推荐算法是指利用用户的一些行为,通过一些数学算法,推测出用户可能喜欢的东西。如何为产品选择其合适的推荐算法呢?

一、常见推荐机制/算法
1.基础推荐机制
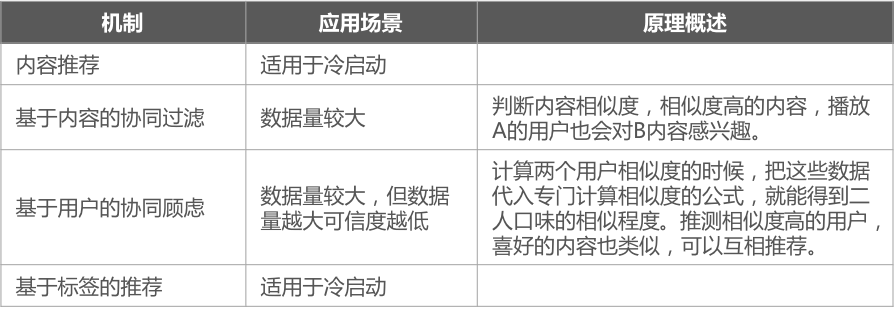
协同过滤的风险:
尽管协同过滤技术在个性化推荐系统中获得了极大的成功,但随着产品结构、内容的复杂度和用户人数的不断增加,协同过滤技术的一些缺点逐渐暴露出来。主要有以下三点:
- 稀疏性(sparsity):在许多推荐系统中,每个用户涉及的信息量相当有限,在一些大的系统如亚马逊网站中,用户最多不过就评估了上百万本书的1%~2%。造成评估矩阵数据相当稀疏,难以找到相似用户集,导致推荐效果大大降低。
- 扩展性(scalability):“最近邻居”算法的计算量随着用户和项的增加而大大增加,对于上百万之巨的数目,通常的算法将遭遇到严重的扩展性问题。
- 精确性(accuracy):通过寻找相近用户来产生推荐集,在数量较大的情况下,推荐的可信度随之降低。
2. 经典算法

混合推荐算法:
没有哪种推荐技术敢说自己没有弊端, 往往一个好的推荐系统也不是只用一种推荐技术就解决问题, 往往都是相互结合来弥补彼此的不足, 常见的组合方式如下
- 混合推荐技术: 同时使用多种推荐技术再加权取最优;
- 切换推荐技术: 根据用户场景使用不同的推荐技术;
- 特征组合推荐技术: 将一种推荐技术的输出作为特征放到另一个推荐技术当中;
- 层叠推荐技术: 一个推荐模块过程中从另一个推荐模块中获取结果用于自己产出结果
综上所有的推荐策略和算法,大致可以分为以下常见的推荐策略:
- 基于内容的推荐;
- 协同过滤推荐;
- 混合推荐;
- 流行度推荐;
- 其他更高级的。
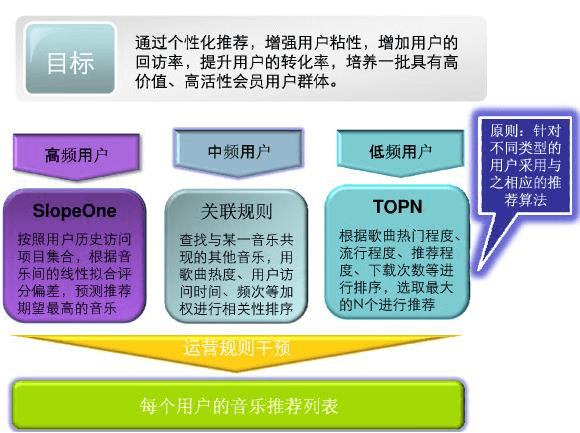
二、重要事项
1.上线前评估
离线评估是指在发布之前,需要去检验典型的bad case 是否解决。是否达成一开始的目标,如果没有,则需要继续调整对应算法,直到能够明显解决问题。
灰度上线则也是稳妥的措施。一开始推荐系统一定是充满了各种问题,所以为了解决这个问题,刚开始上线一定不能直接全量上线。正确的做法是,灰度上线一段时间期间,快速的根据用户反馈迭代算法,再考虑全量上线。
用户反馈的方案包括但不限于:用户问卷,负反馈操作入口。
2.ABtest
推荐和搜索一样,本身极大依赖参数的配置。而这些参数的配置并没有通用的法则,同时也依赖各个平台自身具体的情况,只能在了解其原理的基础上,不断迭代摸索。在算法迭代的过程中,能够测试其效果是算法迭代的核心。只有能同时在线上部署多套搜索算法,并且监控其效果,推荐的迭代和改进才能展开。而这一切的基础,正是一个看不见的功能:AB test机制。
总结
- 推荐算法是需要不断完善的,如果开始没有数据必定会结果不精确;需要一个可以不断回收数据、验证算法的推荐机制。
- 一款产品如果希望基于同好社交来做音乐推荐,则类似基于用户的协同过滤,需要通过指标找到相同的用户。当前是直接给相同的用户推荐某一个推荐规则,而下一步则是通过算法精准推荐内容。
- tip:注意降低用户的尝新成本。首次推荐的内容做到准确比较难,需要从视觉、交互体验、反馈结果等多角度说服用户推荐是有效的,推荐算法的首次展示变得很重要,避免推荐黑箱。
- 风险:协同过滤进行用户分群的指标否可以沿用,但需要注意冷启动阶段的推荐算法是否可以具备可拓展性,即从研发成本角度考虑是否要做一个可持续优化的架构,而不是当用户数据涌入后推翻之前的全部假设。
从“音乐推荐的价值”角度考虑,如何设计推荐算法指标?
用户角度:
- 听到当下需要的歌(指标-与需求场景是否匹配)
- 听到喜欢的歌(指标-是否是喜欢的歌)
- 产生新鲜感和惊喜(指标-是否产生新鲜感和惊喜)
产品角度:
- 提升粘性,延长使用时间(监测粘性-粘性指标-影响粘性的指标)
- 降低流失,防止用户在版权缺失的情况下转到连接蓝牙模式(监测流失-流失指标-防止流失&流失召回的指标)
- 成为传播点,让用户在VUI场景下仍然能保证较好的听歌体验
参考文献
https://www.cnblogs.com/xuanku/p/recsys.html 常见推荐算法科普
http://www.woshipm.com/pd/683874.html 推荐策略设计的Notes
http://www.woshipm.com/pd/267484.html 懂你的推荐算法,推荐逻辑是怎样的?
https://blog.csdn.net/u010670689/article/details/71513133 5类系统推荐算法,非常好使,非常全
http://www.infoq.com/cn/articles/recommendation-algorithm-overview-part01 推荐算法综述
https://blog.csdn.net/myboyliu2007/article/details/19212381?utm_source=tuicool Spark0.9分布式运行MLlib的协同过滤
https://blog.csdn.net/fishineye/article/details/69502068 用Python开始机器学习(9:推荐算法之推荐矩阵
https://www.cnblogs.com/silencestorm/p/8512504.html 关于topN问题的几种解决方案
https://blog.csdn.net/whaoxysh/article/details/19038453 Slope one—个性化推荐中最简洁的协同过滤算法
http://www.cppblog.com/AutomateProgram/archive/2010/07/19/120790.html 协同推荐算法实践之Slope One的介绍
https://blog.csdn.net/s1162276945/article/details/77531123 隐式/显式反馈
http://www.woshipm.com/pd/618662.html 关于个性化推荐算法及应用场景的几点思考
https://blog.csdn.net/w5688414/article/details/78652159?locationNum=7&fps=1 Deep Learning based Recommender System: A Survey and New Perspectives (3)
Yi Zheng, Cailiang Liu, Neural Autoregressive Collaborative Filtering for Implicit Feedback, 2016
本文由 @钢镚儿yu 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于CC0协议
转载自 人人都是产品经理 作者 @钢镚儿yu 原文地址

若有收获,就点个赞吧
0 人点赞
