- 分享主题:Transfer Learning, Unsupervised Domain Adaptation, CV, Adversarial
- 论文标题:Transferable Adversarial Training: A General Approach to Adapting Deep Classifiers
- 论文链接:http://proceedings.mlr.press/v97/liu19b/liu19b.pdf
1.Summary
This is a paper about classification tasks. Now there is a source domain and a target domain. The source domain data is labeled and the target domain data is not labeled. This paper uses the adversarial method to realize the transfer of knowledge. This article argues that the previous method does not take into account that in the process of aligning the source domain and the target domain, the original representation generated by the feature extractor will be gradually distorted and some useful information will be lost. In order to solve this problem, this article proposes a model called Transferable Adversarial Training (TAT). TAT first uses the source domain data to pre-train the feature extractor. Then, transferable examples are generated. These examples need to be as close to the original representation output by the feature extractor as possible, and the examples of the source domain can predict the label as much as possible through the classifier, and the examples of the source domain and the target domain should be as close as possible. This step does not require updating the parameters of the model. The last step is to use transferable examples and original representations to train using adversarial method. In this way, the original representation can be retained as much as possible, and the distance between the transferable examples of the source domain and the target domain can be shortened. To deepen my understanding of this paper, I can read some papers related to unsupervised domain adaptation.2.你对于论文的思考
这是一篇关于UDA的论文,解决的是分类任务,这篇文章认为之前的域对抗方法会逐渐让特征提取器生成的原始表征逐渐歪曲,损失一些有用的信息,所以这篇文章提出了TAT模型,TAT不仅可以实现DANN的作用(拉近源域和目标域的距离、并尽可能让源域的标签预测准确),而且可以尽可能保留原始表征的信息。3. 其他
3.1 解决的问题
这篇文章解决了非监督的域自适应问题,优化了以往的域对抗的迁移学习方法,可以使得原始表征的信息尽可能保留下来(不被过度distort)。3.2 TAT
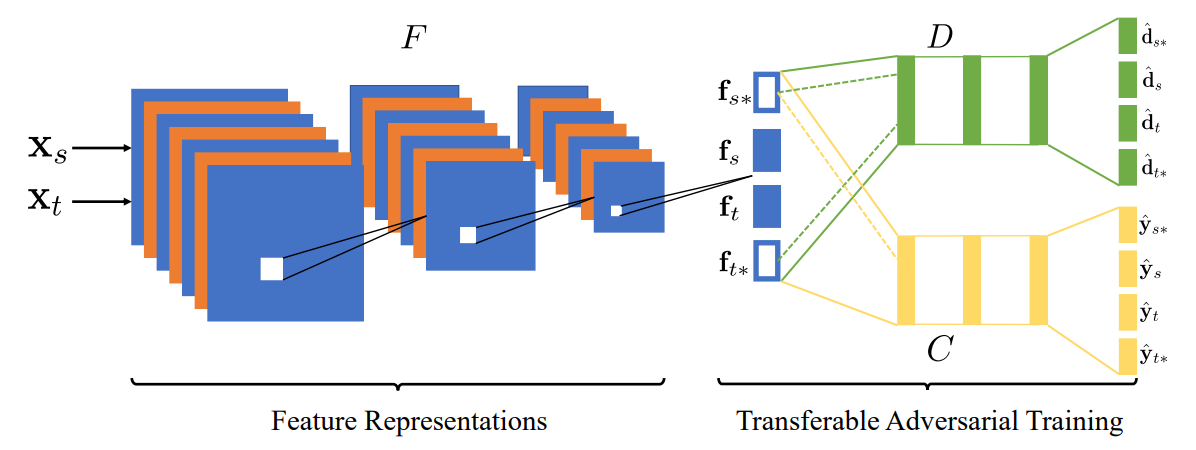
3.2.1 预训练特征提取器F
利用源域的数据预训练模型(由特征提取器F和分类器C组成),训练好的特征提取器F可以提取源域和目标域的原始表征(不进行对齐的表征)。3.2.2 Adversarial Generation of Transferable Examples
下面的左图是上一步训练好的表征,这一步的目的就是生成右图中的Transferable Examples,它们需要满足下面几点:
(1)尽可能和原始的表征接近;
(2)源域上生成的Transferable Examples能尽可能利用上一步预训练好的C预测标签;
(3)源域和目标域上生成的Transferable Examples要尽可能接近。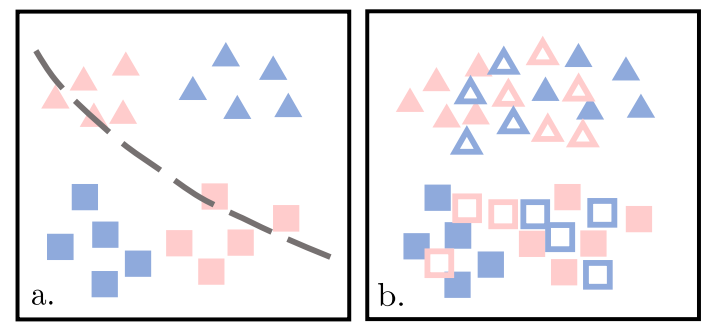
并且在这一步,不需要更新模型的参数,只需要生成Transferable Examples,具体公式如下(每一次迭代都根据原始表征和分类器C以及判别器D重新生成Transferable Examples,并且Transferable Examples经过K次的更新才生成最终的Transferable Examples,再把这个最终的Transferable Examples输入到下一步中):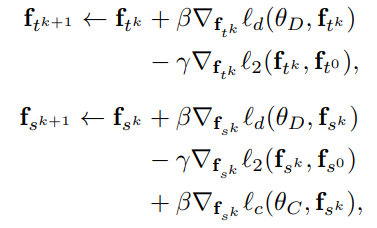
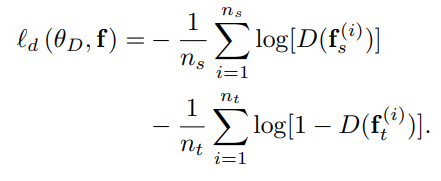
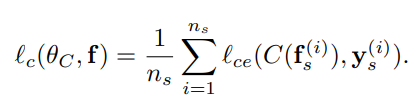
3.2.3 Adversarial Training with Transferable Examples
这一步需要利用原始表征和Transferable Examples来训练模型。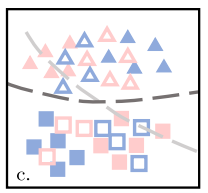
损失函数如下: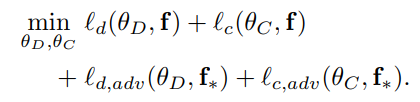
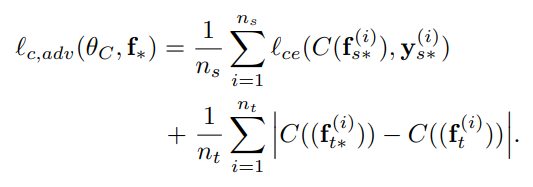
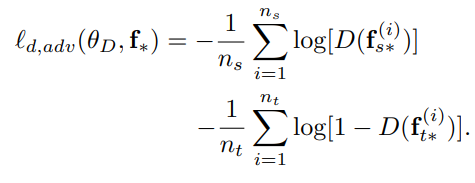
前面的两部分是域对抗迁移学习(DANN)的常规损失函数,第三部分是对Transferable Examples进行的域标签的分类损失,第四部分的第一个式子是源域原始表征生成的Transferable Examples的标签的分类损失,由于目标域数据没有标签,没有办法求标签的分类损失,于是希望目标域的原始表征和Transferable Examples经过分类器后的输出能尽可能相同(这样是希望Transferable Examples不能和原始表征差距太大,仍然能起到保留原始表征中对分类有用的信息)。3.2.4 整体流程

3.3 实验
(1)数据集:Office-31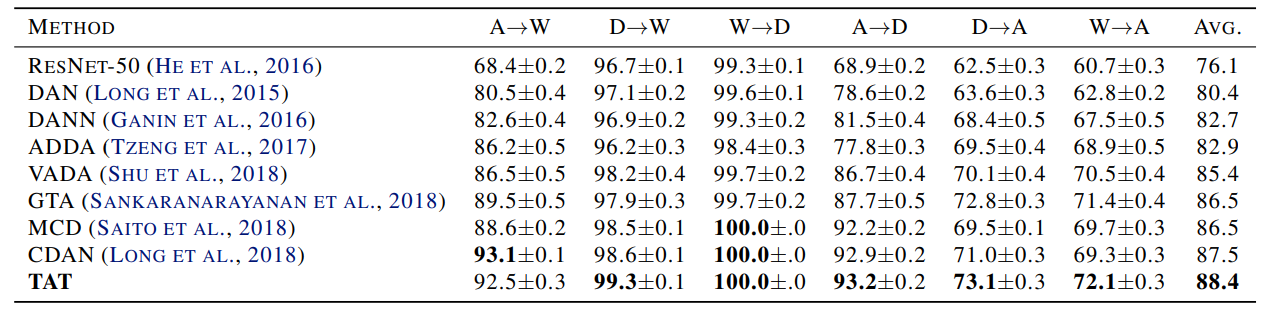
(2)数据集:Image-CLEF
(3)数据集:Office-Home
(4)数据集:VisDA-2017
(5)消融实验
数据集:Office-31

若有收获,就点个赞吧
0 人点赞
