- 分享主题:Transfer Learning, Unsupervised Domain Adaptation, CV, Explicit Feature Distribution Alignment, Adversarial
- 论文标题:Domain-Symmetric Networks for Adversarial Domain Adaptation
- 论文链接:https://ieeexplore.ieee.org/document/8953920
1.Summary
This is a paper about picture classification. Now there is a source domain and a target domain. The source domain data is labeled and the target domain data is not labeled. This paper uses the adversarial method to realize the transfer of knowledge. Different from the previous methods, the model SymNets proposed in this paper combines label predictor and domain discriminator, which can realize not only domain level confusion, but also category level confusion. Thus, the alignment of the joint distribution of features and labels is realized, which makes up for the disadvantage that the previous methods can only realize the marginal distribution or the poor alignment effect of the joint distribution. In order to deepen my understanding of this paper, I can read some papers that use adversarial method in transfer learning to realize joint distribution alignment.2.你对于论文的思考
这是一篇利用域对抗的方法来解决非监督的域自适应的文章,因为是分类任务(图片分类),所以这篇文章提出的SymNets模型把标签预测器和域判别器结合在了一起,并且以此实现了特征和标签的联合分布对齐,弥补了以往方法的缺点(只能对齐边缘分布或者联合分布的对齐效果不佳)。3. 其他
3.1 解决的问题
这篇文章解决了非监督的域自适应问题,优化了以往的域对抗的迁移学习方法,实现了较好的联合分布对齐效果。3.2 SymNets
整个模型由特征提取器和分类器组成,其中,分类器由2K个神经元(假设图片标签一共有K类),前K个神经元为源域的标签分类器,后K个神经元为目标域的标签分类器,这2K个神经元合起来又是一个域判别器(如果被分类到了前K个神经元,那么就代表属于源域数据,如果被分类到了后K个神经元,那么就代表属于目标域数据),也就是这2K个神经元一共干了三件事。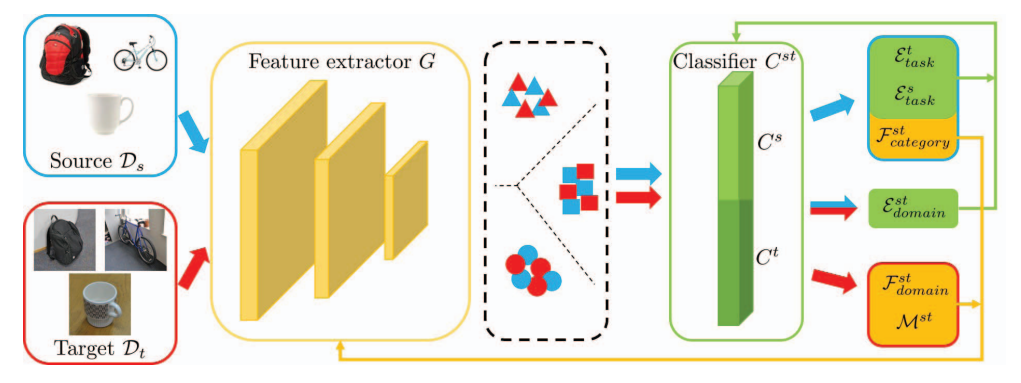
3.2.1 分类器上的损失函数
3.2.1.1 源域分类器标签分类损失
利用源域数据训练分类器的前K个神经元。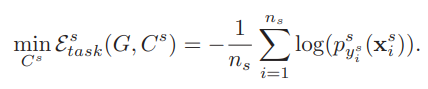
3.2.1.2 目标域分类器标签分类损失
因为目标域上的数据是不带标签的,所以也利用源域的数据进行训练,训练后K个神经元。因为域自适应的目标是使得源域和目标域的标签分类器都能够准确分类源域和目标域上的数据,所以可以利用源域的数据训练目标域的标签分类器。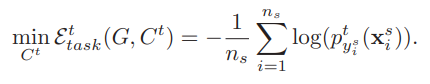
3.2.1.3 域判别器损失
2K个神经元合起来代表一个域判别器,如果被分类到了前K个神经元,那么就代表属于源域数据,如果被分类到了后K个神经元,那么就代表属于目标域数据。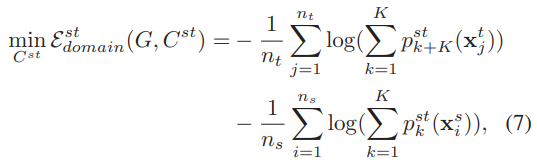
3.2.2 特征提取器上的损失函数
3.2.2.1 类别级别混淆损失
因为只有源域上的数据有标签,所以只利用源域的数据进行训练。下面的式子目标是让源域分类器和目标域分类器在对应的预测类别(正确的类别)上预测的概率都尽可能大。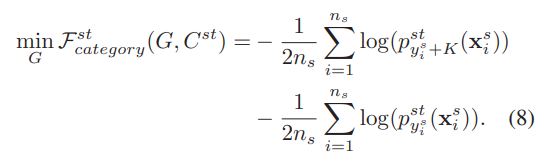
3.2.2.2 域级别混淆损失
只使用目标域的数据进行训练。下面的式子目标是让特征提取器对于目标域的样本在源域和目标域两个分类器上输出的概率是差不多的。因为上面已经用源域的数据进行类别级别混淆,如果在这里再训练一次,可能会造成重复,所以这里只使用了目标域数据。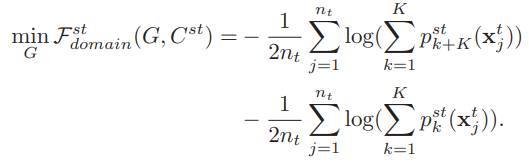
3.2.2.3 熵最小化损失
使用目标域的数据进行训练。下面的式子的作用是使目标域的数据的分类效果更好,即分类器会以较高的概率给出某个确定的分类。这个损失函数没有让它更新分类器,只更新特征提取器,因为在训练的早期阶段,由于域之间较大的差异,目标域的数据可能会被卡在某个错误的类别中很难再纠正过来。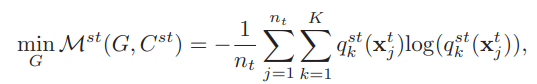
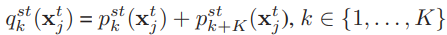
3.3 实验
(1)数据集:Office-31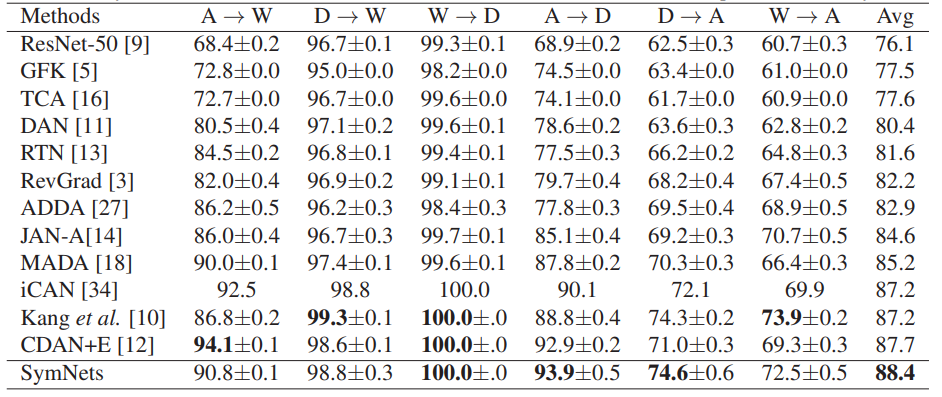
(2)数据集:ImageCLEF-DA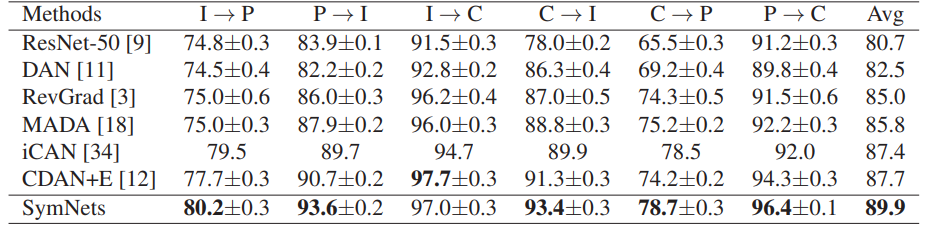
(3)数据集:Office-Home
(4)消融实验(数据集:Office-31)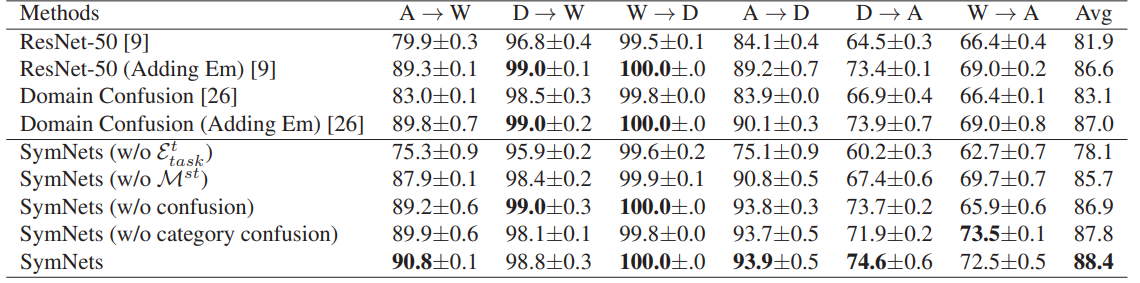
(5)特征可视化(利用了t-SNE降到了二维)
图中蓝色和红色代表不同的域,可以看出,SymNets的对齐效果最好,不仅源域和目标域对齐得很好,而且相同标签的样本也都各自对齐的很好(特征和标签的联合分布对齐得很好)。

若有收获,就点个赞吧
0 人点赞
