- 分享主题:Transfer Learning
- 论文标题:A Comprehensive Survey on Transfer Learning
- 论文链接:https://arxiv.org/pdf/1911.02685.pdf
1.Summary
This is a survey of transfer learning. The methods of transfer learning can be divided into four categories: 1.Instance-Based approach, 2.Feature-Based approach, 3.Parameter-Based approach, 4.Relational-Based approach. Because the Relational-Based Approach is rarely used, this paper does not describe it. This paper divides the remaining three methods into two categories: 1.Data-Based approach, 2 Model-Based approach. The Data-Based method includes Instance-Based approach and Feature-Based approach. The Model-Based approach includes the Parameter-Based approach. The information in this article is very large, in order to deepen my understanding of this paper, I should read some of the cited papers.2.你对于论文的思考
这是一篇迁移学习的综述,文中把迁移学习的主要方法分为了两大类:1.基于数据的迁移学习方法,2.基于模型的迁移学习方法,并根据这两类方法进行了详细描述。这篇文章的信息量很多,内容比较完备,基本上对于方法的描述也比较清晰,但有一些比较难的方法还是得查阅别的资料才能大致得到理解。3. 其他
3.1迁移学习分类
迁移学习可以根据是否有标签分成三个类别:
1.转导学习:只有source domain是有标签的
2.直导学习:source domain和target domain都有标签
3.无监督迁移学习:source domain和target domain都没有标签
可以根据source domain 和 target domain 上的 feature space 和 label space的异同来分类:
1.同质迁移学习:
2.异质迁移学习: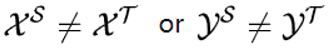
按照迁移学习的方法来分类:
1.基于样本的方法:基于不同的样本权重
2.基于特征的方法:将原样本特征映射到新的表征上
3.基于参数的方法:在模型或者模型参数上来迁移学到的知识
4.基于关系的方法:关注于具有一定的关系的领域,比如老师上课、学生听课就可以类比为公司开会的场景,这种类比就是一种基于关系的迁移学习方法
本文不讨论,基于关系的方法,并把基于样本的方法和基于特征的方法归为基于数据的方法,把基于参数的方法归为基于模型的方法。
3.2基于数据(DATA-BASED)
3.2.1实例权重策略
- 固定权重的方法
有比较多的有标签的source domain数据,以及少量的target domain的数据,并且两个domain上的数据只有样本的分布不一致,可以考虑对source domain中的样本添加一些权重,使得两个分布相近。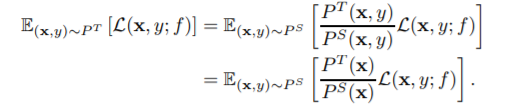
目标函数就可以表示如下: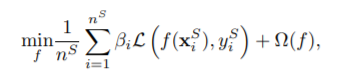
其中β是权重参数。可以用Kernel mean matching (KMM) 来获得对应的权重参数β: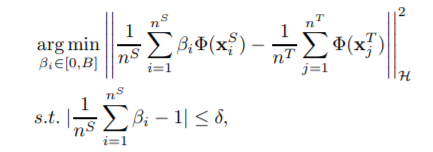
2.不固定权重的方法:比如TrAdaBoost,在训练的过成功更新权重参数。3.2.2特征转化策略
分布差异度量
如maximum mean discrepancy (MMD):
其它还有Kullback-Leibler Divergence、Jensen-Shannon Divergence、Bregman Divergence、Hilbert-Schmidt Independence Criterion等方法。特征增强
针对source domain 和 target domain上的特征,可以对原来的feature进行一定的增强,从而获得三类不同的特征 (1) 通用特征 (2) source domain特有特征 (3) target domain 特有特征。
对于同质的迁移学习任务,得到如下的特征映射: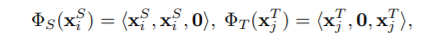
对于异质的迁移学习任务,对于通用特征,就需要转换到相同的维度,则需要额外的学习一个矩阵用于映射, 得到如下的特征映射: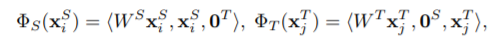
特征映射
学习一个映射函数 Φ ,优化如下的目标函数: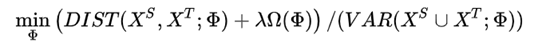
要通过映射函数 Φ获得一个表征,使得source domain 和 target domain 上的分布尽可能相近,并且数据的方差要比较大,方便后续区分。
如果要保有数据的结构特征 ,那么需要对数据的结构特征进行学习及限制,可以得到如下目标函数: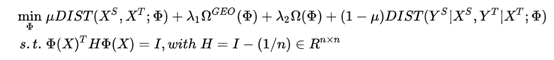
以上的优化目标中,除了边缘分布的相似性,同样也考虑了条件分布的相似性。特征选择
目的是在source domain和target domain中选择出作用相同的特征,这些特征可以作为迁移的桥梁。特征编码
这个方法就是利用Autoencoder来学习一个新的特征编码,然后所有样本的特征转换到Autoencoder学到的特征编码这个space上去,再在这个新的space上学习模型。特征对齐
在前面提到的方法中往往都是利用一些显性的特征,但是实际上还有许多隐性的特征是可以利用的,比如子空间特征、谱特征、统计特征。对于这些隐性特征,我们可以分别在source domain和target domain计算这些特征,并且研究这些隐性特征如何可以在两个domain上进行对齐,以子空间特征为例,先为source domain和target domain生成各自的子空间,然后学习一个转移矩阵W,如下面式子所示,最后用转移矩阵W对齐source domain和target domain的特征。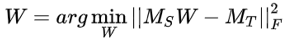
3.3基于模型(MODEL-BASED)
3.3.1模型控制策略
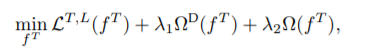
其中第一项表示的是优化的目标函数,比如优化均方误差,第二项的则用来统一代表不同的正则化函数,第三项则是用来限制模型的复杂程度的。Consensus Regularizer
该方法是针对target domain上没有标签的情形,并且拥有多个source domain,可以建立数量为source domain个数的分类器,优化目标为: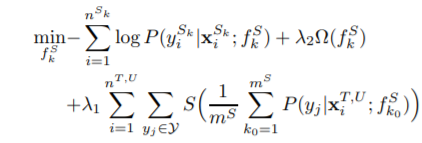
其中S(x) = -xlogx,优化目标中第一项表示优化source domain的NLL损失,而最后一项则是在优化交叉熵,这样做的目的在于,提高不同的分类器在target domain上的共识,并且降低在target domain上预测的不确定性。Domain-dependent Regularizer
该方法是针对target domain上即有有标签的数据,也有无标签的数据,并且拥有多个source domain,优化目标为: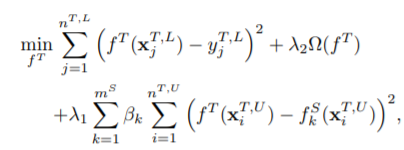
第一项是在利用有标签数据优化target domain上的均方误差,最后一项是在利用无标签数据进行优化,希望在无标签数据上,每个source domain上的预测结果与target domain上的预测结果尽可能相近。3.3.2参数控制策略
参数共享
把在source domain上学习到的模型的参数全部或部分迁移到target domain上,后续可以用target domain的少量数据对迁移过来的部分或者全部参数进行微调。参数限制
参数共享是让source domain和target domain共用一些参数,而在参数限制的方法中,则是要求两个domain上的某些参数尽可能相似。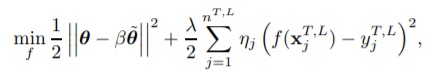
3.3.3模型集成策略
TaskTrAdaBoost
这个方法与AdaBoost的思想类似,TaskTrAdaBoost首先在source domain上训练多个弱分类器,形成一个分类器池,然后再在target domain上衡量这些弱分类器的表现,每次挑一个表现最好的分类器出来,然后再给target domain上的样本按照分类误差进行赋权。Locally Weighted Ensemble
TaskTrAdaBoost是对每个分类器给予一个权重,相当于该分类器对所有的样本的权重是一致的, Locally Weighted Ensemble则是每个分类器对于不同的样本的权重也应该不同。Ensemble Framework of Anchor Adapters
上面两种方法侧重于如何加权,而这种方法关注如何构建弱分类器。3.3.4深度学习技术
除了传统的深度学习技术,还有生成深度学习技术,就是利用GAN的思想,对于source domain和target domain都要提取特征来进行预测,另外有一个分类器,需要分辨提取出来的特征是来自哪个domain,用来充当GAN中的判别模型的角色,最终要求这个判别模型分辨不出数据是来自于哪个domain,从而在两个domain上能够提取到足够相近的特征。

若有收获,就点个赞吧
0 人点赞
