- 分享主题:Transfer Learning, Unsupervised Domain Adaptation, Adversarial, CV
- 论文标题:Self-adaptive Re-weighted Adversarial Domain Adaptation
- 论文链接:https://arxiv.org/pdf/2006.00223.pdf
1.Summary
This is a paper about classification tasks. Now there is a source domain and a target domain. The source domain data is labeled and the target domain data is not labeled. So this is a unsupervised domain adaptation problem. The model proposed in this paper has two innovations. The first point is that this paper gives different weights to different samples. The larger the entropy is, the higher the sample weight is. The second point is that the model will bring samples of the same category closer and samples of different categories farther. This can help align the conditional probability distribution. In order to deepen my understanding of this paper, I can read some papers about domain adaptation.2.你对于论文的思考
这是一篇关于DA的文章,与以往基于域对抗的方法不同的是,这篇文章的模型可以对不同的样本赋予不同的权重,标签预测器预测的结果熵越大,那么说明越要重视,权重就要越大;此外,为了对齐条件概率分布,还是用了三元组损失,拉近类内的距离,拉远类间的距离。3. 其他
3.1 解决的问题
1.赋予不同的样本以不同的权重;2.三元组损失,帮助条件概率分布的 对齐。3.2 模型
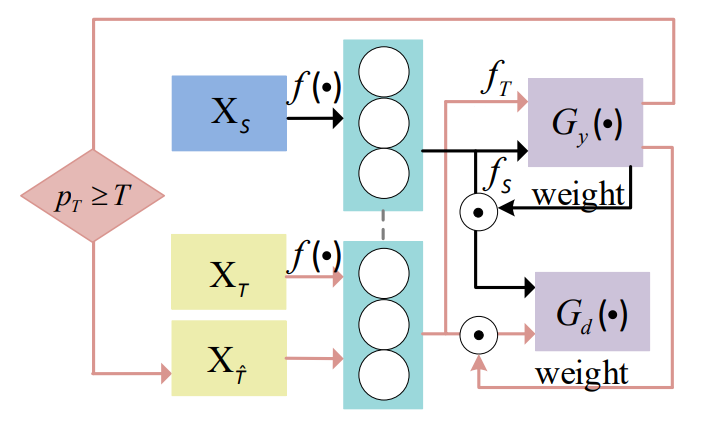
3.2.1 标签分类损失
源域数据有标签,计算标签分类损失: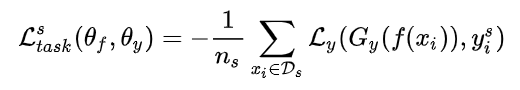
3.2.2 域对抗损失
常规的损失函数: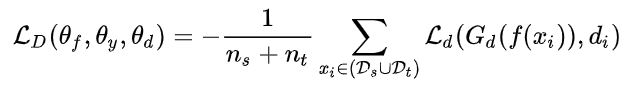
3.2.3 加权
预测标签时熵越大的样本,权重就越大。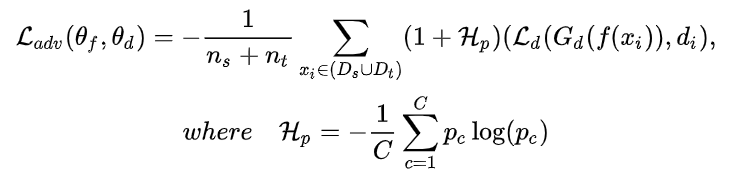
3.2.4 熵最小化
因为目标域没有标签,所以只能熵最小化。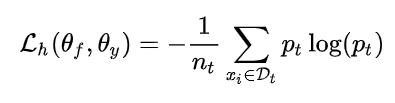
3.2.5 Triplet loss
利用三元组损失,拉近类内距离,拉远类间距离。
为了防止一些预测的不太好的样本来捣乱,所以要设置一个阈值,只有预测的足够好的样本才能进行三元组损失。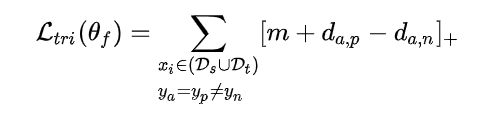
3.2.6 总体损失函数
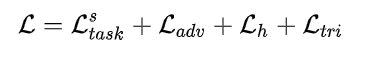
优化目标: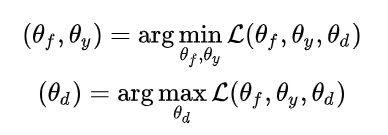
3.3 实验
(1)与baseline的对比: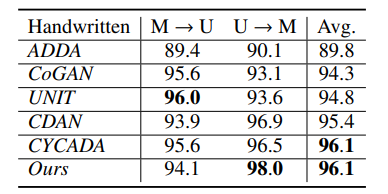
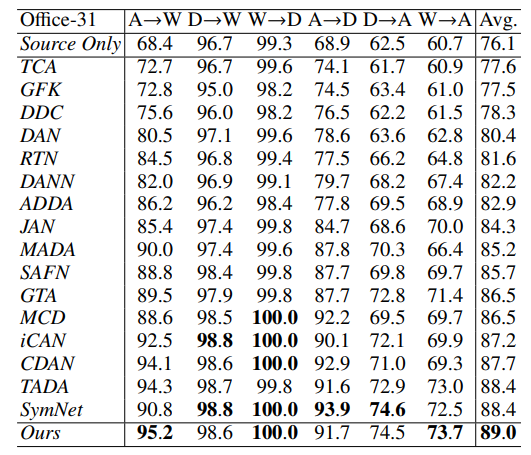
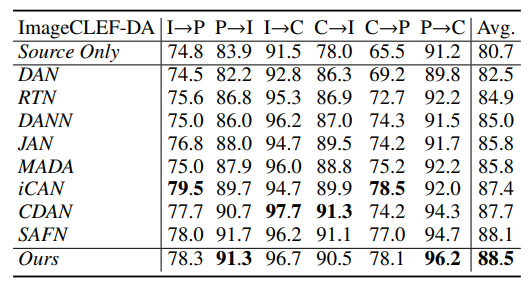
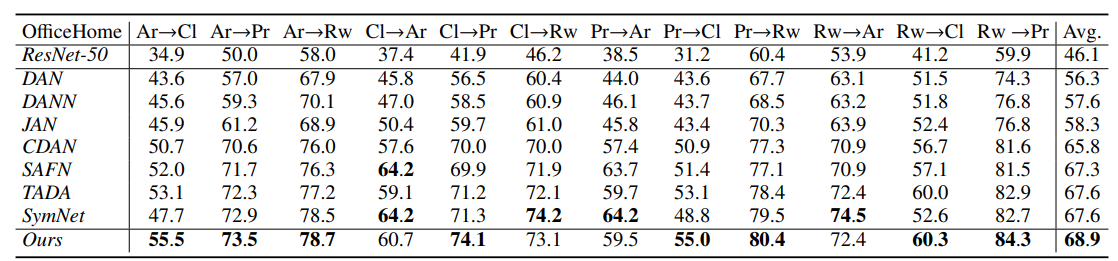
(2)消融实验: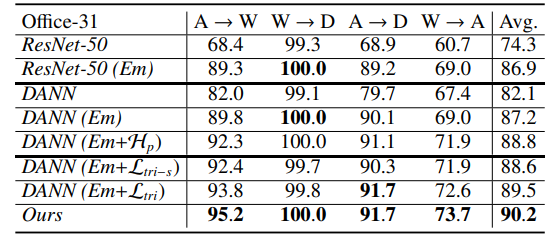
(3)特征可视化(利用了t-SNE降到了二维)
本文的模型效果最好。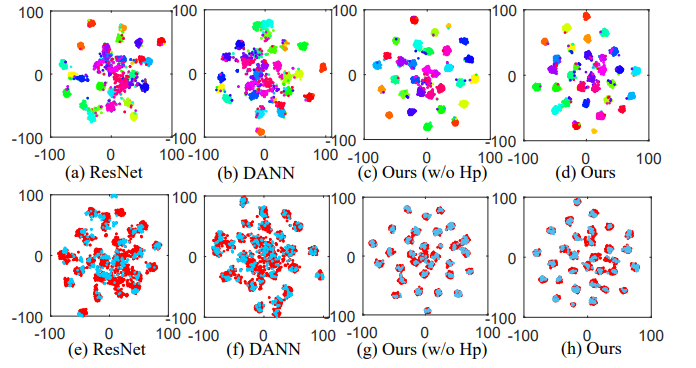

若有收获,就点个赞吧
0 人点赞
