- 分享主题:Transfer Learning、Time Series
- 论文标题:Transfer learning for time series classification
- 论文链接:https://arxiv.org/pdf/1811.01533.pdf
1.Summary
This paper is about applying transfer learning on time series classification tasks. This is the first paper to conduct relevant research. The model used in this paper is FCN (Fully Convolutional Neural Network), which includes three convolution layers, a pooling layer and a full-connected layer. The datasets uses 85 time series classification datasets in UCI machine learning warehouse to construct 7140 pairs of transfer learning tasks. For each pair of transfer learning tasks, the first three convolution layers are transferred to the target task, and then the samples of the target dataset will to fine-tune. The experiment is quite sufficient. The final result shows that the effect of using transfer learning is often better than not. Transfer learning has little negative effect.2.你对于论文的思考
这篇文章是研究把迁移学习应用到时序分类的任务上,迁移的方法的比较普通,就是把卷积层迁移到目标任务上,但是我觉得这篇文章有两个主要的贡献点,一个就是进行了大量的实验,构建了许多迁移任务,最终得到了迁移学习往往优于不使用迁移学习的结论。另一个贡献点是为了使迁移效果变好,要尽量选择合适的源域进行迁移,这时就需要找到与目标域最相似的源域了,然而这些时序数据集中的时间序列的维度可能不一样,很难直接进行比较,作者就先使用了DBA的方法把多维时间序列规约为一维序列,之后就方便两个时间序列进行比较了,但这种方法还是有缺点的,它没有考虑到数据集内部不同维度之间的关联性。3. 其他
模型
论文中的模型使用了FCN(Fully Convolutional Neural Network),它包含了三个卷积层、一个池化层和一个全连接层,对于每一对迁移学习任务都是把前面的三层卷积层给迁移到目标任务中,再用目标数据集的样本进行fine-tune。
这个gap还是很好用的,可以直接实现降维,极大地减少深度模型的参数,这样也有了正则化的作用,而且如果源域和目标域的时间序列长度不一样也没有关系。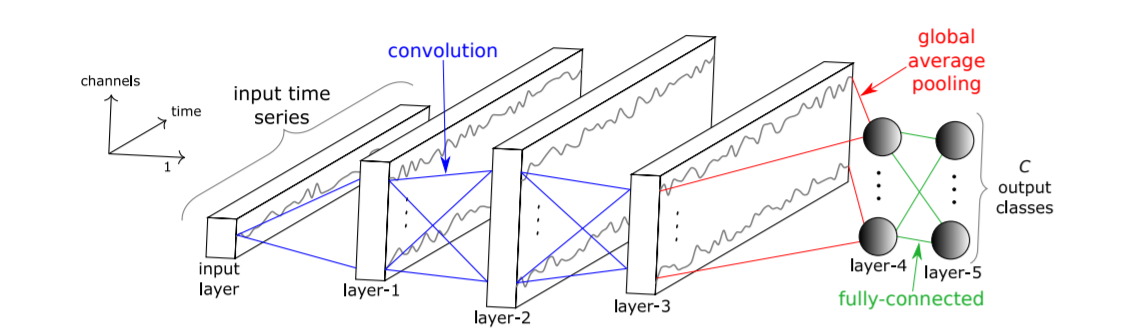
选择合适的源域
为了选择合适的源域,需要度量不同数据集的相似度,然后选出最相似的数据集作为源域。然而这些数据集都是时间序列数据集,度量时间序列相似性的另一个问题是,如何度量不同维度的时间序列的相似性。
作者就先使用了DBA(DTW Barycenter Averaging)的方法把多维时间序列规约为一维序列,之后再使用DTW(Dynamic Time Warping)来度量两个时间序列的相似度。经过相似度计算,可以针对n个数据集,得到一个n*n的相似度矩阵,此矩阵表示了不同数据集之间的相似度,相似度高的两个数据集,迁移效果最好。DTW(Dynamic Time Warping)
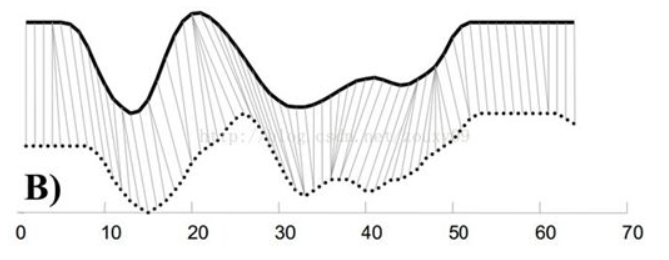
如下图所示的两个时间序列,如果直接按对应位置点对点进行相似度计算,那么相似性就很容易受到序列的移位、错位的影响,于是就有了右图的DTW方法,这种方法可以不局限于点对点,也可以点对序列,最终要使得整体的两个序列间的距离最小,可以使用动态规划的方法,假设两个时间序列的长度分别为n和m,那么构建一个n*m的数组c,c[i][j]表示两个序列分别到第i个位置和第j个位置为止,当前的最小距离是多少,整个状态可以从三个之前的状态转移过来,分别是c[i-1][j]、c[i][j-1]和c[i-1][j-1],选择这三者中的最小值,再加上第一个序列中的第i个点和第二个序列中的第j个点之间的距离就是c[i][j]的值了,用这种策略就能实现使用DTW方法度量两个时间序列距离的目的了,如果需要如右图中的连线结果,只需要记录每一次状态转移的方向就可以了。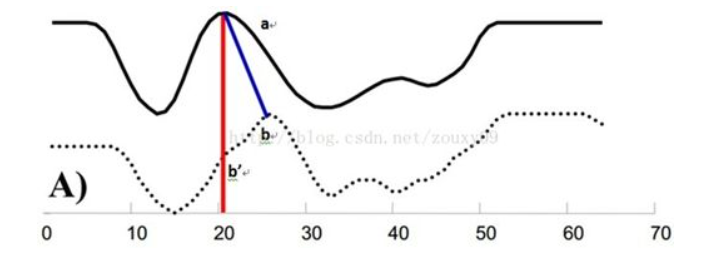
DBA(DTW Barycenter Averaging)
如下图所示,如果要求三个黑色时间序列的平均值,最简单的方法就是直接对应位置上求平均值,得到蓝色的时间序列,但是这种方法问题很明显,就是黑色箭头所指的那块凸起,这在原先的三个黑色时间序列中是没有的,所以我们更希望能得到下图中的红色时间序列。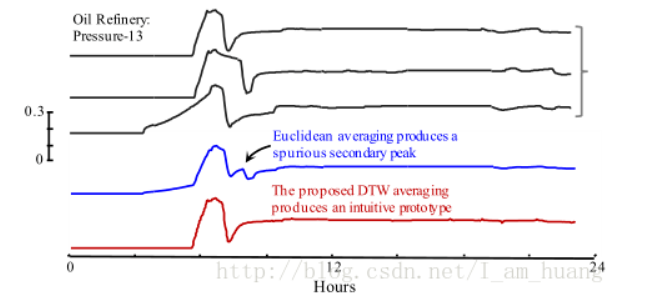
假设现在有三个序列A、B、C,那么可以先把序列B当作平均序列,按DTW的方法进行如下操作: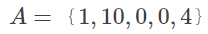
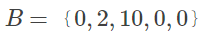


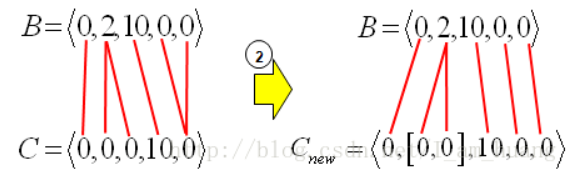

得到三个新的序列,然后再按下面的表格计算出每一个位置的平均值,从而得到一个新的平均序列,重复这个过程,直到平均序列不再发生太大的改变,最终就得到了三个序列的平均序列,对于多维时间序列也是如此,可以把多维时间序列压缩为一维序列。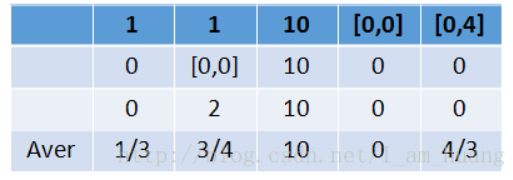
实验
作者利用了UCI机器学习仓库中的85个时间序列分类数据集,构建了7140对迁移学习任务,最后的实验结果表明,使用了迁移学习的效果往往比不使用要好,迁移学习几乎不会产生什么负面效果。
下图中的HandOutlines数据集是一个迁移学习效果比较差的数据集,图中的横轴表示84个源域,与目标域(HandOutlines)的相似度越高,序号就越小(越靠左),纵轴表示在目标任务上的准确率,可以看到在相似度前十的数据集上的迁移任务效果都比不使用迁移学习要好,可能是因为HandOutlines本身样本就很多,有一千多个,所以不用迁移学习就可能会有比较好的效果。
下图中的Meat数据集则与上面的HandOutlines数据集不同,只有二十个样本,非常少,所以迁移学习效果非常好,在全部的84个源域上都获得了优于不使用迁移学习的迁移效果。
从上面的两个实验也可以看出,蓝色的线大致是呈下降趋势的,说明先用DBA降维再用DTW度量距离的方法还是有点靠谱的。

若有收获,就点个赞吧
0 人点赞
