- 分享主题:CV, Transformer
- 论文标题:Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
- 论文链接:https://arxiv.org/pdf/2103.14030.pdf
1.Summary
This is a paper about applying transformer to CV field. This paper proposes a model called Swin Transformer. Compared with ViT, Swin Transformer has made improvements in the attention part of the transformer structure. The original self-attention is global, while Swin Transformer divides the original entire feature map into four parts, each of which seeks self-attention separately. This is called W-MSA. Because W-MSA will make some parts unable to interact, we need to add an SW-MSA after the block of W-MSA. SW-MSA uses shifting windows to enable different parts of the original W-MSA to communicate. In order to deepen my understanding of this paper, I can read some papers on ViT model.2.你对于论文的思考
这篇文章提出的Swin Transformer模型基于ViT模型的优化,它的每一个block包含了两个transformer的block,第一个中的自注意力计算是基于W-MSA的,也就是把feature map分为了4部分,每一部分单独计算;第二个中的自注意力计算是基于SW-MSA的,利用了移动窗口,让原本W-MSA不能交互的部分也能互相交互了。3. 其他
3.1 Swin Transformer
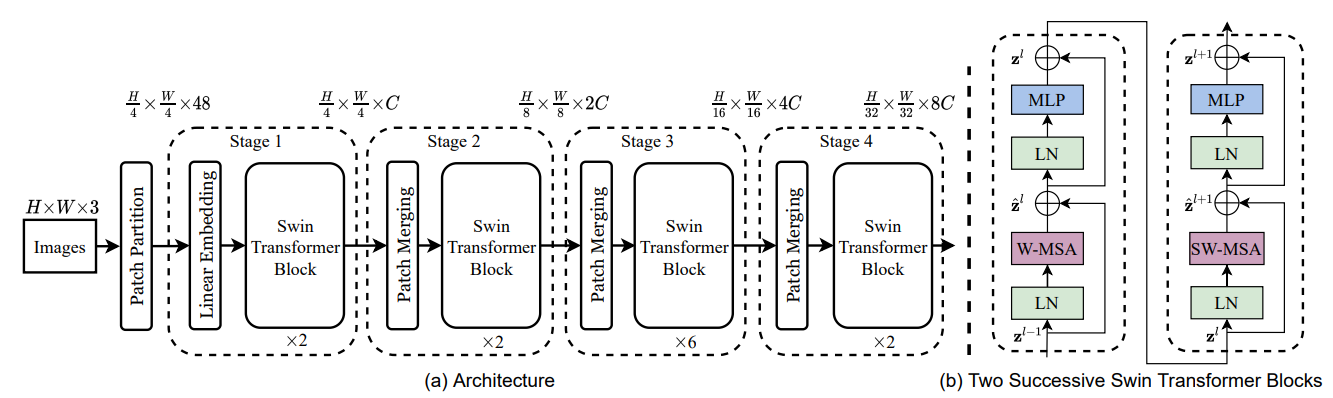
3.1.1 W-MSA

如图所示,图片被分成了四部分,每一部分单独计算自注意力,这样做的好处是,计算的时间复杂度不会像原先计算全局自注意力那样,呈平方增长,W-MSA只会线性增长。3.1.2 SW-MSA
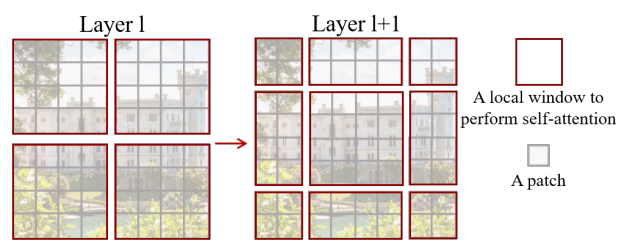
W-MSA虽然降低了计算成本,但是会出现不同part之间无法交互的问题,这显然是不行的,因此还得加入上图所示的SW-MSA,利用移动窗口,改变part的划分方式。3.1.3 Patch Merging
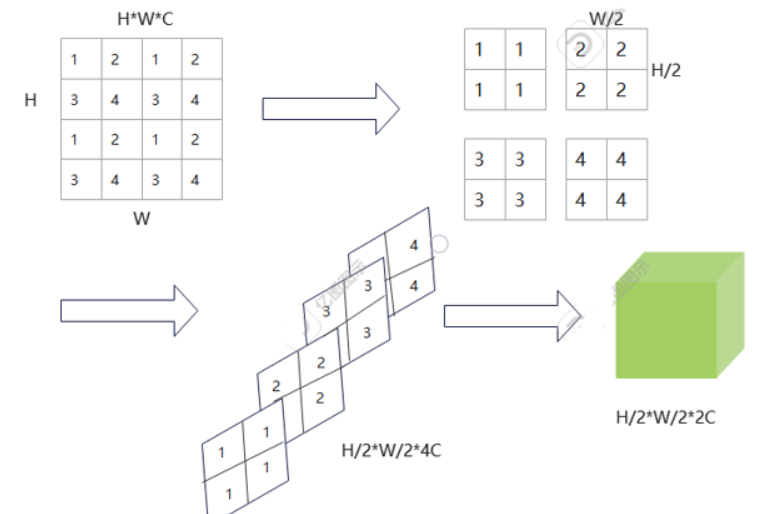
如图所示,这一步起到下采样的效果,原本HWC的特征会变成H/2W/24C,这之后可以再经过卷积层,变成H/2W/22C。3.2 实验


若有收获,就点个赞吧
0 人点赞
