- 分享主题:CV, Transformer
- 论文标题:AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
- 论文链接:https://arxiv.org/pdf/2010.11929.pdf
1.Summary
This is a paper about applying Transformer model to CV tasks. Transformer model has achieved very good results in NLP field, so the author wants to apply Transformer model to CV field. The Vision Transformer (ViT) model proposed in this paper combines Transformer and CV. Because the input of the Transformer requires a sequence, ViT first divides the picture into N small patches, then reshape into a one-dimensional vector, and then through a linear transformation, N tokens are obtained. In this way, a picture can be transformed into a sequence of length N. In order to integrate the information of these n tokens, a learnable class token is added to the first input position, and its value corresponding to the output position is used as the representation of the picture. In order to deepen my understanding of this paper, I can read some papers related to Transformer and CV.2.你对于论文的思考
这是第一篇把Transformer应用到CV中的文章,此前CV多应用于NLP领域,作者尝试将其应用于CV。因为Transformer的输入是一条序列,所以得把图片分成N个patch,生成一条长度为N的序列,这样的做法就和CNN完全不一样了,除了添加位置编码这一步有考虑到图片中的位置信息,其余部分基本都是图片的一个部分可以学习到其余所有部分的信息,浅层也是这样,而CNN的浅层只能学习临近的信息。这样看起来似乎有些奇怪的组合,在实验中却有着比较好的表现,尤其是在大型的数据集上(在这个数据集上预训练),效果优于CNN,而且ViT的模型参数比CNN少,但是在小型数据集上CNN更优。3. 其他
3.1 ViT

(1)把一张图片分成N个patch。
原图: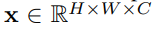
N个patch: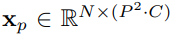
(2)为每一个patch做线性变换,在第一个位置加上class token,并加上位置编码。
(3)Transformer Encoder
y为生成的图片表征。
(4)用MLP Head对图片表征y进行分类。3.2 实验
3.2.1 参数设置

3.2.2 跟SOTA的对比

3.2.3 数据集的大小对性能的影响

左图中,在小数据集上,大模型效果不如小模型好,在大数据集上则相反。
右图中,ViT-B/32和ResNet50x1有相似的参数量,预训练的数据量小时,后者优于前者,数据量大时反之。ViT-L/16和ResNet152x2也是如此。3.2.4 计算资源与性能的折中

Hybrid模型:利用CNN或其它模型提取patch的特征,再输入到Transformer中。
跟ResNet相比,ViT性价比更高。
跟Hybrid模型相比,在计算资源有限的情况下,Hybrid模型性能更优,但随着计算资源的增加,两者性能逐渐接近。3.2.5 不同层的感受视野(ViT和Hybrid模型)

attention distance越大,类似于CNN中的感受视野越大。
左图中,在前几层,就有些head已经在整合全局信息了,CNN的前几层往往都还处于整合局部信息的阶段。
右图中,前几层里作用范围小的head消失了,因为ResNet已经完成了特别小的局部信息的整合。

若有收获,就点个赞吧
0 人点赞
