- 分享主题:Federated Learning, NLP
- 论文标题:FedMatch: Federated Learning Over Heterogeneous Question Answering Data
- 论文链接:https://arxiv.org/pdf/2108.05069.pdf
1.Summary
This is a paper using federated learning to solve Question Answering (QA) problems. In this paper, BERT model is used to predict the matching score between questions and candidate answers. Because the data owned by a single user may not be enough to train the model, it is necessary to combine the data owned by multiple users to train the model. For the purpose of privacy protection, it needs to be trained by federal learning methods. The previous methods are only to train a model for multiple users. But the data sets of different users are heterogeneous. The final trained model may not be suitable for the data of some users. In order to solve this problem, this paper proposes a model called FedMatch. FedMatch includes shared backbone and private patch. The goal of shared backbone is to learn common and shareable knowledge from the data of multiple users. Private patch is to learn the unique characteristics of each user’s data. Finally, each user can get a model suitable for their own data. In order to deepen my understanding of this paper, I can learn some methods of horizontal federation learning.2.你对于论文的思考
这是一篇关于联邦学习的论文,解决的问题是问答,也就是利用BERT模型预测一个问题与所有候选答案之间的匹配分数,匹配分数最高的那个候选答案就认为是最适合的答案。但是单个数据集的数据量可能比较少,所以需要结合别的数据集,这些数据集以孤立的形式存在,为了隐私保护,要用联邦学习的方法进行训练。传统的方法就是为所有的数据集训练一个模型,这样显然是有问题的,因为不同的数据集可有能是non-IID的,最后的这个模型不一定能适合所有数据集,本文提出的FedMatch模型就是来解决问题的,在原有模型(共享的主干)的基础上,在模型里增加了一些私有的补丁,共享的主干的参数是所有数据集共享的,可以提取共有的知识,私有的补丁是每一个数据集私有的,可以保留自己数据集的特点,最终就能为每一个数据集训练好一个模型。3. 其他
3.1需要解决的问题
需要以联邦学习的方式解决Question Answering问题,但是不同的数据集是non-IID的,并且数据集大小不一,例如以下情况:
(1)HealthTap、Care和丁香园等在线医疗平台:患者在平台上提出与自身疾病治疗相关的问题,患者-医生的QA数据集在问题类型、询问目标以及病例数方面存在显著差异。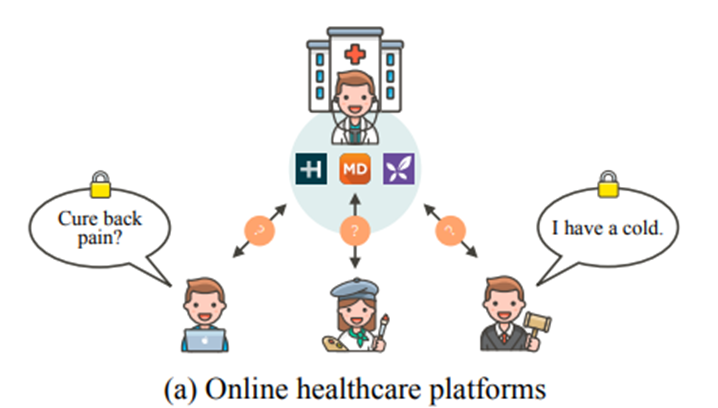
(2)eBay、亚马逊和阿里巴巴等国际电子商务公司:用户在网站向客户服务部门提问,产生的QA数据集在语言表达、产品类型以及数据大小方面可能存在显著差异。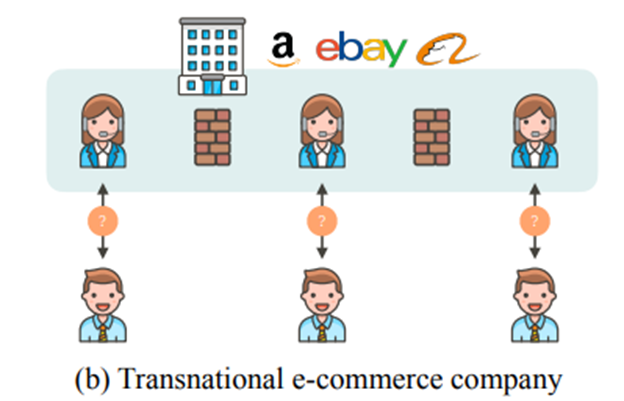
3.2FedMatch模型
FedMatch是一个拥有共享主干、私有补丁,并且利用联邦学习的方式训练的 模型。3.2.1共享主干(Shared Backbone)
共享主干的目标是从多个参与者那里学习通用和可共享的知识,并且可以解决单个参与者数据量不足的问题。
共享主干先是利用一个BERT模型来提取特征,然后是一个softmax层输出问题与候选答案的匹配结果。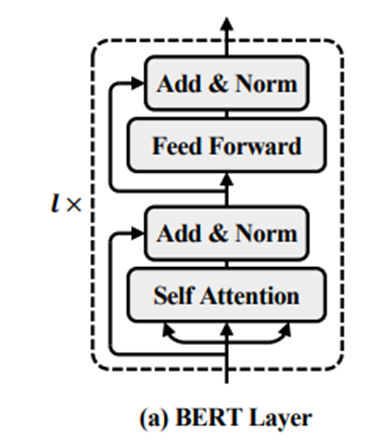
(1)Self-Attention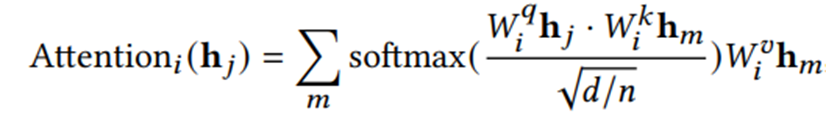
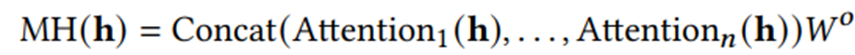
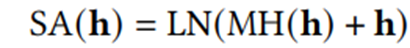
(2)Feed-forward Network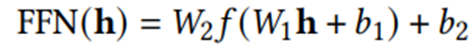
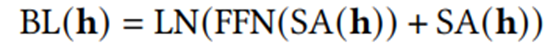
3.2.2私有补丁(Private Patch)
私有的补丁的目的是保留每一个数据集的自己的特点。补丁添加方式
本文提出了以下四种补丁添加方式:
(1)Inner Patch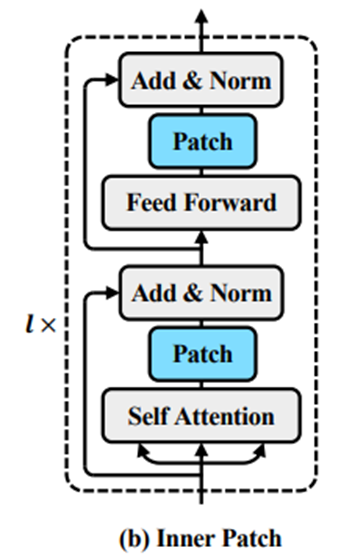
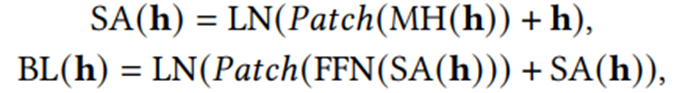
(2)Outer Patch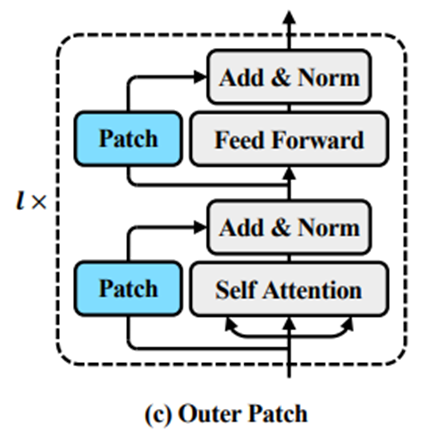
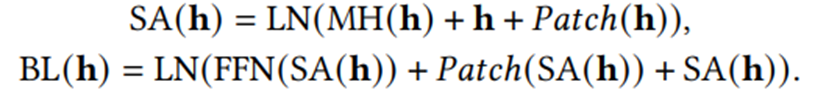
(3)Vertical Patch(在整个BERT模型的输出后加上patch,也就是softmax层之前)
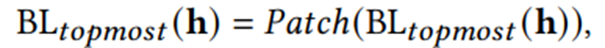
(4)Horizontal Patch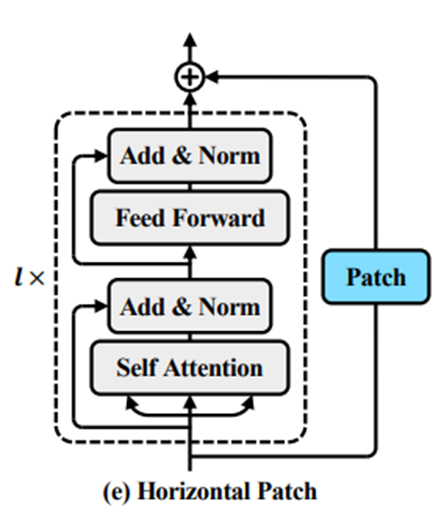

私有补丁形式
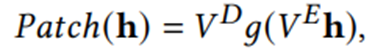
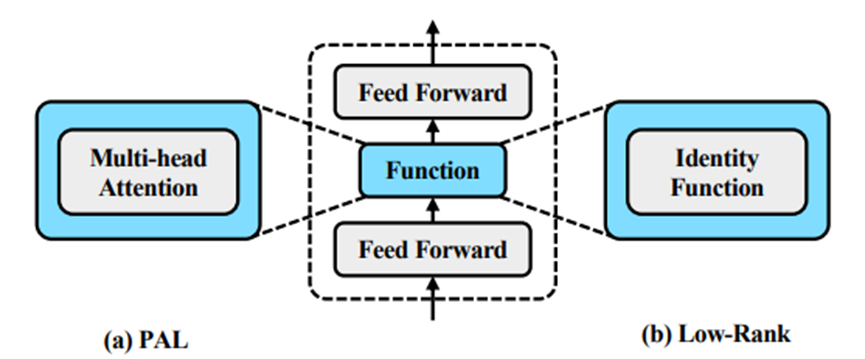
g(·)函数有以下两种形式:
(1)Projected Attention Layer (PAL):多头注意力
(2)Low-Rank Layer:恒等映射
3.2.3联邦训练
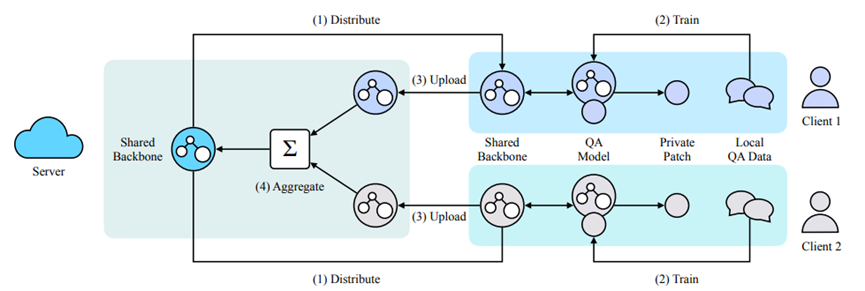
Server首先初始化模型参数(共享主干的参数),训练步骤如下:
(1)Server分发共享主干参数给各个Client;
(2)每个Client向共享主干添加一个私有补丁,并根据自己本地的数据各自训练模型;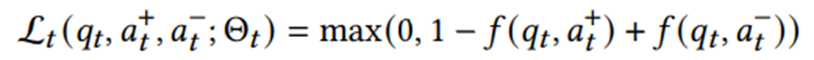
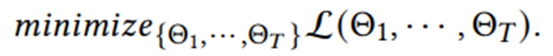
(3)各个Client把各自共享主干的参数发送给Server;
(4)在Server中聚合共享主干的参数,并更新Client上的共享主干模型的参数。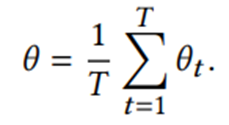
重复上述过程,直到整个模型收敛。
3.3实验
(1)对比各种私有补丁的添加方式和补丁形式,FedMatch(H+LR)的综合效果最好。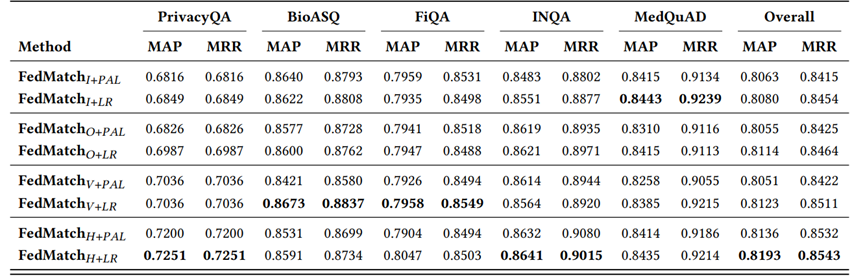
(2)每轮训练使用全部Client,不考虑对Client采样,FedMatch的综合效果最好;每轮训练只采样部分Client,FedMatch(CS)的综合效果最好,且综合效果好于FedMatch。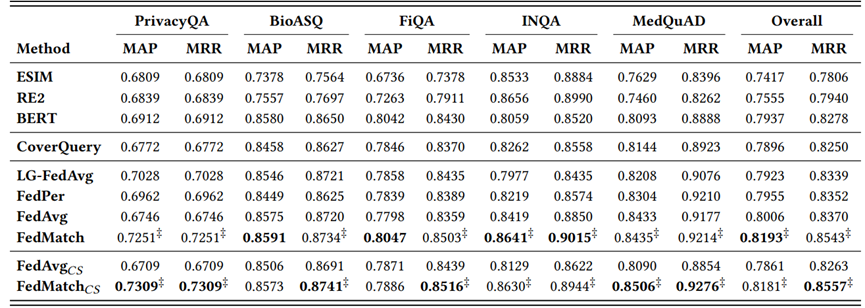

若有收获,就点个赞吧
0 人点赞
