- 分享主题:Transfer Learning, Unsupervised Domain Adaptation, Explicit Feature Distribution Alignment, CV
- 论文标题:Domain Conditioned Adaptation Network
- 论文链接:https://arxiv.org/pdf/2005.06717.pdf
1.Summary
This is a paper about classification tasks. Now there is a source domain and a target domain. The source domain data is labeled and the target domain data is not labeled. So this is a unsupervised domain adaptation problem. In the past, the source domain and the target domain share a feature extractor. However, this paper thought that this method will hinder the shallow network from extracting domain specific features, thus affecting the effect of the model. To solve this problem, this paper proposes a model called Domain Conditioned Adaptation Network (DCAN). DCAN is composed of two parts. The first part is composed of some domain conditioned channel attention modules, and the second part is composed of some domain conditioned feature corrections. The domain conditioned channel attention module enables the source domain and the target domain to learn knowledge in their respective domains. The domain conditioned feature correction shared model, and uses MMD to measure the difference between the source domain and the target.Than takes this difference as part of the loss function, so as to align the source domain and the target domain. In order to deepen my understanding of this paper, I can read some papers about domain adaptation.2.你对于论文的思考
这是一篇关于DA的文章,作者认为,如果让源域和目标域共享一个网络,那么浅层网络会妨碍源域和目标域学习自己领域特定的特征,这样会影响模型的效果,因此,作者提出了DCAN模型,在模型的前面部分,两个域都有属于各自的一部分,以便于提取各自领域的特征,在模型的后面部分,就要开始对齐深层特征了,DCAN利用了MMD距离来衡量两者的差异,并作为损失函数的一部分,以此来对齐两个域的特征。3. 其他
3.1 需要解决的问题
要解决源域和目标域在共享模型的情况下,特定于领域的特征无法被有效提取的问题。3.2 DCAN

3.2.1 Domain Conditioned Channel Attention Module
如图所示,两个域不会共享第一个FC,这样有助于特定于领域的特征的提取。
下面的式子中,fs和ft分别是源域和目标域在经过各自fc后的特征,之后,两者经过同一个fc,得到的vs和vt作为注意力分数,与原本的特征相乘。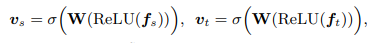
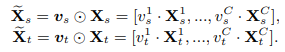
3.2.2 domain conditioned feature correction
如图所示,目标域为红色的线,是一个类似于残差结构的形式,目的是让它的输出与源域的特征接近,利用MMD来衡量两者的差异,得到以下损失函数:
同时,只加这个损失函数的话,那个可能会让目标域在两个FC中提取一些没用的信息(仅仅是为了让两个域匹配的信息),因此还要让部分源域数据也通过特征校准模块用于正则化,加入以下损失函数:
3.2.3 总体损失函数
除了3.2.2中的损失函数,还要再加入源域数据的标签分类损失,由于目标域数据没有标签,因此利用条件熵损失来防止模型对目标域数据标签的预测过度偏离。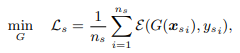
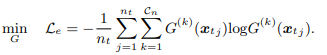

3.3 实验
(1)数据集:Office-31
(2)数据集:Office-Home
(3)消融实验
数据集:Office-31
(4)特征可视化(利用了t-SNE降到了二维)
图中蓝色和红色代表不同的域,DCAN效果很明显。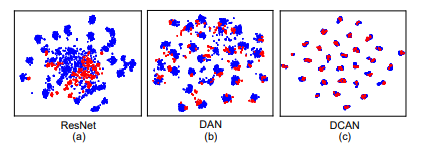

若有收获,就点个赞吧
0 人点赞
