- 分享主题:Transfer Learning、New Product Forecast
- 论文标题:A Survey on Deep Transfer Learning
- 论文链接:https://arxiv.org/pdf/2005.06978.pdf
1.Summary
This paper studies the application of transfer learning in new product forecast. The data set uses data from an Austrian food retail company (non-public). There are 14 old products used for transfer learning. They all have data for about two years. They use a total of 26 features of date, price, promotion, identity, lag, aggregate and external. The prediction granularity is the total sales volume of one week. No prediction is made in the first two weeks. And the data of the first two weeks will be used for prediction. The prediction range is from the third week to the thirteenth week.<br /> In this paper, the Network-based deep transfer learning method is used in MLP. There are three hidden layers in MLP. First, 14 old products will be trained with MLP alone, and then the 14 trained models will be transferred to the task of new product prediction.<br /> The method used in this article is mentioned in the previous review. If I read some other papers using the same method (not limited to time series prediction), it may deepen my understanding of this paper.
2.你对于论文的思考
这篇文章的主要贡献就是把迁移学习应用到了新品预测问题上,把迁移学习应用到时序预测中的论文还是比较少的。这篇文章利用了Network-based deep transfer learning的思想来解决新品预测问题,文中的MLP一共有三层隐藏层,源域中训练好的这三层都会被迁移到目标域中,但是实验分别做了三种配置:这三层都能被目标域中的数据进行训练、第一层不能训练而后两层能进行训练、前两层不能训练而最后一层能进行训练,实验设置的还是挺好的,最后结果表明,在新品数据量少的时候,第二种配置的效果好于第一种,可能是因为迁移过来的模型中的数据对结果的预测比较有帮助;而在新品数据量累积到一定程度的时候,第一种配置的效果好于第二种,因为这时模型就需要更多的自由度(更多可以被训练的隐藏层)。而第三种配置的效果最差,可能是因为模型的自由度太低了,学习到的新品自身的东西太少了。<br />但是感觉文中使用的baseline有点单薄,只是用了MA和只用新品数据训练的MLP,没有用经典(传统)的KNN找相似品的方法(也许是因为数据集产品种类太少了吧),也没有用深度学习的一些encoder-decoder结构的模型(不是本文中的只用新品数据训练的MLP,训练数据更加丰富,包括老品的数据)。<br />总而言之,本文的迁移学习方法也算是给新品预测提供了一个新的思路。
3. 其他
baseline
(1)MA:前两周销量的平均值;
(2)w/o TL:(不使用迁移学习,只使用新品前两周的数据,利用MLP(共三个隐藏层)来进行预测)本文提出的模型
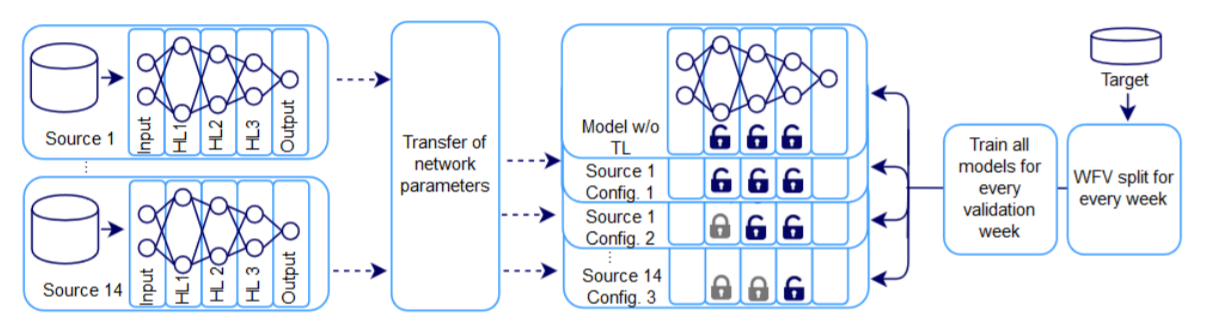
对14种老品分别使用MLP(共三个隐藏层)进行训练,之后把这14个训练好的模型迁移到新品预测的任务上,这14种模型的每一种单独用新品数据以及三种不同的配置进行训练:
(1)Config 1:三个隐藏层都可以进行训练;
(2)Config 2:第一个隐藏层不可进行训练(参数都不能改变),后两个隐藏层可以进行训练;
(3)Config 3:前两个隐藏层不可进行训练(参数都不能改变),最后一个隐藏层可以进行训练。
从而获得14*3个模型。
此外,文章中还对14个老品以及1个新品进行了分类,分类标准为Mean sales(每小时平均销量)、Price、Promotion(促销日的比例),每一种分类的值有三种:Low、Medium、High,用以分析不同的分类对迁移学习的影响。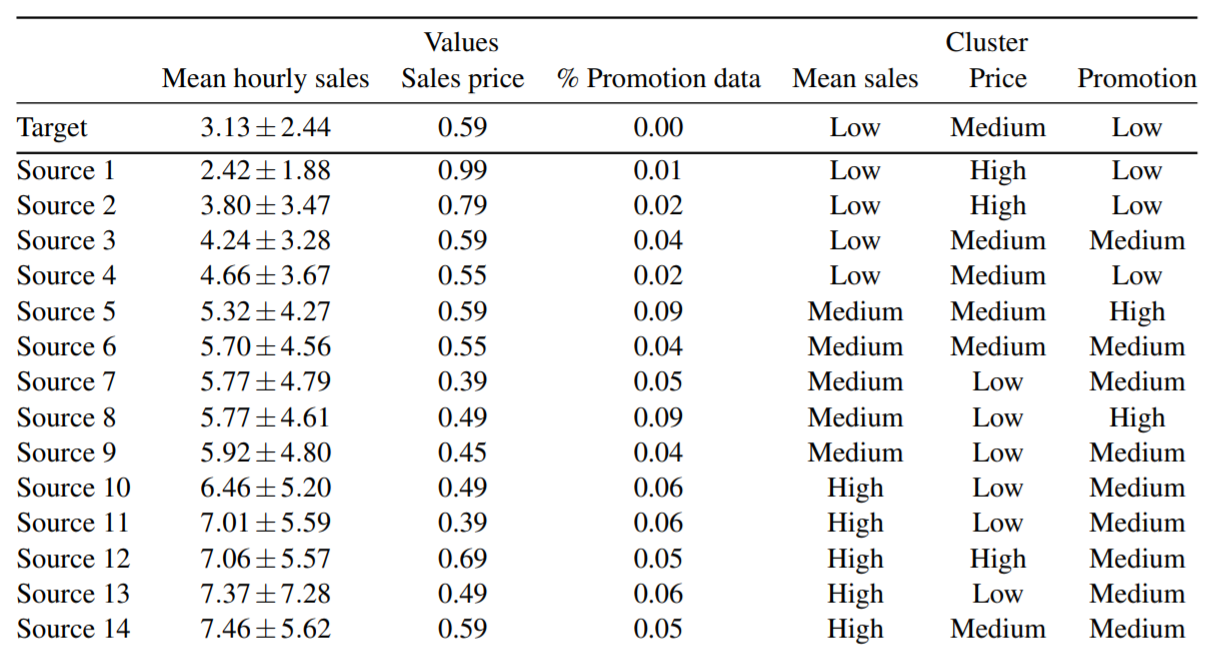
实验结果
如下图所示,利用了迁移学习的模型效果要普遍好于baseline,由于第三周和第四周的新品数据少,所以迁移学习的模型效果要格外好;第一、二、三、四、五周是无促销的周,第六、七周是促销周,因为在第六周之前新品没有促销的记录,因此baseline对于首次来的促销周反应很大(效果很差),而迁移学习的模型中有相关数据的学习,所以效果要好于baseline;Config 3的效果要差于Config 1和Config 2,可能是由于模型的自由度太低了,学习到的新品自身的东西太少了;Config 2在前12周的效果要略好于Config 1,在后来几周略差于Config 1,可能是由于前12周新品数据较少,迁移过来的模型中的数据对结果的预测比较有帮助,而后新品数据变多,Config 2效果就下降了;在三种分类(Mean sales、Price、Promotion)中,Price分类的准确率最好。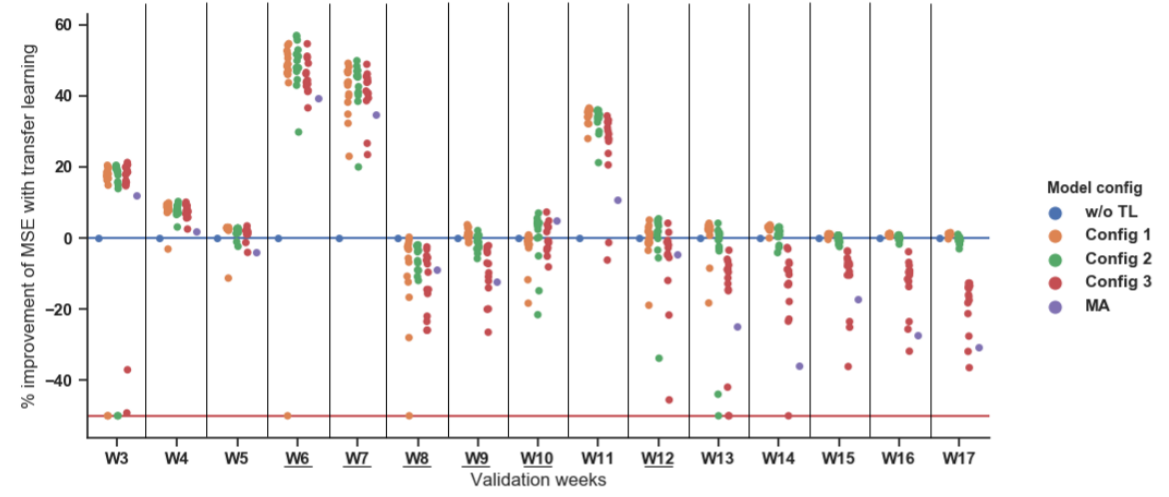
在文章的最后,作者利用的集成学习的方法,先对老品按Mean sales、Price、Promotion分别分类,每一种分为Low、Medium、High三种不同的标准,例如对于按Mean sales分类,把14*3个模型分类到Low、Medium、High三种类别中,每一种类别求均值作为最后的结果,最终结果表明,集成学习后的迁移学习的模型效果要全部好于baseline。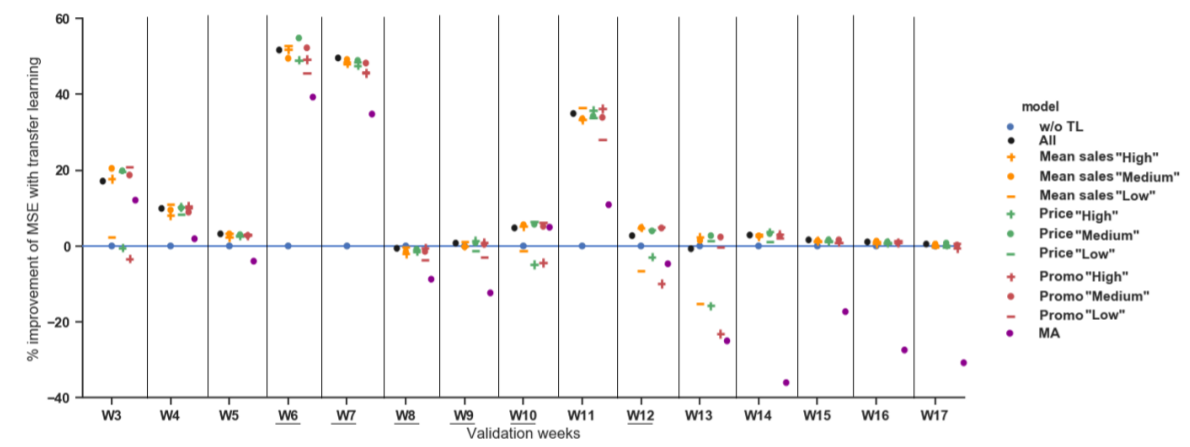

若有收获,就点个赞吧
0 人点赞
