- 分享主题:Federated Learning
- 论文标题:Federated Machine Learning Concept and Applications
- 论文链接:https://arxiv.org/pdf/1902.04885.pdf
1.Summary
This is a survey of federal learning. This paper introduces the background of federal learning, the privacy technology of federal learning and the categories of federal learning. The privacy technologies of federated learning are divided into secure multi-party computation, differential privacy and homomorphic encryption. Federal learning is divided into horizontal federated learning, vertical federated learning and federated transfer learning. Then it also introduces the related work of federal learning and some applications. There are many concepts and methods involved in this article. I can deepen my understanding of this paper by consulting materials and reading some relevant papers.2.你对于论文的思考
这是一篇关于联邦学习的综述论文,文章介绍了一些隐私技术和联邦学习的方法,大多都只是介绍一下,其中纵向联邦学习讲的比较详细,还举了一个线性回归的例子,帮助我加深了对这种方法的理解。3. 其他
简介
现在人工智能面临着数据孤岛的问题,处于隐私保护等原因,数据在很多情况下禁止被收集到一起训练模型,因此,本文介绍了一种叫联邦学习的方法,可以在数据被孤立的情况下训练机器学习模型。
假设有N个数据持有者{F1,F2,…FN},他们希望用各自数据一起训练一个机器学习模型,常规的方法是直接把所有数据放在一起集中训练,得到一个模型Msum,但是这样的话,他们的数据直接就泄露出去了,因此,可以用联邦学习的方法,不比把所有数据集中到一起,而是各个数据的持有者协同训练一个机器学习模型Mfed,在训练的过程中,各自的数据都不会泄露。如果Msum的准确率为Vsum,Mfed的准确率为Vfed,如果满足一下式子(其中δ为一个非负实数),那么称这个联邦学习模型满足δ-accuracy loss。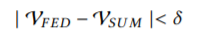
联邦学习的隐私技术
安全多方计算(Secure Multi-party Computation)
SMC是一个涉及多方的安全模型,它期望能保证完全的zero knowledge,也就是参与计算的每一方除了自己的输入和模型的输出外什么也不知道。zero knowledge一般需要复杂的计算协议,有时甚至无法实现。差分隐私(Differential Privacy)
这一类方法是使用差分隐私技术或k-Anonymity来保护数据隐私的,通过在数据中添加噪声或使用一些方法对某些敏感属性进行模糊处理,使得数据无法恢复,从而避免向第三方泄露数据。但这些方法仍然需要把处理后的数据传输到其它地方,有时需要在模型的准确率和数据隐私保护之间进行权衡。同态加密(Homomorphic Encryption)
与差分隐私不同,这种方法不需要传输用户的数据和模型,而是对机器学习模型训练过程中的一些参数进行加密后再传输,这样的话,用户的原始数据被泄露的可能性就会很小。
在实际应用中,加法同态加密得到了广泛应用,但是在机器学习算法中需要对非线性函数进行多项式逼近,所有有时需要在模型准确率和隐私保护之间进行权衡。联邦学习的类别
假设用户i持有的数据集为Di={I:ID space, X:features space, Y:label space}横向联邦学习(Horizontal Federated Learning)
横向联邦学习满足以下式子: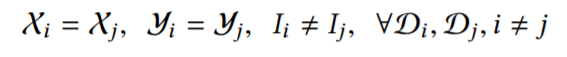
如下图所示,不同用户持有的数据集共享相同的特征空间,而且数据ID的交集小。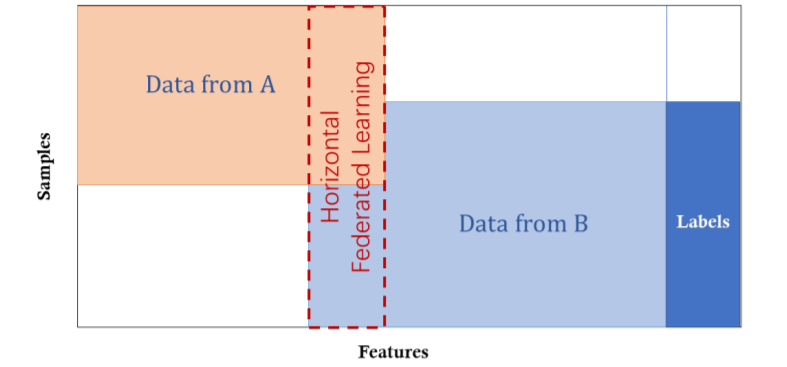
横向联邦学习的训练步骤:
(1)参与者本地计算计算梯度,使用加密、差异隐私等技术屏蔽梯度,并将屏蔽结果发送给服务器;
(2)服务器在没有关于任何参与者学习信息的情况下执行安全聚合;
(3)服务器向所有参与者发送聚合的结果(总梯度);
(4)根据解密后的总梯度,参与者可以更新它们各自的模型。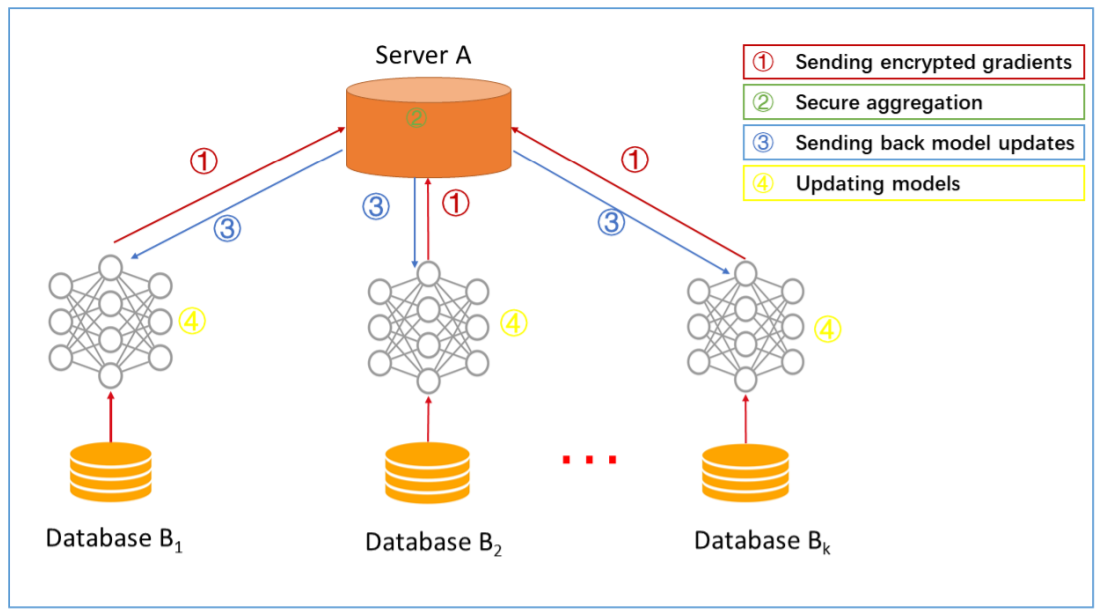
纵向联邦学习(Vertical Federated Learning)
横向联邦学习满足以下式子: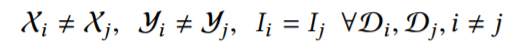
如下图所示,不同用户持有的数据集的特征空间是不一样的,数据ID的交集大,标签只在一方的数据集中存在。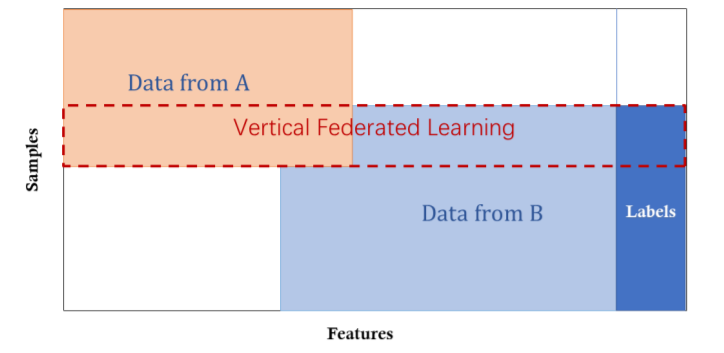
由于数据隐私和安全原因,A和B不能直接交换数据,为确保训练过程中数据的保密,需要第三方C。
纵向联邦学习的训练步骤:
(1)C创建一对密钥,分别发送给A和B;
(2)A和B加密和交换中间结果,进行梯度和损失计算;
(3)A和B分别计算加密梯度,并分别添加附加掩码,B还计算加密后的损失,之后A和B向C发送加密值;
(4)C解密并发送解密梯度和损失到A和B,A和B可以利用梯度更新模型参数。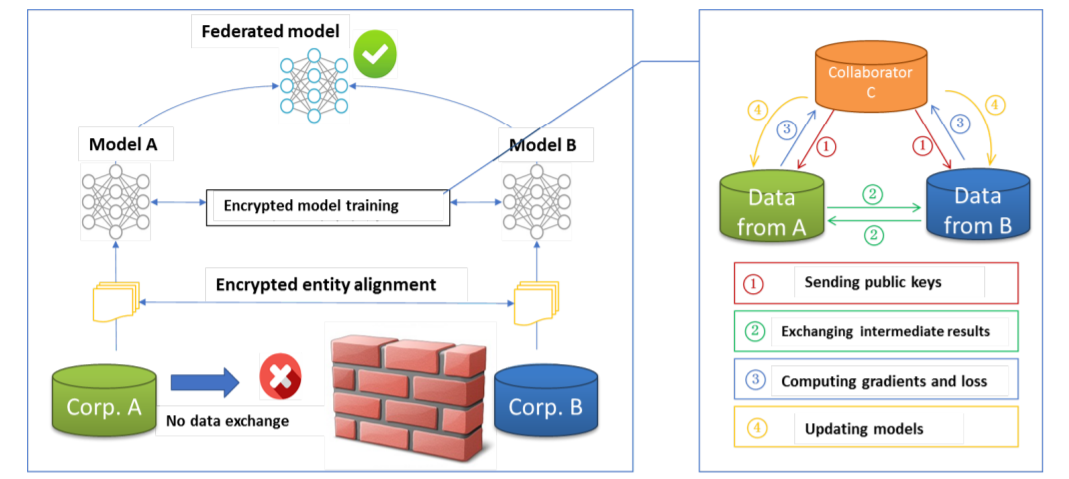
纵向联邦学习在线性回归中的应用:
(1)训练过程:
训练目标为: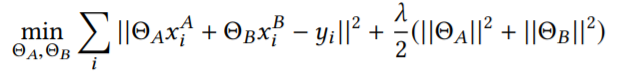
加密后的损失为: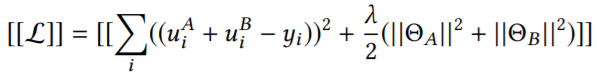
可以把上面的[[L]]分为三个部分: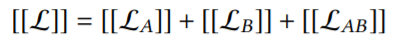
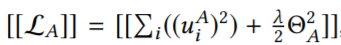
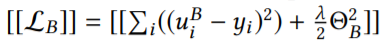
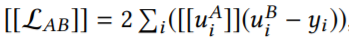
梯度如下: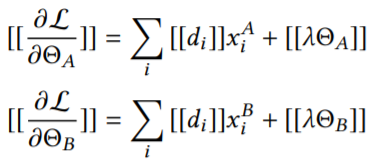
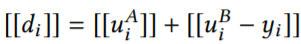
step 1:A和B初始化各自的参数,C生成一对密钥,分别发送给A和B;
step 2:A计算它自己这边的预测值以及LA,并把它们加密后发送给B;A计算它自己这边的预测值、L和di,把di加密后发送给A,把L加密后发送给C;
step 3:A和B初始化各自的掩码,把添加掩码后的梯度加密,并发送给C;C加密L以及A和B的梯度,并把它们分别发送给A和B;
step 4:A和B利用解密后的梯度更新各自的参数。
(2)预测过程
step 0:C把要预测的样本的ID发送给A和B;
step 1:A和B利用各自训练好的参数计算各自那一部分的预测值,并都发送给C;C把两者相加,得到最重的预测值。
联邦迁移学习(Federated Transfer Learning)
在联邦迁移学习中,A和B两者持有的数据集的特征空间是不一样的,而且数据ID的交集小,如两个机构,一个是位于中国的银行,另一个是位于美国的电子商务公司,由于地理上的限制,这两个机构的用户有一个比较小的交集,另一方面,由于业务不同,双方的特征空间只有一小部分是重叠的。可以先利用下图中重叠的部分进行纵向联邦学习,再把A方模型上的那些参数迁移给A方的其它数据。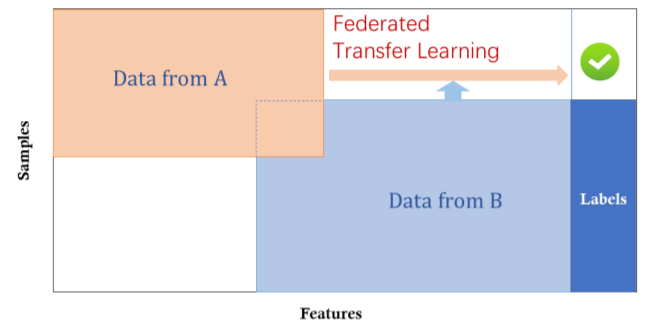
激励机制
为了使不同组织之间的联合学习完全商业化,需要建立一个公平的平台和激励机制。在模型建立之后, 模型的性能将在实际应用中得到体现,这种性能可以记录在永久的数据记录机制区块链中,一个用户上传的数据越多、模型的效果越好,那么激励就越多。

若有收获,就点个赞吧
0 人点赞
