- 分享主题:Transfer Learning, Domain Generalization, Explicit Feature Distribution Alignment, Adversarial
- 论文标题:Domain Generalization Using a Mixture of Multiple Latent Domains
- 论文链接:https://arxiv.org/pdf/1911.07661v1.pdf
1.Summary
This is a paper about picture classification. Suppose there are many pictures belonging to different domains. Now we need to use these pictures to train a model to predict the picture label on an unseen target domain. Some previous papers assumed that the domain label of the picture was known, while this paper assumed that the domain label of the picture was unknown, because this is often the case in reality. In order to use transfer learning to help knowledge transfer, domain label is very important. In order to solve the problem of unknown domain label, the model proposed in this paper extracts the features of the shallow neural network of the feature extractor, calculates the mean and standard deviation, and then uses K-means for clustering to obtain the domain label. After that, you can use the adversarial method to train the model. In order to deepen my understanding of this paper, I can read some papers on transfer learning when the domain label is unknown.2.你对于论文的思考
这是一篇关于利用迁移学习来提升图片分类效果的文章,以往的论文背景往往是源域中图片的域标签是可知的,但是现实中,可能会出现许多不带域标签的、各类图片随意混合在一起的数据集,这时候如果把它当作一个域的话,迁移效果可能会比较差,为了解决这个问题,这篇文章提取了生成器的浅层网络的特征,并计算出均值和标准差,然后使用k-means算法进行聚类,从而得到各个图片的域标签,之后就可以通过对抗的方法来进行迁移学习了。
对于多个域的对抗的迁移学习(目标域是未知的),这篇论文在域判别器上的目标是尽可能准确的预测域标签,生成器的目标是尽可能让域标签的预测不准确,但是最终目的是让所有域都能比较好的混淆在一起,而它仅仅是让域标签预测不准确,这样的话,就比如说有十个源域,可能训练到最后其中五个混淆的比较好,剩下五个也混淆的比较好,这样就没法使得所有源域都混淆的比较好了。
除此之外,因为这篇文章的任务是分类,在对抗的过程中可能会出现一些样本在分类边界的情况,这会使得分类变得困难,为了解决这个问题,论文在损失函数中添加了一个熵函数,以此来减少标签预测器的预测为各类结果的熵,使得预测结果更为明确和稳定。3. 其他
3.1 解决的问题
左下图是传统的域泛化,右下图是本文解决的问题,所有域混合在一起,域标签是未知的,或者是有多个数据集,每一个数据集都是由多个域的数据混合在一起的。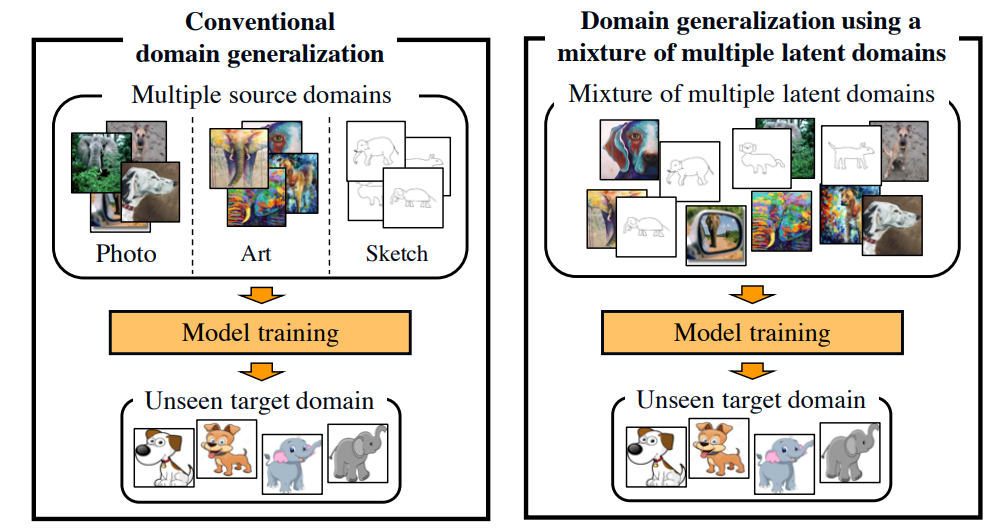
3.2 迁移学习模型
如下图所示,利用了对抗的方法来进行迁移学习。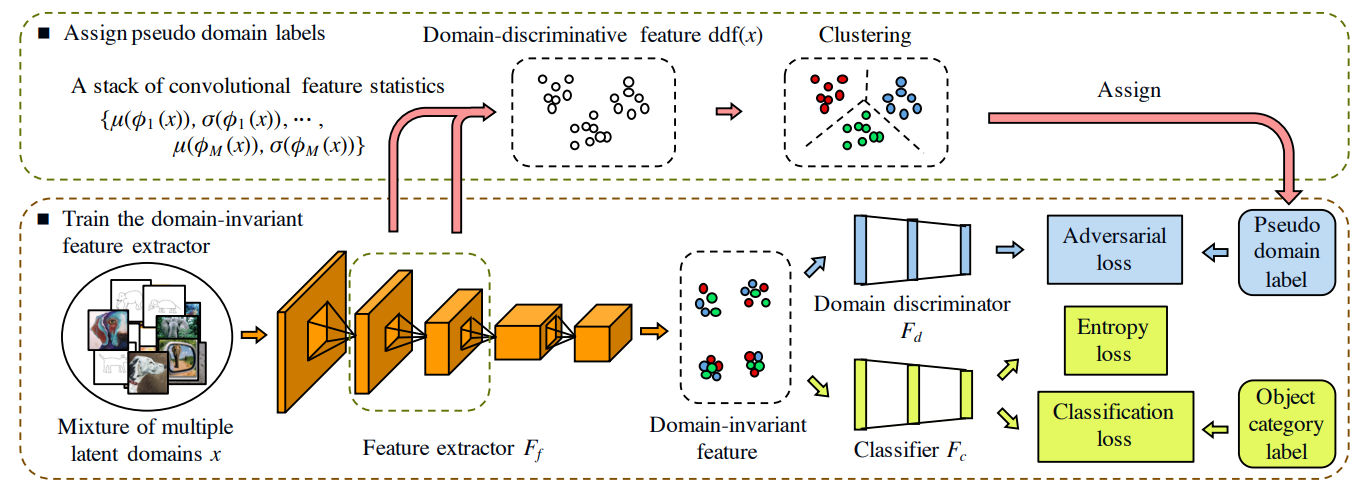
3.2.1 域标签预测
计算生成器浅层网络特征的均值和标准差
计算生成器浅层网络特征的均值和标准差: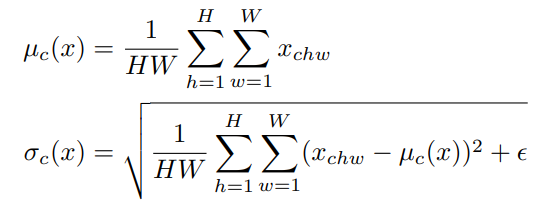
得到: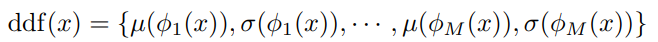
聚类
使用k-means对上述得到的均值和标准差进行聚类,但是k-means仅仅是把所有样本分为k类,因为在每一个epoch都会重新聚类一次,因此每一个样本的域标签可能会发生变化,也就无法确定分出来的k类,每一类的域标签是什么了。为了解决这个问题,本文在重新聚类时,选择了标签变化最小的一种情况,正如下面这个式子: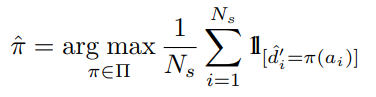
3.2.2 迁移部分
标签损失
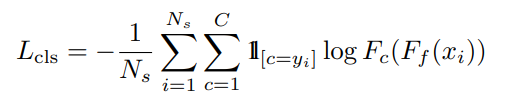
域标签分类损失
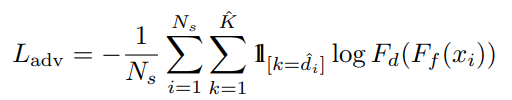
熵函数
在对抗的过程中可能会出现一些样本在分类边界的情况,这会使得分类变得困难,所以添加了下面这个熵函数,以此来减少标签预测器的预测为各类结果的熵,使得预测结果更为明确和稳定。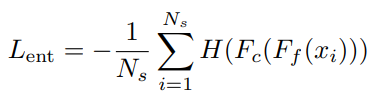
总体损失函数如下: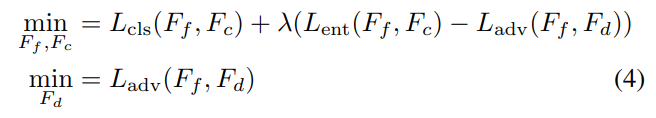
3.3 实验
(1) PACS数据集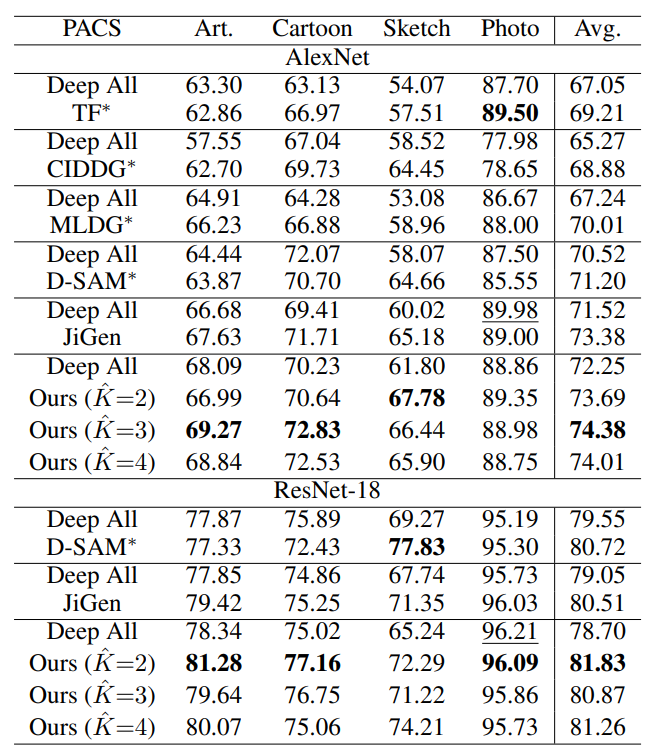
(2)VLCS数据集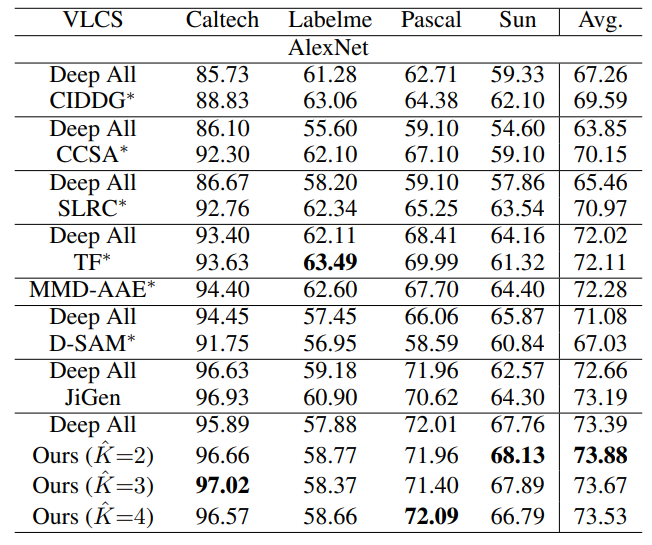
(3)消融实验(PACS数据集)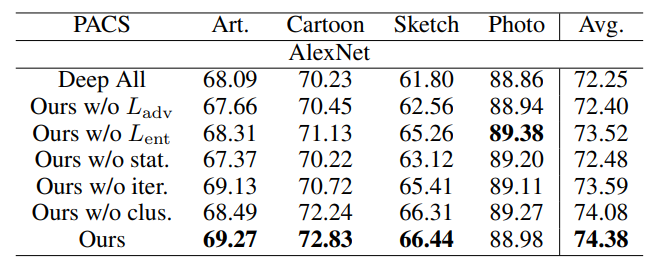

若有收获,就点个赞吧
0 人点赞
