- 分享主题:CV, Transformer
- 论文标题:Training data-efficient image transformers & distillation through attention
- 论文链接:https://arxiv.org/pdf/2012.12877.pdf
1.Summary
This is a paper about applying transformer to CV field. Before this paper, there is already a model called ViT. This paper is an improvement of the ViT model. In order to enhance the effect of the model, the Data-efficient image Transformers (DeiT) model proposed in this paper adds a distillation token on the basis of ViT, and its output at the corresponding position should be aligned with the prediction result of a teacher model. The teacher model is a pre-trained model. It can be a CNN model or a Transformer model. In addition to the changes to the model, DeiT also optimizes data augment and regularization to make the model more effective. In order to deepen my understanding of this paper, I can read some information about vit, data enhancement and regularization.2.你对于论文的思考
这篇文章提出的DeiT模型是对ViT模型的优化 ,DeiT在ViT的基础上增加了一个distillation token,它与class token的区别就是,class token需要与真实的标签拟合,而distillation token需要与teacher model的输出对齐,这个teacher model是与训练好的模型,文章中使用了CNN模型和Transformer模型,并分别测试了他们的效果。此外,DeiT还从数据增强和正则化对ViT进行了优化。最终的实验效果也是超过了ViT和CNN模型。3. 其他
3.1 DeiT
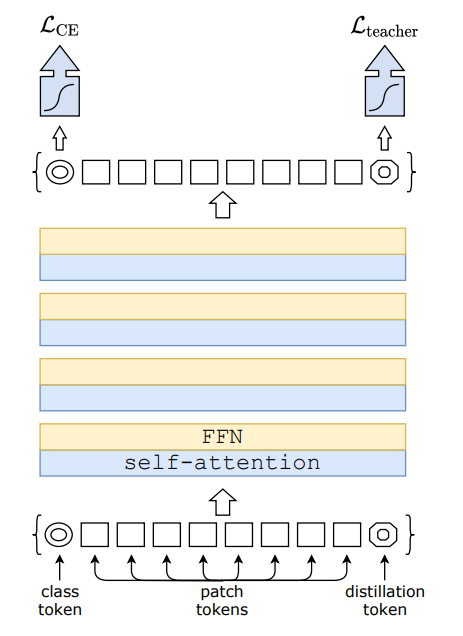
distillation token
与class token相似,也是在输入中加入,不过distillation token是加入到最后一个位置,而且class token需要与真实标签进行拟合,而distillation token需要与teacher model的预测结果对齐,对齐方式有两种:
(1)软蒸馏(soft distillation)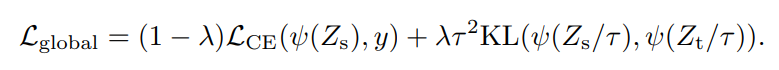
(2)硬蒸馏(hard distillation)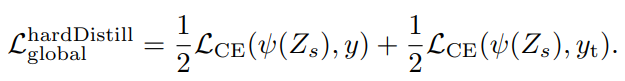
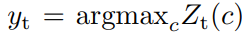
3.2 实验
3.2.1 参数设置

3.2.2 teacher model对比
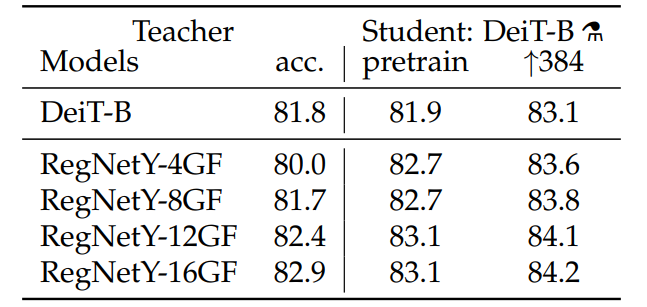
可以看出,用CNN模型作为teacher model的效果好于Transformer模型,可能是因为student model学习到了CNN模型的归纳假设,在一定程度上弥补了Transformer模型的弱点。3.2.3 distillation方式对比 & class token与distillation token对比
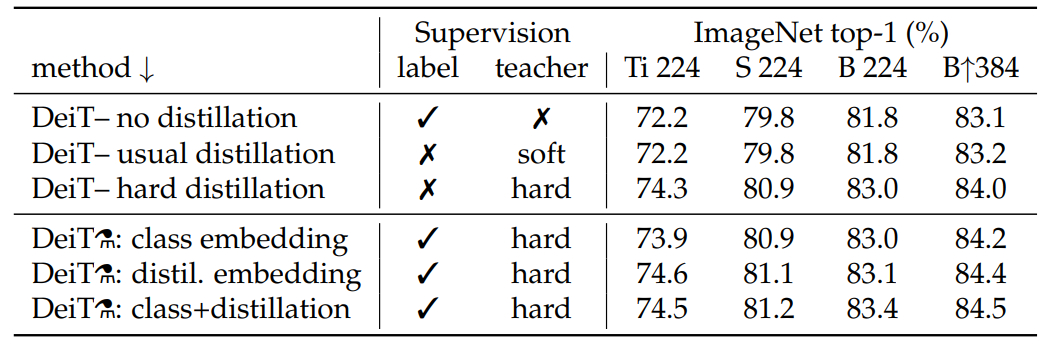
hard distillation优于soft distillation。
加入distillation token可以提升模型效果,并且它的作用比class token大,可能是distillation token可以学习到CNN模型的归纳偏置。3.2.4 与baseline的对比
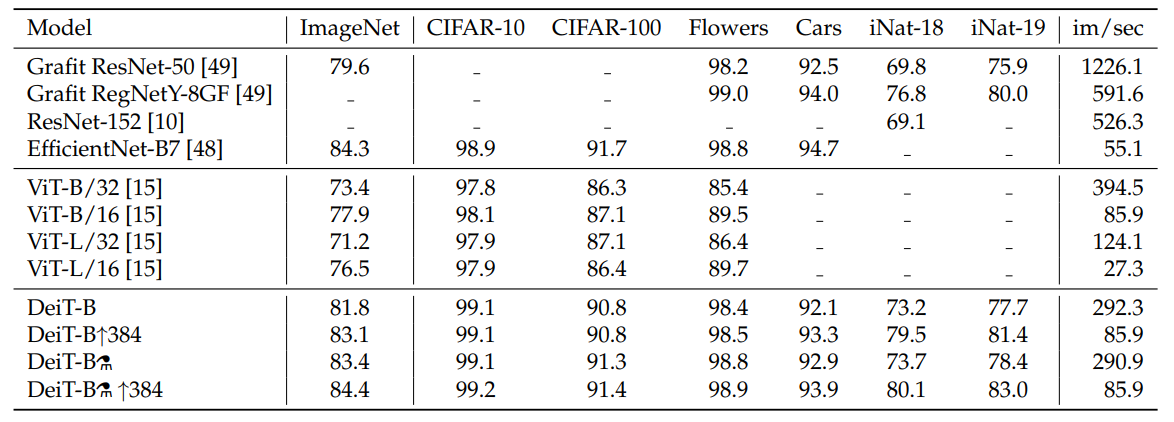
DeiT的效果几乎比CNN模型和ViT都要好。3.3 训练细节
3.3.1 优化器、数据增强、正则化
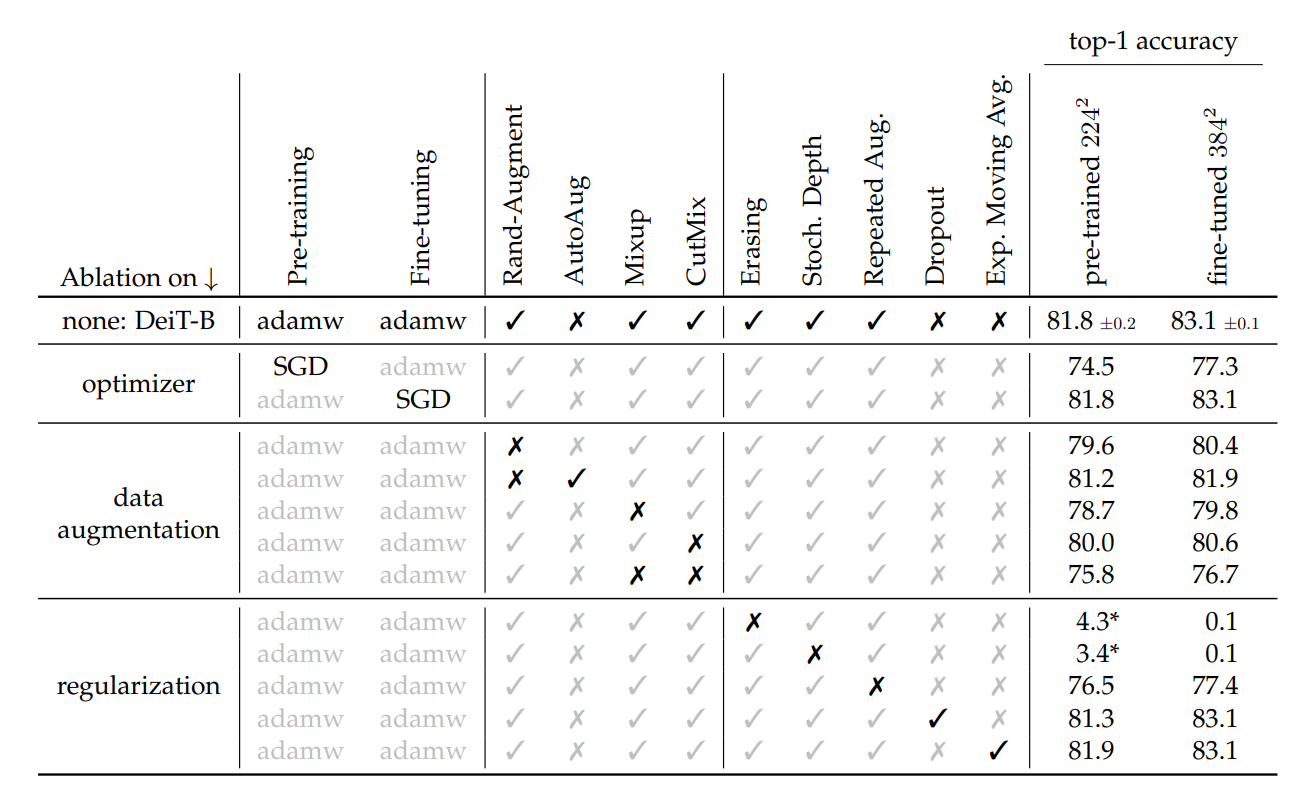
adamw的效果要比SGD好;几乎所有的数据增强方法都能提升模型性能;dropout对模型帮助不大,Moving Avg对模型的帮助很小。3.3.2 fine-tune时用的图片的分辨率

fine-tune时用的图片的分辨率越大,效果就越好。

若有收获,就点个赞吧
0 人点赞
