- 分享主题:New Product Forecast、Multi-Modal
- 论文标题:Well Googled is Half Done: Multimodal Forecasting of New Fashion Product Sales with Image-based Google Trends
- 论文链接:https://arxiv.org/pdf/2109.09824.pdf
1.Summary
This paper studies the new product prediction of fashion retail products (clothing). The data set is a public data set of fashion clothing products (including Image data、Text data and Sales data). The model proposed in this paper uses a structure similar to Transformer, which is composed of encoder and decoder. The input of encoder is Google Trends data. And the input of decoder is the output of encoder, and Image Embedding, Text Embedding and Temporal Features Embedding output sales of n time units. Google Trends data is the search heat of different words at different times, such as black, cotton and medium coat. The model structure proposed in this paper is very similar to the Transformer structure proposed in “Attention Is All You Need”. If I fully understand this model, it may deepen my understanding of this article.2.你对于论文的思考
这篇文章使用了多模态表征作为输入,并且与其它新品预测文章不同的是,这里使用了Google Trends data,这使得输入的数据更加丰富了,这是这篇文章的一个创新点。
在实验部分,baseline中包含了”Attention based Multi-Modal New Product Sales Time-series Forecasting”这篇文章中提出的两个模型:Concat Multi-modal RNN和Cross-Attention RNN,这是KDD 2020年上的一篇文章,Cross-Attention RNN的效果相当好,很遗憾的是与之效果相当(平均效果略差)的Residual Multi-modal RNN没有出现在baseline中,当时的Concat Multi-modal RNN和Cross-Attention RNN并没有Google Trends data作为输入,因此,为了实验公平,Google Trends data也会被加入到这两个模型的输入中,同时也有不加Google Trends data的这两个模型作为baseline(防止Google Trends data产生负面影响)。此外,传统的KNN方法以及机器学习中强大的GBDT模型也会作为baseline。这样看来,实验设置很合理,baseline也很强(要是Residual Multi-modal RNN也加进来就好了)。因为Concat Multi-modal RNN和Cross-Attention RNN最初实验的数据集未公开,所以实验只能再别的数据集上进行,这可能使得实验没有那么完美。3. 其他
Google Trends data
Google Trends可以得到不同词在不同时间的搜索热度,本文中使用的Google Trends data包含了Color、Fabric、Categor这三个方面的各种词,如Black、Cotton、Medium coat,这使得输入的数据更加丰富了。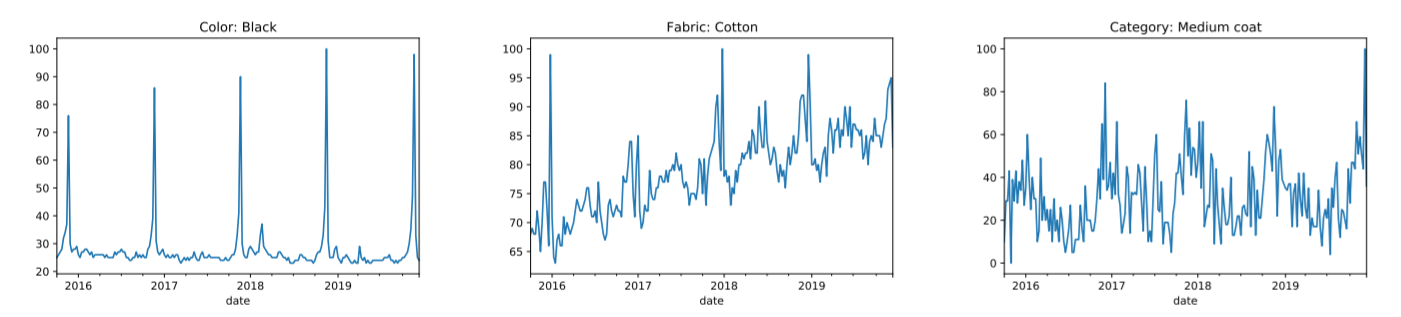
baseline
(G表示增加Google Trends data)
(1)Attribute KNN。使用了Text data;
(2)Image KNN。使用了Image data;
(3)Attribute + Image KNN。使用了Text data、Image data;
(4)Gradient Boosting。使用了Text data、Image data;
(5)Gradient Boosting+G。使用了Text data、Image data、Google Trends data;
(6)Concat Multimodal。使用了Text data、Image data;
(7)Concat Multimodal+G。使用了Text data、Image data、Google Trends data;
(8)Cross-Attention RNN。使用了Text data、Image data;
(9)Cross-Attention RNN+G。使用了Text data、Image data、Google Trends data。本文提出的模型
本文提出的模型名为GTM-Transformer(Google Trends Multimodal Transformer),使用了Text data、Image data、Google Trends data,在模型架构上模仿了Transformer,由Encoder和Decoder组成,Encoder的输入为Google Trends data,Decoder的输入为Encoder的输出以及Image Embedding、Text Embedding、Temporal Features Embedding,输出n数的销量。Encoder和Decoder的结构与Transformer中的一样,Image Embedding、Text Embedding、Temporal Features Embedding需要经过Feature Fusion Network(BatchNorm+Dense+ReLU+Dropout+Dense)处理后输入到Decoder中,其中的Dense就是全连接层(FC)。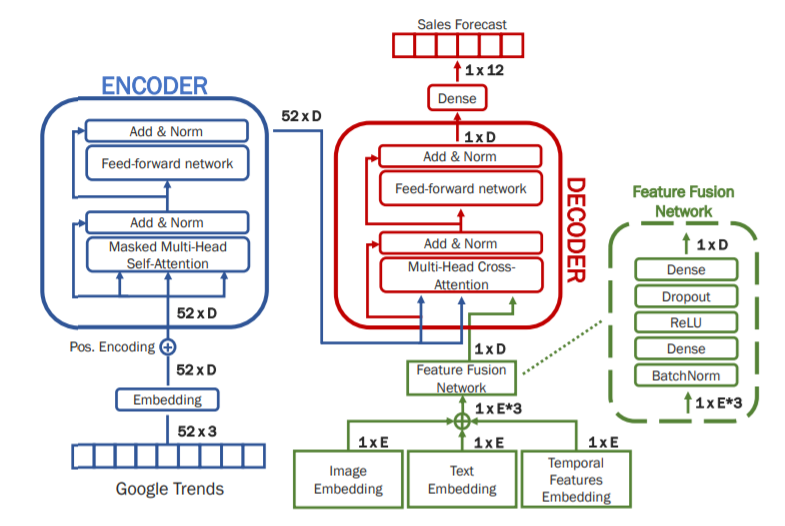
除此之外,本文还对Google Trends data处理的数据进行了改变,新增了“shape”属性(v领、下摆等),放弃了“fabric”等属性,形成了GTM-Transformer**模型。实验
实验用了WAPE、MAE、TS、ERP这四个指标。
WAPE:
MAE:
TS: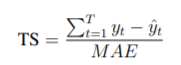
ERP(Edit distance with Real Penalty):如果y与y’的欧氏距离小于阈值ε,那么就认为它们之间的距离为0,否则它们之间的距离为1,就这样沿时间轴计算距离相加得出最终距离,最后除以时间轴的长度。
如图所示,GTM-Transformer的效果优于所有baseline方法,GTM-Transformer**略优于GTM-Transformer,可能是由于“shape”属性更优,增强了Google Trends data的效果,而“fabric”等属性在Text data中也是存在的,属于重复的属性,放弃这个属性可以提升模型效果。

若有收获,就点个赞吧
0 人点赞
