- 分享主题:Transfer Learning, Unsupervised Domain Adaptation, CV, Explicit Feature Distribution Alignment, Adversarial
- 论文标题:Transferable Attention for Domain Adaptation
- 论文链接:https://www.researchgate.net/publication/335496894_Transferable_Attention_for_Domain_Adaptation
1.Summary
This is a paper about picture classification. Now there is a source domain and a target domain. The source domain data is labeled and the target domain data is not labeled. This paper uses the adversarial method to realize the transfer of knowledge. In the past, such methods did not pay attention to the weight of samples and the weight of each feature in the picture. But in fact, some samples are not suitable for transfer, and not every feature in a picture is equally important. In order to solve this problem, this paper proposes a model called TADA. TADA not only gives different weights to different features of each picture, but also gives different weights to different samples. In order to deepen my understanding of this paper, I can learn some knowledge about attention for transfer learning.2.你对于论文的思考
这是一篇利用域对抗的方法来解决非监督的域自适应的文章,这篇文章提出的模型TADA解决以往方法没有关注样本的权重的问题,因为有些样本并不适合迁移,比如说那些和另一个域相差比较大的样本。此外,因为这篇文章的任务是图片分类,所以,TADA还对一张图片里的不同区域进行了加权,比如说,图片里的背景有时并不重要,应该加大前景的权重。3. 其他
3.1 解决的问题
这篇文章解决了非监督的域自适应问题,优化了以往的域对抗的迁移学习方法。3.2 TADA
TADA的整体结构如下图所示: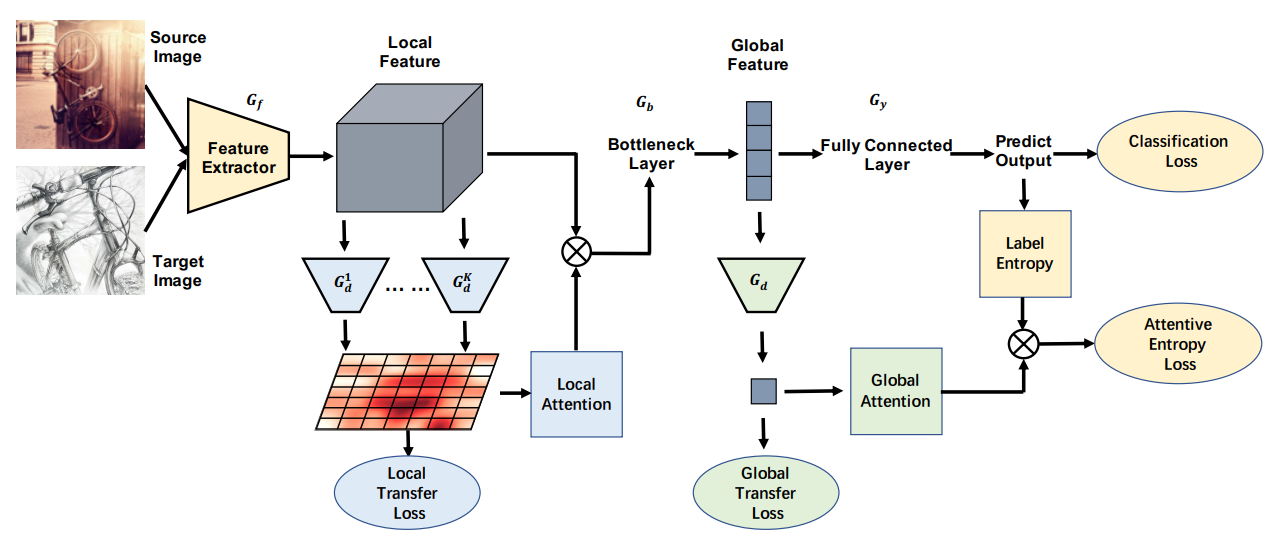
3.2.1 Transferable Local Attention
这一部分包含了一个局部迁移损失、局部注意力计算,并输出局部加权后的特征。局部迁移损失
经过Gf编码后的特征的维度大小为772048,因此把它分为49个区域,每个区域是一个2048维的向量,之后设置49个编码器,然后对编码后的结果进行域标签的判断,损失函数如下:
局部注意力计算
这之后,对这49块区域计算权重,计算方式如下:

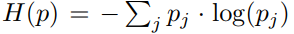
也就是希望域标签预测的熵越小的区域权重越大,因为这些区域有着自己域的独特特征,很有可能是前景信息,而那些很难区分域的区域很有可能是背景信息,前景信息可能比背景信息重要得多。
之后,就把加权后的特征输出到下面的部分。3.2.2 Transferable Global Attention
这一部分的输入是上面的输出,之后对这个输出的特征进行全局的域对抗,以及源域的标签预测、全局注意力计算、带注意力权重的熵损失计算。全局迁移损失
下面的式子中,hi就是局部注意力加权后的特征,然后特征提取以及判别域标签,然后计算交叉熵损失。
源域标签预测

全局注意力计算
如下面的式子所示,越难以判断域标签的样本权重越大,因为这些样本和另一个域的样本比较相似,可迁移性比较好。

最小化熵损失
因为目标域的样本不带标签,所以这篇文章利用最小化熵损失来辅助训练(希望标签的预测更加明确,不希望样本出现在分类的边界)。
3.2.3 总体损失函数和目标函数
总体损失函数:
总体目标函数:
3.3 实验
(1)数据集:Office-31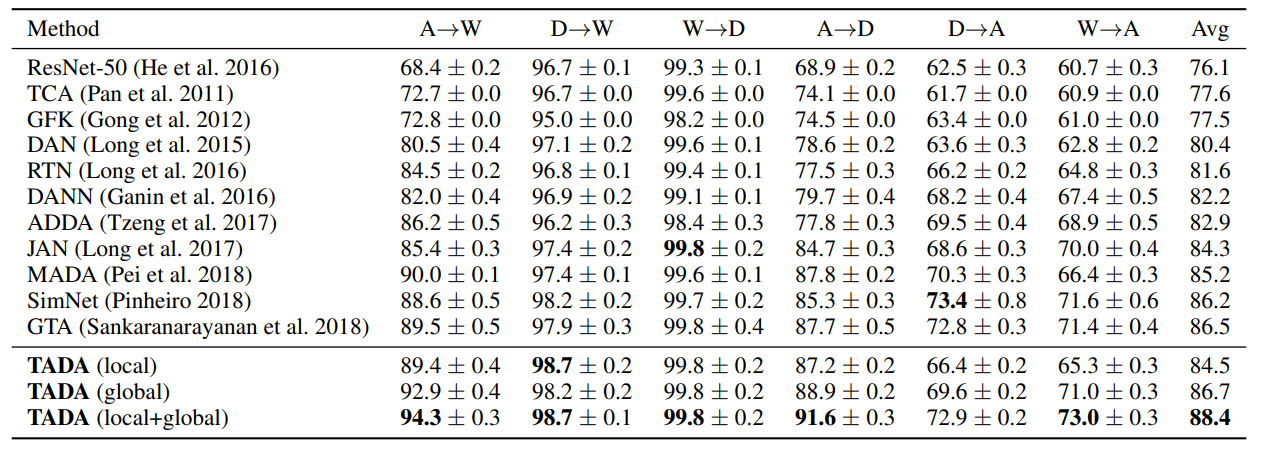
(2)数据集:Office-Home
(3)特征可视化(利用了t-SNE降到了二维)
图中蓝色和红色代表不同的域,可以看出,从左到右,源域和目标变得越来越难以区分,TADA的效果最好。

若有收获,就点个赞吧
0 人点赞
