- 分享主题:Federated Learning, NLP
- 论文标题:Efficient-FedRec: Efficient Federated Learning Framework for Privacy-Preserving News Recommendation
- 论文链接:https://aclanthology.org/2021.emnlp-main.223.pdf
1.Summary
This is a paper about solving the problem of news recommendation. In the context of horizontal federated learning, the user’s behavior information is stored locally. It is necessary to use the user’s behavior information to help the training of news recommendation model without leaking the user’s privacy. This paper proposes a model called Efficient-FedRec, which can not only ensure the performance of the model, but also reduce the communication cost without leaking the user’s privacy. Many baselines were selected in the experiment, and Efficient-FedRec beat them in performance and communication cost. Efficient-FedRec is improved from FedRec. The main contribution of this paper is to reduce the communication costs. To deepen my understanding of this paper, I need to understand how the previous federated learning model is applied to news recommendation.2.你对于论文的思考
这篇文章解决的是在横向联邦的背景下的新闻推荐问题,相比于以往的联邦学习方法,如FedRec,这篇文章提出的Efficient-FedRec模型在保证用户隐私安全和模型的性能的前提下,用了巧妙的方法来降低通信成本。以往的联邦学习方法都是把整个server上的模型分发给client,如果模型很大,那么通信开销就很大,而文中的news model就很大,为了解决这个问题,作者只把需要的新闻表征分发给client(直接分发编码结果,不分发编码器),这样就不用分发模型了,而这些表征相比于模型是非常小的,这样就避免了大量的通信开销。3. 其他
3.1解决的问题
在联邦学习的背景下,训练一个新闻推荐模型。每台client上都有用户的用户行为(点击了哪条新闻),现在需要利用这些用户行为来帮助训练新闻推荐模型,但是又不能把这些用户行为从client上取出来放到一起训练,不然的话用户的隐私就会被泄露,同时也需要注意模型的效果以及通信成本。3.2本文提出的模型:Efficient-FedRec
相比于之前的FedRec模型,Efficient-FedRec所需的通信成本更低,并且在模型效果上也更好。3.2.1模型架构
News Model:使用了PLM-NR,可以对新闻进行编码;
User Model:使用了NRMS,可以对用户过去点击过的新闻的表征(News Model生成的表征)进行表征。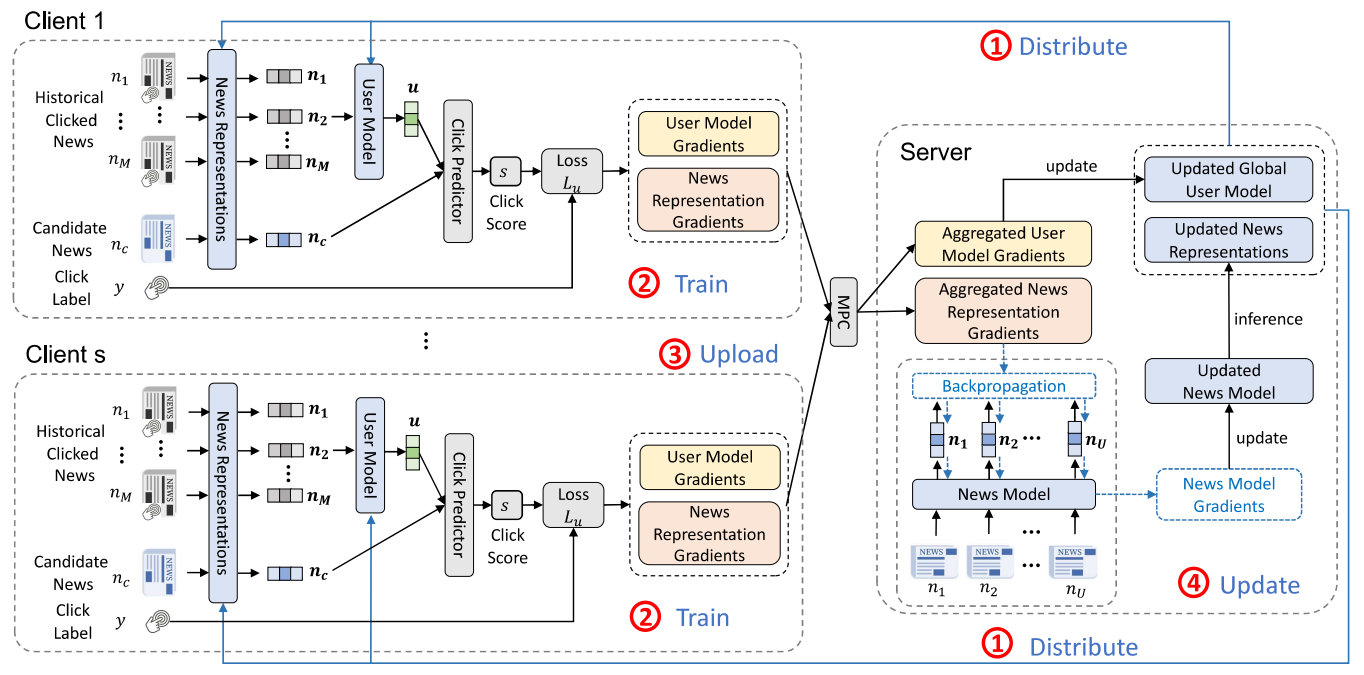
训练流程
(1)distributing user model and news representations
把server上的User Model和news representations分发给各个参与训练的client。这里分发User Model很好理解,但是分发news representations而不是分发News Model,是为了降低通信成本,具体方法是先从P个用户里随机选择s个用户,然后把这s个用户的点击过的新闻全部找出来,为了不泄露用户的隐私(每个用户点击过哪些新闻),这里要使用安全聚合,这样的话server只需要发送这些新闻的各自的表征给client就好了,而不需要把整个News Model给发送过去。
(2)training local user model and news representations
训练各个client本地的user model and news representations。通过server分发的news representations,可以得到用户历史点击的新闻的表征以及候选新闻(新增点击的新闻)的表征,之后User Model利用历史点击的新闻的表征得到一个用户表征,然后用这个用户表征和候选新闻的表征做点积,就得到一个点击分数,然后随机选择K个该用户没有点击过的新闻,然后把点击过的新闻的标签设为1,把那K个没有点击过的新闻的标签设为0,然后计算这一个候选新闻的交叉熵损失: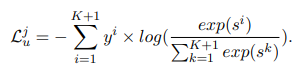
然后对整个用户行为中的新闻(点击过的新闻)求一个总的交叉熵损失: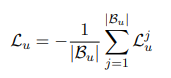
然后求user model和news representations(它的梯度是一个向量,大小为s个用户总的点击过的不同新闻的数量)的梯度: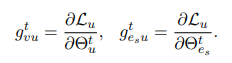
(3)gradient aggregation
对各个client上的两种梯度进行安全聚合: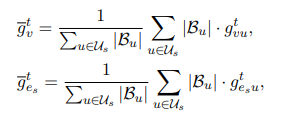
(4)global model updating
利用聚合好的两种梯度,对server上的user model和news model进行更新。
对于user model的更新,直接利用聚合好的梯度并使用FedAdam方法进行参数更新: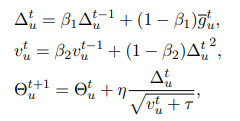
对于news model的更新则要复杂一点,需要先计算news model的参数对于交叉熵损失的偏导: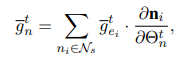
然后再使用FedAdam方法进行参数更新: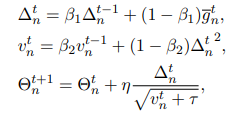
后然使用更新完的参数重新计算要分发给各个client的news representations。3.2.2安全聚合
第一次使用安全聚合是在训练步骤的第一步,第i个client的第j条新闻如果存在,则取一个随机数,如果不存在,就取0,正如下所示:
之后对所有hi进行聚合:h=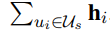
另一次是在训练步骤的第三步,对各个client上的梯度进行聚合。3.3实验
(1)Efficient-FedRec的效果与众多baseline相比,整体来看是最好的。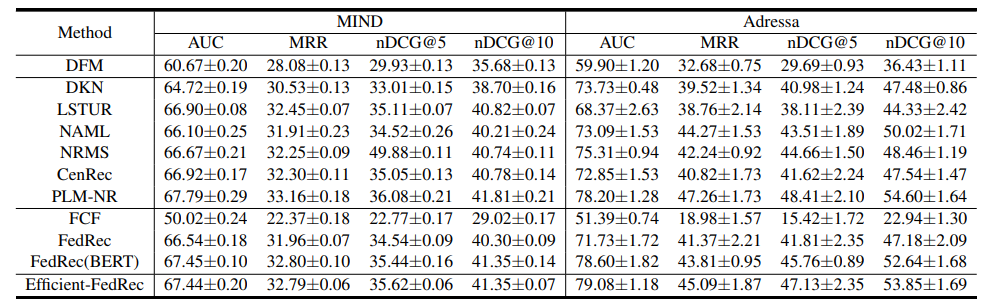
(2)Efficient-FedRec的计算开销和通信开销比baseline低很多。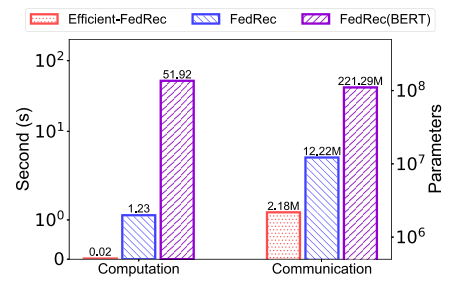
(3)随着news models的规模变大,模型性能上升,同时Efficient-FedRec在client上的各项开销仍远小于FedRec。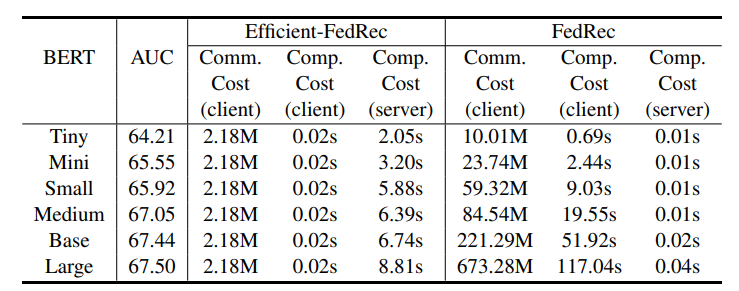
(4)随着每次参与训练的用户数量增加,新闻集合的数量增加,收敛速度变快,通信成本总体上升,聚合时间增加。
(5)参与训练的用户数量增加,能提升模型性能。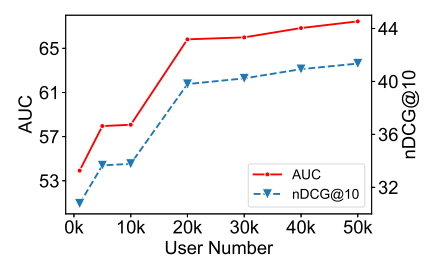

若有收获,就点个赞吧
0 人点赞
