- 分享主题:Transfer Learning, Domain Adaptation, NLP, Explicit Feature Distribution Alignment, Adversarial
- 论文标题:STAN: Adversarial Network for Cross-domain Question Difficulty Prediction
- 论文链接:https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=9679059
1.Summary
This is a paper to solve the problem of question difficulty prediction (QDP). Although there are many university courses, only a few popular courses are often selected by many students, while many courses are not selected by many students. For those popular courses, because there are many students majoring, the question difficulty of those courses can be obtained according to the students’ answers. In such a rich dataset, the training model can be used to predict the difficulty of new questions in these courses. For those unpopular courses, only a small number of students have done the existing questions, so it is difficult to determine the question difficulty, and the new question can not predict the difficulty. In order to solve this problem, this paper proposes a model called STAN. STAN uses transfer learning to help the question difficulty prediction of those unpopular courses. In addition, in order to improve the effect of the model, this paper improves the feature extractor. The difficulty of a problem can be measured by the difficulty of stimulus and task. Using this point, the feature extractor is improved. In order to deepen my understanding of this paper, I can read some QDP related papers.2.你对于论文的思考
这是一篇关于question difficulty prediction (QDP)的文章,为了预测那些冷门课程的问题难度,这篇文章提出了STAN模型,利用迁移学习把热门课程的知识迁移到冷门课程,整个模型由特征提取器、难度标签预测器以及域标签判别器组成。与一般迁移方式不同的,STAN先是利用热门课程的数据预训练特征提取器以及难度标签预测器,然后得到冷门课程问题的伪标签,再进行数据采样,尽可能保证两个域的数据标签分布相同,之后再进行域对抗迁移学习,在域标签判别时,难度标签也会作为特征,以此进行对齐,这样一来,就能帮助条件分布的对齐,此外文章还对特征提取器做了改进,能得到比以往方法更加准确的伪标签。3. 其他
3.1 解决的问题
如下图所示,只有小部分热门课程被许多学生选修,而许多课程选修的人数比较少,这样一来,那些冷门课程的学生答题数据会比较少,预测问题难度也会比较困难。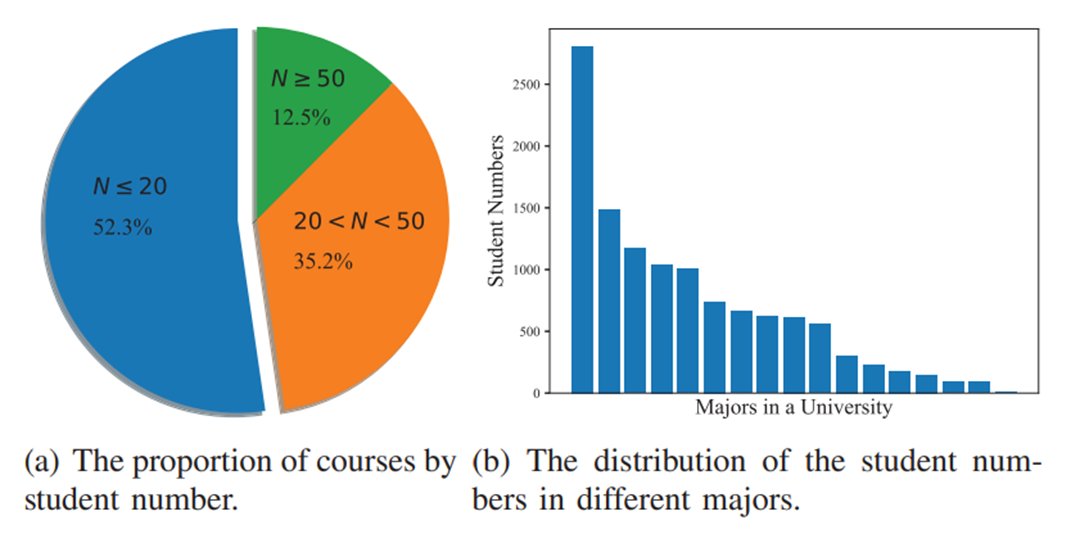
3.2 STAN模型
3.2.1训练流程
(1)用源域数据训练问题难度预测模型,然后用这个训练好的模型来预测目标域数据的标签;
(2)根据上一步得到的伪标签,对源域数据和目标域数据进行采样;
(3)用采样好的数据进行域对抗迁移学习,同时用源域中采样出来的数据对模型进行fine-tuning。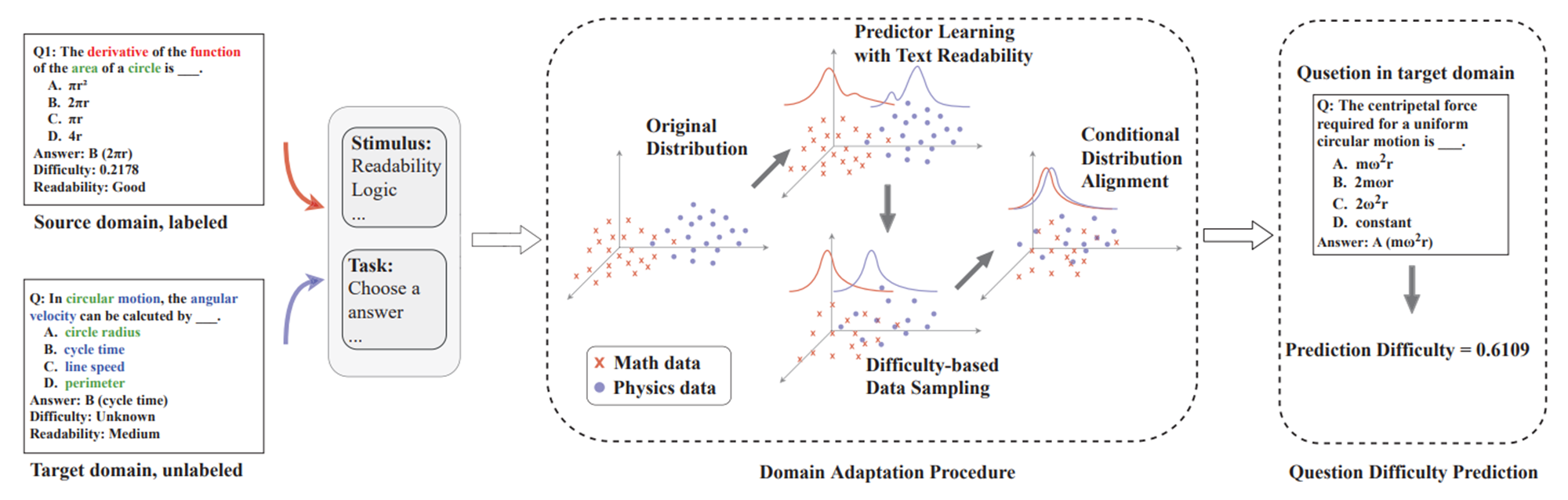
3.2.2 QDP预测
为了提高预测效果,本文对特征提取器进行了改进,将一个问题的难度分为了两部分,分别是题干语义难度和任务难度。
流程如下:
(1)Question Text Encode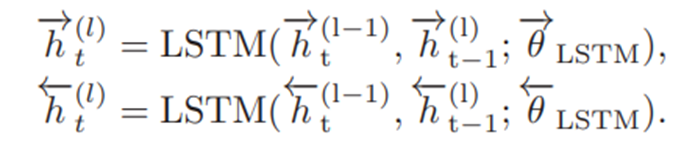
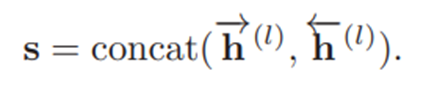
(2)Readability Features
使用StanfordCoreNLP toolkit对Tokenization(文本标记), part-of-speech tagging(词性标记), syntax parsing(语法分析)提取特征。
(3)Stimulus Difficulty Module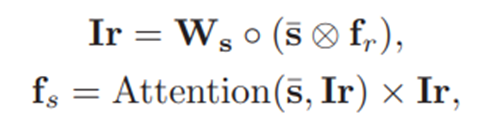
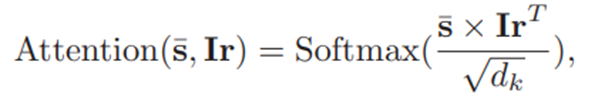
(4)Task Difficulty Module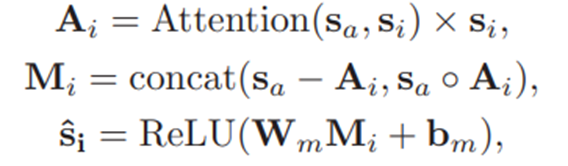
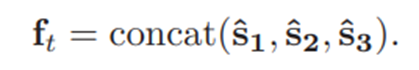
(5)Readability-Enhanced Difficulty Prediction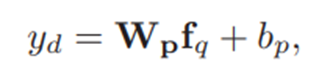
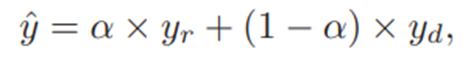
3.2.3 数据采样
假设ymin和ymax分别为源域和目标域的最低和最高问题难度,在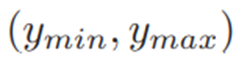 范围内均匀的取N个数
范围内均匀的取N个数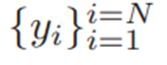 ,在
,在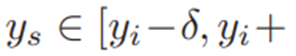
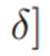 范围内分别在两个域上取数,其中σ取值如下:
范围内分别在两个域上取数,其中σ取值如下: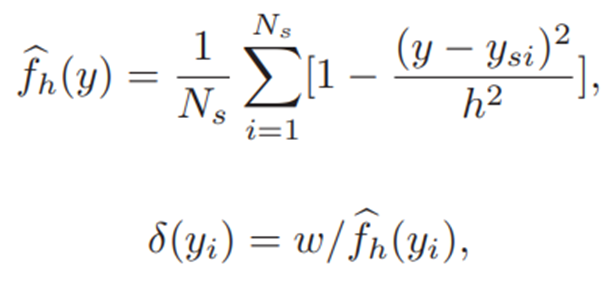
这样一来,就能从下图中的左边的情况转化为右边的情况,也就是难度标签的分布能变得比较相似。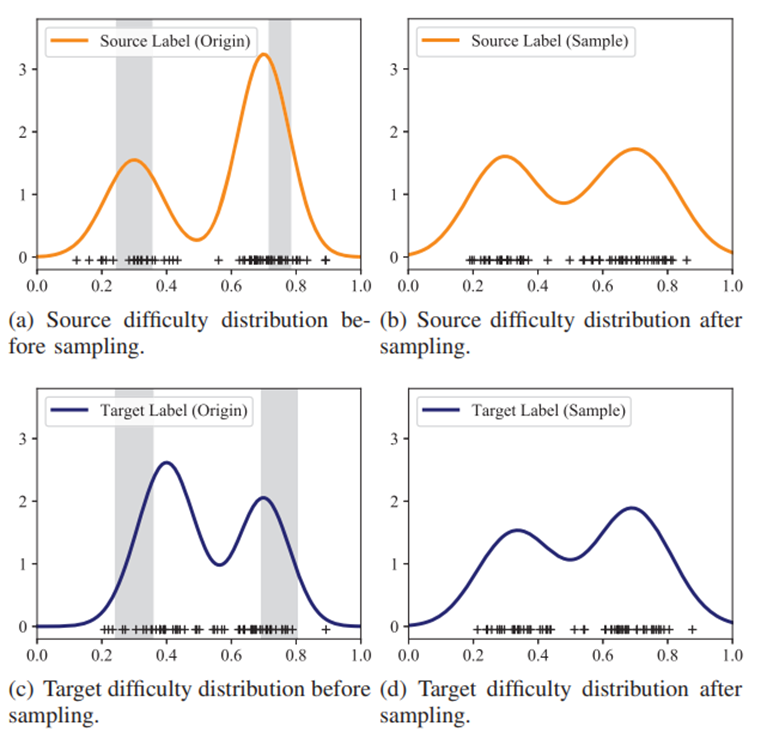
3.2.4 迁移学习
为了预测冷门课程的问题难度,可以使用迁移学习,把热门课程的数据里的知识迁移到冷门课程中,比如下图中的两道题,一道数学题,一道物理题,绿字部分是两道题的公共名词,而红字和蓝字各自领域的名词,显然边缘概率分布不太相同,迁移学习便可以帮助解决这个问题。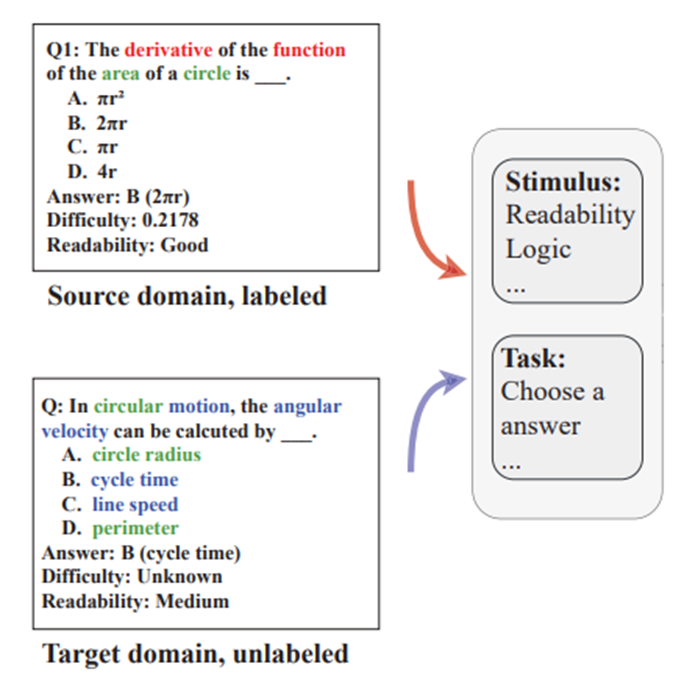
如下图所示,用了对抗的方法对齐两个域的标签。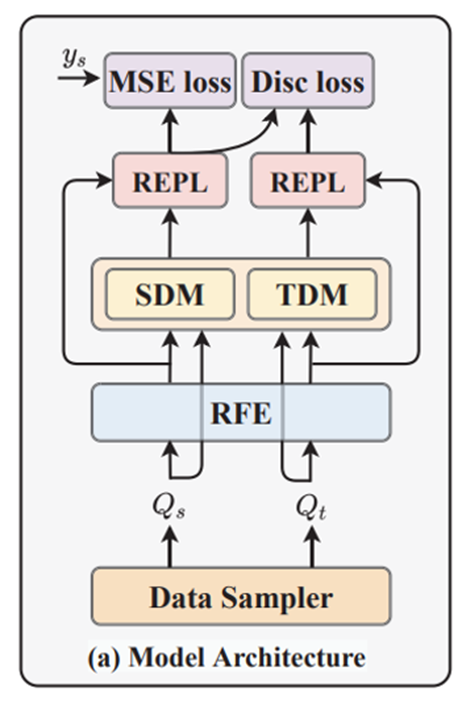
损失函数如下所示: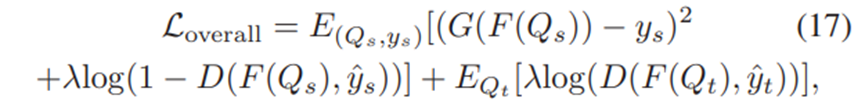
3.3 实验
数据集: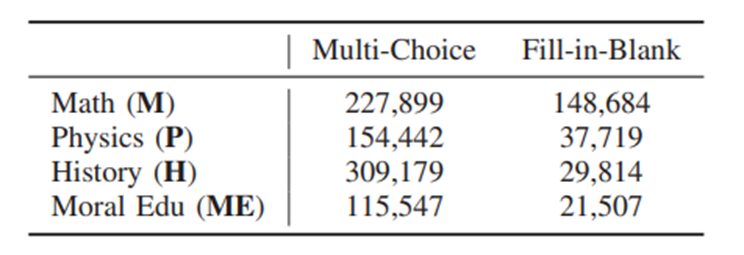
(1)与baseline的对比: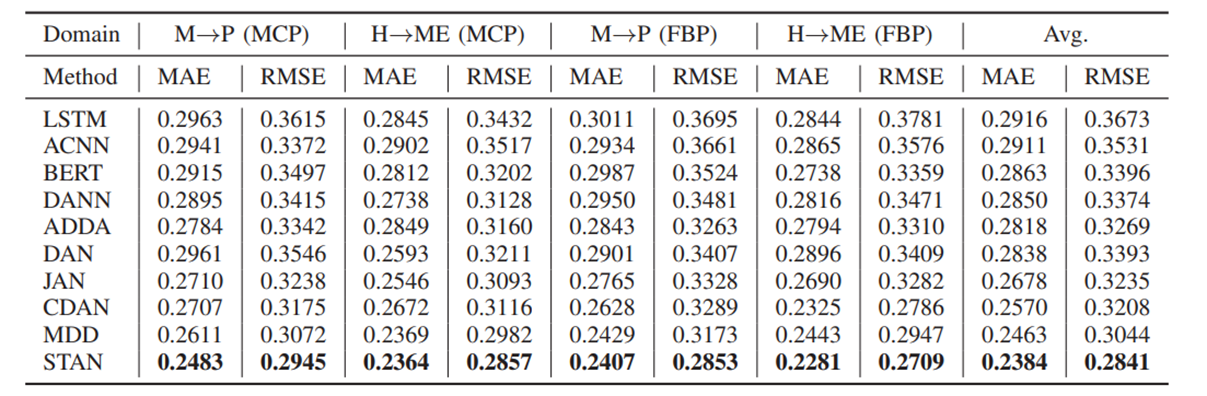
(2)消融实验: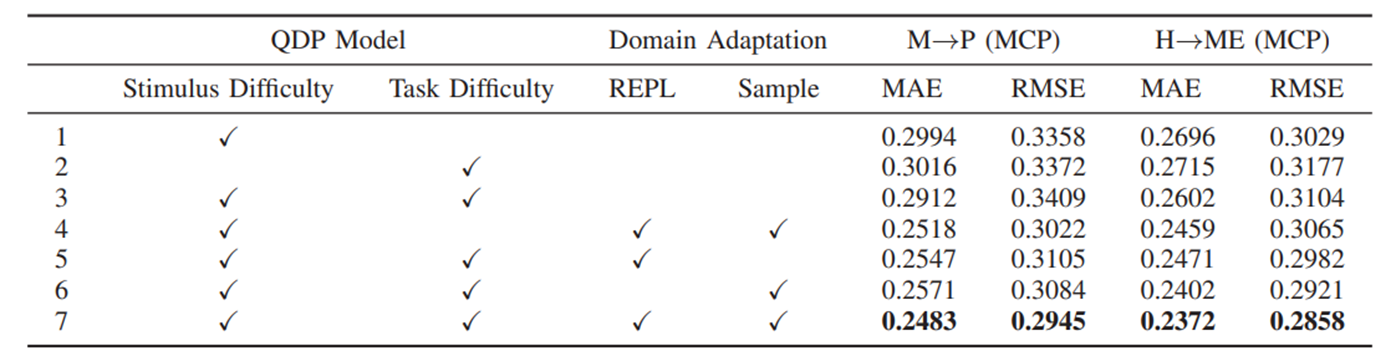

若有收获,就点个赞吧
0 人点赞
