- 分享主题:Transfer Learning, Domain Adaptation, Classification, Explicit Feature Distribution Alignment, Adversarial
- 论文标题:Conditional Adversarial Domain Adaptation
- 论文链接:https://arxiv.org/pdf/1705.10667.pdf
1.Summary
This is a paper on optimizing adversarial domain adaptation methods. The background of the problem is a source domain and a target domain, and both are labeled. The task is classification. Some of the previous adversarial domain adaptation methods are only responsible for aligning features without adding labels. And they apply the same weight (weight in domain discriminator) to all samples. However, some samples that are difficult to predict will affect the model. In order to solve these problems, this paper proposes a model called CDAN. CDAN can align the joint distributions of source domain and target domain, and impose different weights (weights in domain discriminator) on different samples. In order to deepen my understanding of this paper, I can read some papers on adversarial domain adaptation methods.2.你对于论文的思考
这是一篇关于优化域对抗自适应方法的文章,任务是分类,一个源域和一个目标域,并且都带标签,以往的域对抗自适应方法(比如DANN)只会对齐边缘分布,没有考虑标签,并且所有的样本拥有相同的权重(在域判别器中的权重),但是有一些样本是难以预测的,也就是不太适合做迁移的一些样本,这些样本会对模型的效果产生影响,这篇文章提出的CDAN解决了这些问题,在对齐特征时考虑了标签,从而实现了联合分布的对齐,并且给不同的样本赋予了不同的权重(在域判别器中的权重),熵越大的样本所被赋予的权重就越小。3. 其他
3.1 解决的问题
这篇文章解决的问题是以往的域对抗自适应方法的一些不足之处,实现联合概率分布的对齐,并且给不同的样本施加不同的权重(在域判别器中的权重)。3.2 CDAN
如下图所示,CDAN的改进之处是把f和g联合起来进行域对抗。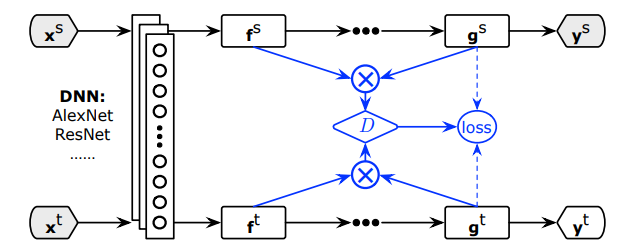
因此,优化目标为: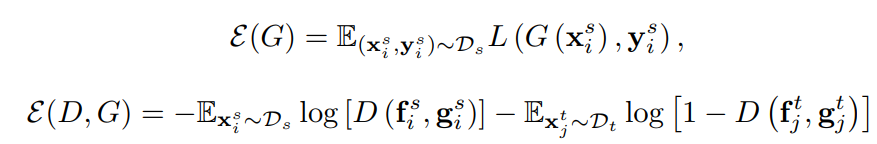
3.2.1 多线性映射
对于f和g的结合方法,相比于直接把f和g连接起来,让f和g做多线性映射的效果会更好,如下面的式子所示(以x和y为例,x代表特征,y代表标签,标签一共有C类),对两者做一次均值映射,可以看出,前者只是分别独立计算了x和y的均值,而后者则是计算了每一个类别(一共C类)的条件分布,因此,多线性映射可以让x和y更好的结合在一起,并且可以捕捉到更多的信息。
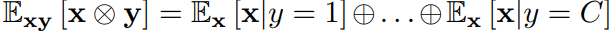
但是,多线性映射有一个缺点,就是计算后的向量维度会很大(计算后的向量维度是两者维度的积),为了解决这个问题,这篇文章使用随机采样的方法:
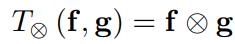
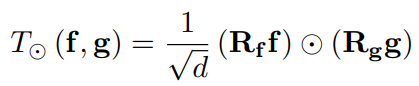
当f和g的维度相乘小于4096时保持原来的方法,但是当大于4096时,就对f和g都随机采样d维(只采样一次,并且在训练过程中保持不变),然后对采样后的两者对应位置相乘(逐元素相乘)。
增加了随机采样后,模型的结构如下图所示: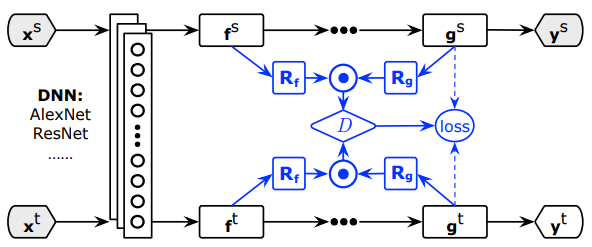
此时损失函数为: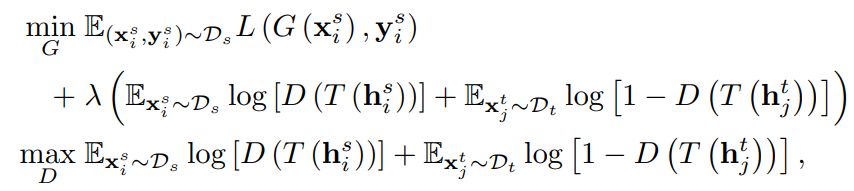
3.2.2 熵调整
为了让难以预测的样本权重变小(在域判别器中的权重),这篇文章利用了标签预测的熵。
下面的式子是一个熵函数,值越大,熵就越大,预测结果就越不稳定。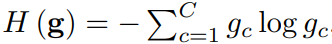
按照上面的熵函数,利用下面的式子来计算样本的权重,熵越大,权重就越小。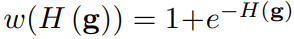
加入熵调整后,损失函数变为: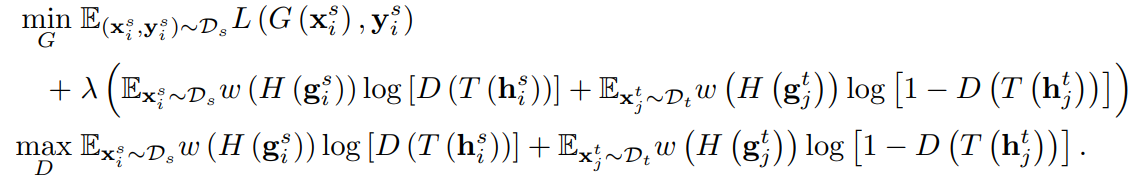
3.3 实验
(1)数据集:Office-31
上面的部分生成器用的是AlexNet,下面的部分生成器用的是ResNet。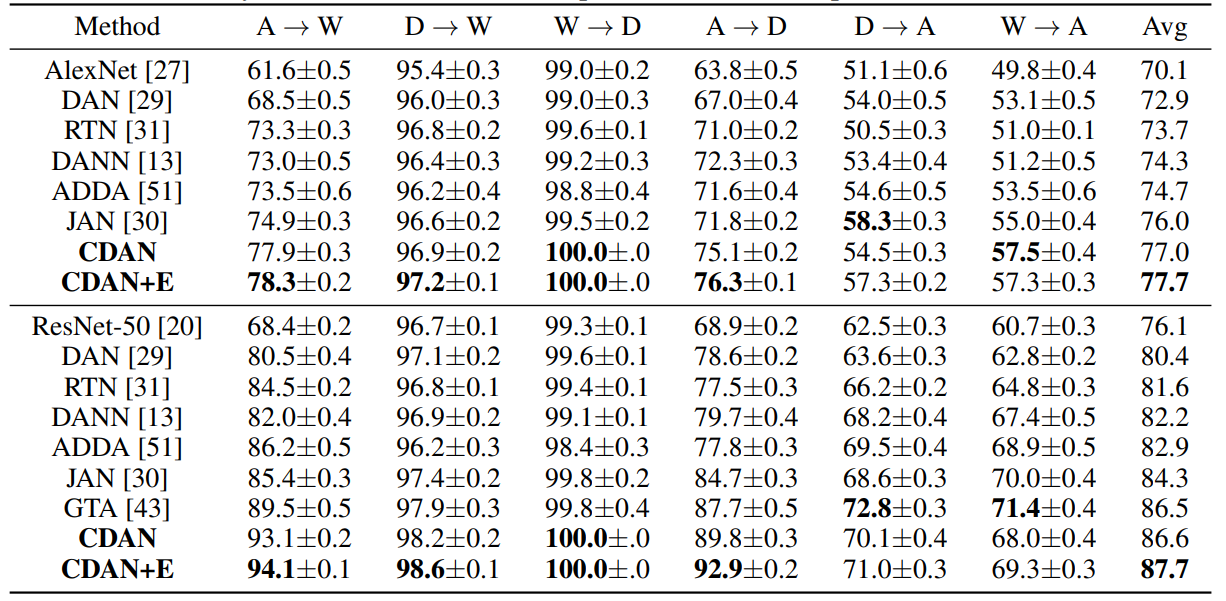
(2)数据集:ImageCLEF-DA
上面的部分生成器用的是AlexNet,下面的部分生成器用的是ResNet。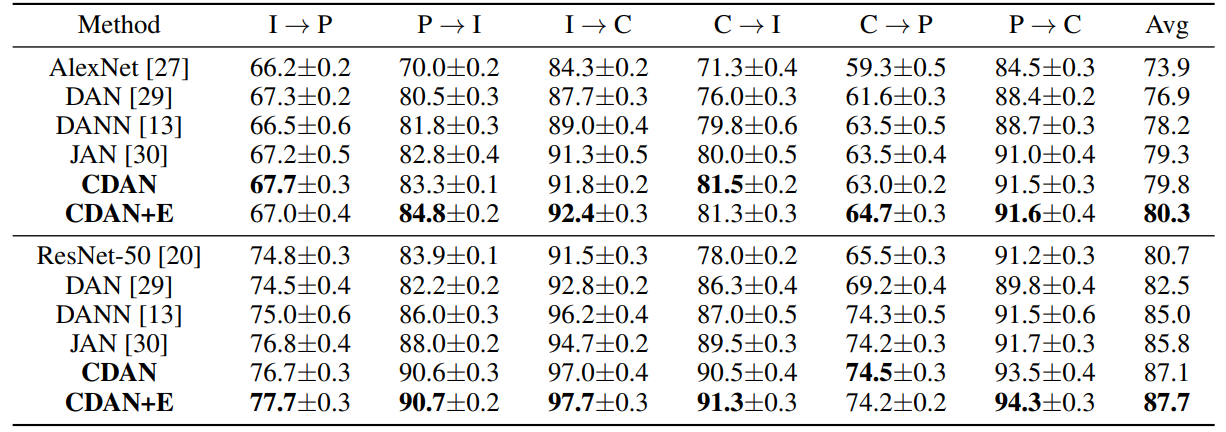
(3)数据集:Office-Home
上面的部分生成器用的是AlexNet,下面的部分生成器用的是ResNet。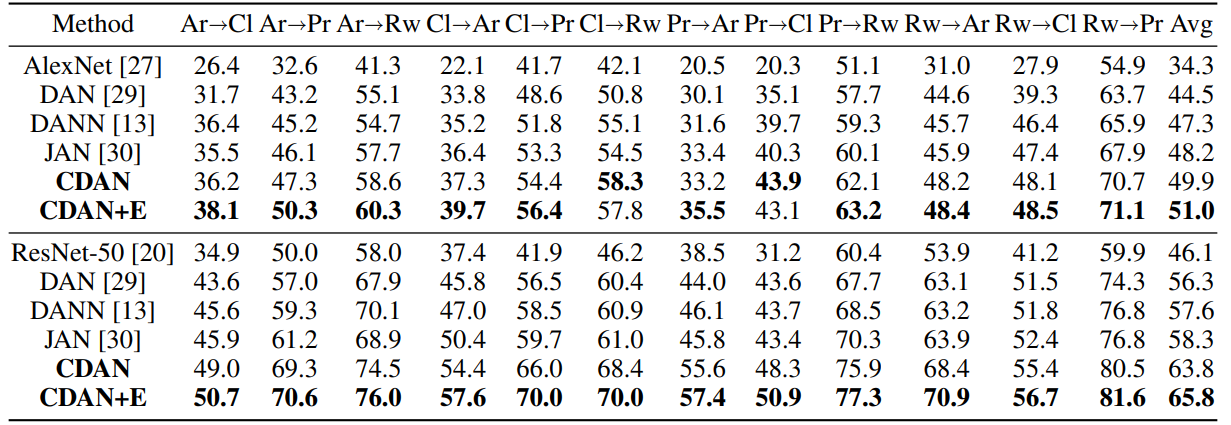
(4)左边用的数据集:Digits;右边用的数据集:VisDA-2017
生成器用的是ResNet。

若有收获,就点个赞吧
0 人点赞
