- 分享主题:Transfer Learning、Domain Generalization
- 论文标题:Generalizing to Unseen Domains: A Survey on Domain Generalization
- 论文链接:https://arxiv.org/pdf/2103.03097.pdf
1.Summary
This is a survey paper about domain generalization (DG). The task of DG is to give M source domains, and we need to use these source domains to train a model to make it work well in the unknown target domain. This paper introduces the methods of DG from three angles: (1) data manipulation, (2) representation learning, and (3) learning strategy. Data manipulation refers to adding data. Some data augmentation and data generation methods can be used to achieve this goal. Representation learning refers to learning the representation of domain-invariant so that the model can be well adapted to different domains. Learning strategy refers to use some mature learning modes in machine learning into DG to make the model more generalized, including meta-learning and ensemble learning. This article contains a lot of information, but many places are not detailed, such as invariant risk minimization and meta learning. I can strengthen my understanding of this paper by reading some papers cited in this paper.2.你对于论文的思考
这是一篇领域泛化(Domain Generalization,DG)的综述文章,论文从三个角度介绍了DG的方法:(1)Data manipulation;(2)Representation Learning;(3)Learning strategy,举例了许多传统的方法以及一些比较新的方法,与之前读的迁移学习综述文章相比,感觉这篇文章总结的很全面,可以顺着这篇文章的一些参考文献去了解一些比较新的迁移学习方法和一些数据增强的方法。3. 其他
(1)Domain adaptation
如下图所示,DA(Domain adaptation,领域自适应)的任务是把若干个源域的经验和知识迁移到目标上,源于和目标域都是可以访问的。
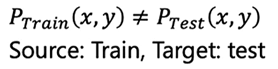
DA的基础理论如下,不等式的左边是目标域上的risk(error),不等式右边第一项是源域上的risk,第二项是源域和目标域的分布差异,第三项表示模型的复杂程度,通常认为是一个常量。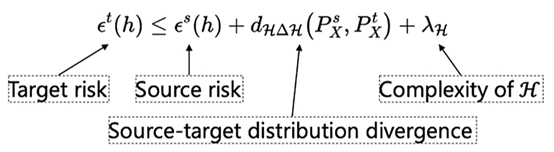
为了解决上面这个问题,有以下方法:
(1)重新度量源域和目标域中样本的权重,选出一些代表性的样本,使得源域和目标域的分布差异比较小,有TrAdaBoost、KMM、Distant TL等方法。
(2)找到一个特征空间,使得源域和目标域映射到特征空间后,两者的分布差异变小,有TCA、DANN、DDC等方法。(2)Domain generalization
DA在训练中,源域和目标域数据均能访问(无监督DA中则只有无标记的目标域数据);而在DG问题中,我们只能访问若干个用于训练的源域数据,测试数据是不能访问的。
DG的任务是给定M个源域(每一个源域的分布都是不一样的),需要利用这些源域,训练一个模型,让它在未知的目标域上效果好。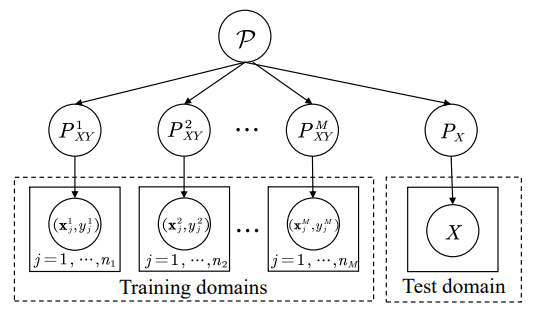
DG的error bound如下: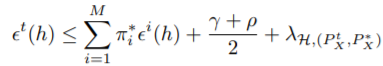
第一项表示所有源域的risk的加权求和的值,pi是权重,γ是使得目标域分布与所有源域加权求和后的分布差异最小的参数pi,表示如下: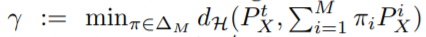
ρ是所有源域两两之间分布差异最大的值,表示如下: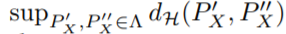
第三项里的PX*是一个假想的最合适的领域分布,不需要考虑。(3)方法
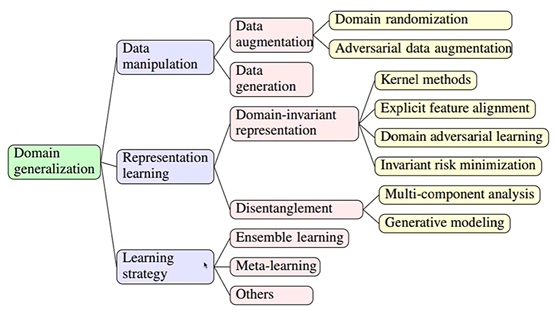
3.1 Data manipulation
因为数据数量和数据的质量对于DG非常重要,所以需要一些数据扩充的方法:
1. Data augmentation
2. Data generation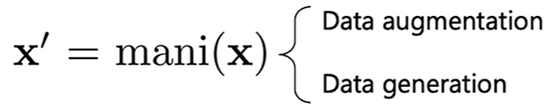
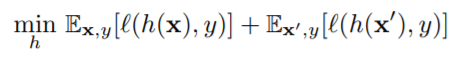
3.1.1 Data augmentation
(1)Typical augmentation
比如旋转图片、改变图片的颜色、在数据中加入一些噪声。
(2)Domain randomization(DA)
对于一些图片,改变它的大小、视角、环境、纹理等。
如下图所示,可以借助辅助领域对原始图片进行增强,生成一系列的新数据。
如下图所示,可以先模拟一些虚拟的场景当作源域,后续迁移(泛化)到真实场景中。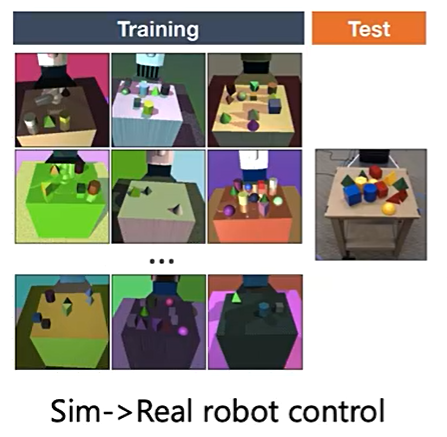
如下图所示,可以用一些合成的图片组成一些源域,之后可以迁移到真实照片中。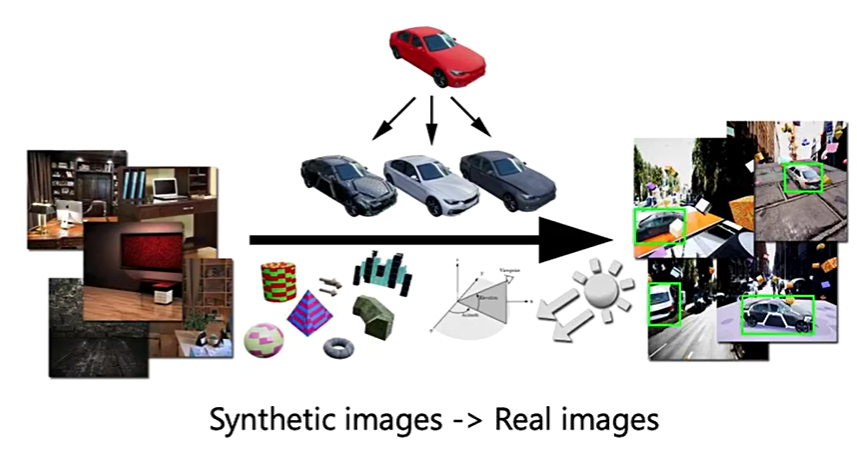
Context-aware randomization:加入一些与当前环境相关的元素,如下图所示。
(3)adversarial data augmentation
1.CrossGrad
往梯度下降的反方向更新新的数据。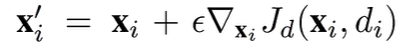
2.ADV augmentation
在ρ领域内找到一个最坏的分布,使得损失函数尽量的大。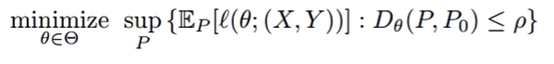
3.1.2 Data generation
1.VAE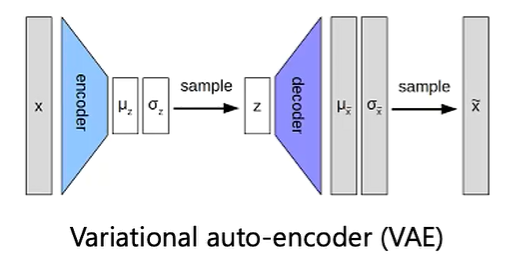
2.GAN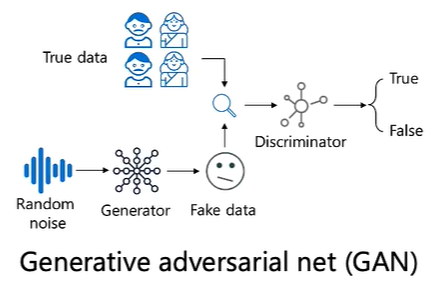
3.Mixup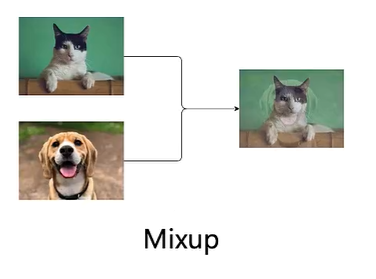
不同领域的图片做Mixup:
如果不同图片的风格是不一样的,可以把它们也Mixup一下: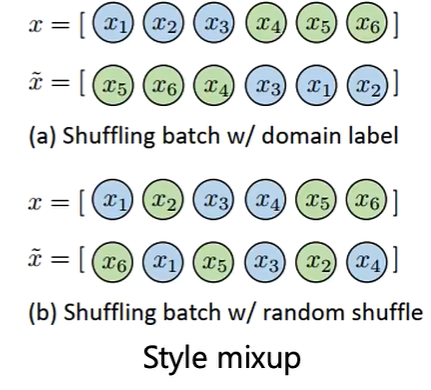
3.2 Representation Learning
目标函数如下,其中f为分类器,g为表征函数。
3.2.1 Domain-invariant representa
3.2.1.1 Kernel-based methods
就是用核方法学习一个domain-invariant的特征,也就是利用把领域上的原始特征通过一个kernel映射到一个新的特征空间,在这个新的特征空间上,各个领域的分布差异会减小,相应的方法有DICA、TCA、SCA。3.2.1.2 Domain adversarial learning
利用了GAN的思想,下图中的绿色部分可以看作一个特征提取器(生成模型),红色部分可以看作一个分类器(判别模型),需要区分特征提取器的最后一层的特征是来自哪个领域的,蓝色部分是要拟合样本的真实标签,最终的目的是要使得分类器无法区分数据的来源,这样就达到了把各个领域的特征映射到了一个新的特征空间,并且各个领域的新特征之间的分布差异很小的目的,蓝色部分保证了这些新的特征仍旧可以比较好的预测出样本的标签。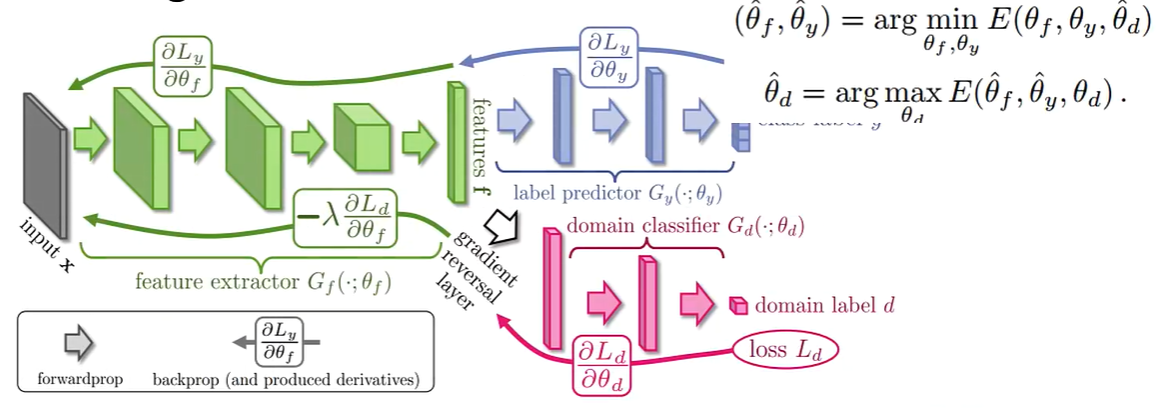
3.2.1.3 Explicit feature alignment
这种方法就是利用一些已有的度量两个分布之间差异的距离函数,比如MMD,加入到DG的学习过程中去,最终学习到domain-invariant的特征。《AdaRNN Adaptive Learning and Forecasting for Time Series》这篇文章就是利用了这种方法,在RNN模型的训练过程中,把不同领域对应的隐藏层之间的分布差异度量出来,并作为损失函数的一部分,从而使得任意两个领域之间的分布差异在RNN的训练过程中逐渐变小。3.2.1.4 Invariant risk minimization
前面的三种方法都是在减小分布差异的方向上努力,而IRM不关注这个,而是希望能够学习到一个最佳的分类器(假设是分类任务,在深度学习模型最后一层的新的特征空间上做分类)。3.2.2 Disentanglement
虽然不同领域的特征分布是不一样的,但是如果把这些特征拆开,那么可能大家会有一些公共的特征,也就是说把一个特征拆成两部分,一部分是公有的,另一部分是自己特有的,这就是特征解耦,之后就可以利用大家公有的特征来进行迁移任务了,这类的方法有UndoBias、DIVA、DAL。3.3 Learning strategy
3.3.1 Meta-learning
元学习就是把已有的领域分成若干个任务,然后从这若干个任务中学习到普遍的知识。
如下图所示,这是一个MLDG(Meta-learning for domain generalization)模型,在源域上分出一些小任务(Meta-train和Meta-test),用以训练模型,之后就可以把模型迁移到目标域上。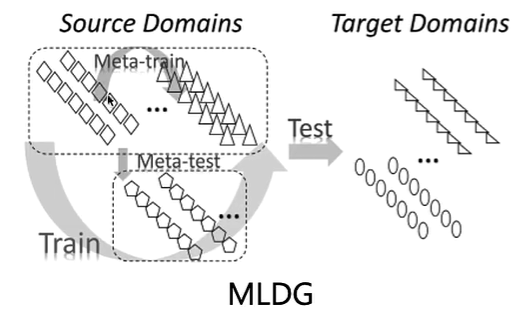
3.3.2 Ensemble learning
把所有源域的模型进行集成,得到目标域所需预测的标签。如下面的式子,对各个模型的预测结果进行加权求和。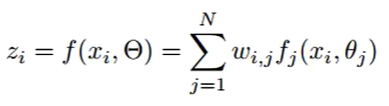

若有收获,就点个赞吧
0 人点赞
