户画像的好处,此时无论选择哪种邻域推荐算法均可使用。而对于我自己,这次选择了选择给大家介绍的是“基于物品的协同过滤算法”。如果对其他算法也有兴趣,强烈推荐大家可以看看《推荐系统实践》一书。
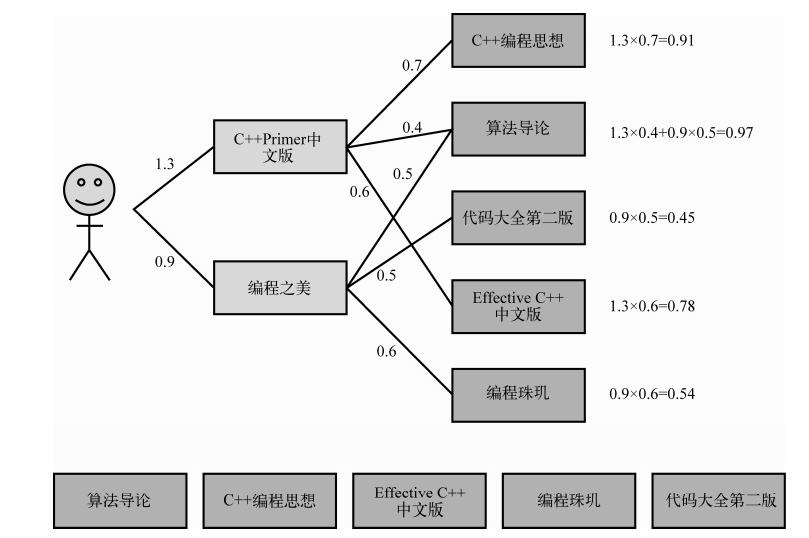
图片引用自《推荐系统实践》 项亮 编著
3.基于物品的协同过滤算法
基于物品的协同过滤算法是目前业界应用最多的算法。无论是亚马逊网,还是Netflix、Hulu、YouTube,其推荐算法的基础都是该算法。我在前面提到,这个算法主要思路是用户推荐和他之前喜欢的物品相似的物品。在上一篇文章,我们已经把用户之前的浏览行为都记录下来,通过分析和标签化,形成了用户画像。那么其实我们已经完成了第一步,掌握用户之前喜欢的内容。那么第二步即使计算物品相似程度,找到最为相似的物品形成个性化的推荐,再通过推送系统触达用户。下面为大家详细讲解计算的过程:
- 找到用户感兴趣的物品
- 与推荐的物品列表逐个物品进行相似度计算
- 选择相似度最高的物品,并推送给用户
首先如何找到用户感兴趣的物品,在上一篇我们是通过把内容标签化,并把标签赋予用户。那么我们从用户画像中取出一组与推荐物品相关的用户标签。即想给用户推荐商品,那么取出与商品相关的一组用户标签,例如是用户A(茶叶,铁观音,清香,100-200元/斤,产地福建,2018新茶,….)。然后我们在取出待推荐的物品列表,以同样标签化的方式整理,如下图:
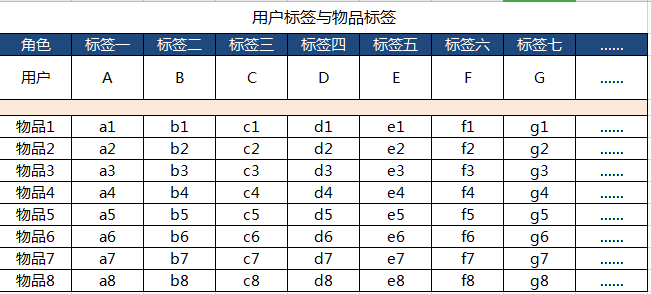
然后,我们再计算用户标签与物品标签之间的相似度,找到与用户标签最为相似的物品。此时我们会使用余弦公式进行计算。余弦公式计算的结果会是余弦夹角,夹角越小则相似度越高,通过计算我们就能用余弦夹角来反应相似度关系。
4.余弦相似公式的运用
向量的余弦相似度公式和我们在三角函数中学的余弦定理有所不同,但我们在数学中计算向量夹角的时候就学习过。当有两个向量a和b时,此时我们计算这两个向量的夹角会使用到“向量的余弦值等于向量的乘积/向量绝对值的乘积”
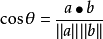
若把向量拓展到多维度A=(A1,A2,A3,…An),B=(B1,B2,B3,…Bn),此时获得如下余弦相似度公式
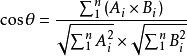
把公式运用到我们上述情况中,则用户的标签则是向量A,物品的标签则是向量B。我们可以通过计算余弦值,确定相似度。余弦相似度公式还常常运用于计算文本相似度。将两个文本根据他们词,建立两个向量,计算这两个向量的余弦值,就可以知道两个文本在统计学方法中他们的相似度情况。实践证明,这是一个非常有效的方法。那么下面我们举个例子具体尝试下。假设用户要买房,那么我们可以推荐什么房子给他。
为大家详细讲述下计算方法:
- 列出用户的标签和用于比较物品的标签。
- 列出所有词,即用户标签和物品标签中所有的词,重复/同范围的词只需列一遍,不同的词需要逐个列出。
- 计算词频,即用户标签和物品标签在所有词中出现的次数,若出现则为1次,未出现则为0次。如所有词中“成屋”,在用户标签中出现,则用户的词频为1;在物品中未出现,则物品的词频为0。
- 把用户和物品的词频组成向量A和向量B
- 代入余弦相似公式计算向量A与向量B的夹角,结果即为相似度。
下面我用excel为大家模拟计算上图的结果:
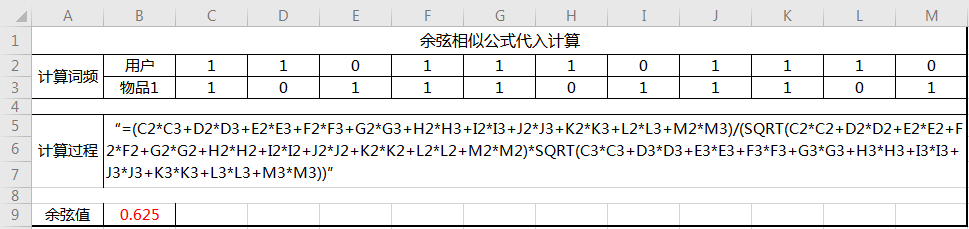
此致我们完成了对一组用户与物品的相似度计算,后续只需要把物品1轮流替换成需要比对的物品即可,完成后得到用户与一组物品的相似度。大家其实算下来有感觉到,余弦相似公式在计算标签的运用上视乎有些“浪费”,因为不管怎么算,用户的词频只会是1和0。所以可以看出余弦相似公式在计算文章内容的相似度或者某些元素非可控集合的相似度中更能突显出其价值。文章中某个关键词出现5次,那么该关键词的词频将会是5,计算结果将会大大的不同。
那么对于我们上面介绍的方法,我们也是可以把词频拿来灵活运用的,因为词频就类似于权重,我们可以通过调整词频来达到提高某个标签的权重。
如上述情况,用户对城市极为敏感,那么我们可以把城市的词频从1提升到2或3。如果是某些必须相同的标签,我们可以在提供匹配的物品列表中先进行筛选。其中可以灵活运用的方式还有很多很多,等待大家的挖掘和探索。
三. 实践中对算法的改造
细心的朋友可能会发现,我这里使用的方法和传统意义上的基于物品的协同过滤算法有所不同,传统基于物品的协同过滤算法不会直接使用用户标签,而是提前维系好物品与相似物品之前的相似度关联。而再用用户行为判断用户对当前物品的喜好度。
也就是说,传统的基于物品协同过滤算法,即便没有用户,物品与推荐的物品就已经有了相似度推荐的关系存在。
这也是ItemCF非常大的缺点之一:如果网站的物品很多,那么计算物品相似度矩阵代价很大。
而我使用的是改造版本,即是把物品赋予用户标签的与物品计算相似度。这样的好处是我不用维系庞大的物品相似度关系表,同时具有更大的灵活性。当用户产生浏览行为后,根据分析用户的标签,再进行相似度计算。
这个时候大家也就会有疑问,如果没有提前准备好物品相似度矩阵。那么用户在第一次进来的时候,或者用户行为不足以分析的时候。我们就无法给用户进行推荐了。确实是的,这也是这个方法存在的缺陷,在推荐系统中称为“冷启动”。
四. 推荐系统冷启动问题
正如我上面描述的情况,用户第一次使用或者用户行为不足的时候,我们无法通过用户行为计算出用户的标签,也讲无法通过基于邻域的协同过滤算法进行推荐/个性化推送。那么此时我们该怎么解决这个问题呢?其实冷启动分为三种,即为用户冷启动,物品冷启动,系统冷启动。我们刚才所描述的问题是用户冷启动,也是最常见的一种。
1.用户冷启动
若要解决用户冷启动问题,我们只能利用其他方式获得用户的兴趣,暂时替代用户的行为。大家一定记得上一篇我在讲述获取用户画像的原始数据中提到过,我们可以获取用户的信息。那么对于这个问题我们就可以用以下的方法:
- 使用用户信息:例如用户注册信息等
- 使用合适的物品启动用户兴趣:用合适的物品去试探用户兴趣
当以上方式获得的信息再进过算法推荐给用户后,用户只要产生了交互,那么暨产生了用户行为。
2.物品冷启动
物品冷启动常见的场景是将新的物品推荐给可能对它感兴趣的用户这一问题,新上架的物品或信息如何能快速投递给感兴趣的用户,我们可以通过以下两个方法解决:
- 新上架的物品运用于基于物品过滤协同算法,并提高权重
- 利用物品内容信息,提取内容的关键词(TF-IDF算法),再通过物品推算算法呈现。
3. 系统冷启动
系统冷启动多见于新开发的网站上设计个性化推荐系统,此时物品/内容少,用户少。很多算法无法奏效。那么在这个时候,只能通过专家作用,即通过人工标记的方式制定类别和标签,人工分类,人工制定权重等方式进行。后续用户行为及物品产出后,即可更换替代。
4.实现个性化精准推算
上述讲了这么多都是如何通过用户画像找到用户感兴趣的内容/物品,那么终于来到精准推送这一步了。用户已经选定好了,用户喜欢的物品/内容也选好了。那么这个时候就可以使用推送系统把内容触达用户了。在这个过程中所需要注意的是以下几个问题:
- 推送系统的用户和用户画像的用户是一致的,即不能算出推送内容却找不到推给谁。这个时候回顾第二篇,使用设备号作为网站对用户的唯一标示就显得更为重要的。
- 选择活跃用户推送,冷启动实现难度较高。所以尽量在用户产生浏览行为后的计算结果推送给用户,这样能避免推送内容不是用户习惯的情况。
- 推送文案可以参考用户标签,既然用户标签是通过用户浏览行为计算出来的。那么用户对标签内容会更为敏感。也许推送文案对勾起用户兴趣帮助更大。
- 推送着陆后的用户行为,也是用户画像用户行为来源之一。用户点击推送消息进到内容页所产生的用户行为也将会作为构建用户画像的行为来源之一。同时用户对推送内容的反馈是可以作为用户喜好度的调节系数之一,这个暂不展开详细说了,大家有兴趣可以去研究看看。
- 推荐的物品/内容尽量是用户没看过的。因为不管使用什么算法计算相似度,很可能出现的结果是用户看过/用户喜欢的内容与用户标签相似度最高。所以进行计算之前,可以考虑把用户过往浏览过的内容/推送过的内容筛掉。
完成以上这些步骤,也就可以基本上实现了个性化的精准推送了,但其实还有很多需要我们去尝试和研究的,例如用户活跃度对协同过滤算法计算的影响,以及用户活跃度对推送的影响。用户的兴趣随着时间的逐步衰减,推送的点击意愿随着用户沉默的时间越来越低;等等….这里就不展开详细说明了,如果大家有兴趣,我们可以再进行详细交流。
本篇总结
本篇主要为大家介绍了如何通过推荐算法,实现个性化的精准推送。总结成以下几点:
- 介绍几种基本的推荐算法:基于内容推荐算法、基于邻域协同过滤算法、隐语义模型算法等等。
- 介绍了用户画像与基于邻域的推荐算法的关系,把上一篇与本篇链接起来。
- 重点介绍了基于的物品协同过滤算法
- 通过余弦相似度公式计算用户标签与物品相似度
- 推荐算法冷启动问题
- 实现个性化精准推送需要注意的问题
下一篇讲会为大家介绍推送运营面知识,关于推送时间、人物、文案的思考。
转载自 人人都是产品经理 作者 @番茄那只羊 原文地址

若有收获,就点个赞吧
0 人点赞
