- 分享主题:Transfer Learning, Unsupervised Domain Adaptation, Classification, Adversarial
- 论文标题:Gradient Distribution Alignment Certificates Better Adversarial Domain Adaptation
- 论文链接:https://openaccess.thecvf.com/content/ICCV2021/papers/Gao_Gradient_Distribution_Alignment_Certificates_Better_Adversarial_Domain_Adaptation_ICCV_2021_paper.pdf
1.Summary
This is a paper about classification tasks. Now there is a source domain and a target domain. The source domain data is labeled and the target domain data is not labeled. This paper uses the adversarial method to realize the transfer of knowledge. Different from the previous methods, this paper aligns the distribution of hidden layer features by aligning the distribution of hidden layer feature gradients, instead of directly aligning the distribution of hidden layer features. The previous methods can only align the distribution of hidden layer features to a certain extent, because the goal of these methods is to align the distribution of hidden layer features in the source domain and the target domain, but the feature gradient may have a large gap. The method in this paper can go further and directly align the distribution of feature gradients. Through some previous studies, the author found that the gradient direction of hidden layer features may tend to point to its nearest decision boundary, so the closer the feature is, the more similar the feature gradient is. Moreover, because these features are in high-dimensional space, the decision boundary is often highly complex. Therefore, for two different features, their feature gradients may be significantly different. Therefore, aligning the distribution of feature gradients can also reduce the difference of feature distribution and help align the distribution of source domain and the target domain. Moreover, the difference between feature gradients may be more obvious than that between features, because the feature gradients may point to different parts of the highly complex decision boundary if the feature difference is not very large. So the method of this apper may be more effective. To deepen my understanding of this paper, I can read some papers on unsupervised domain adaptation.2.你对于论文的思考
这是一篇关于UDA的论文,解决的是分类任务。以往的方法都是直接对齐隐藏层的特征,而这篇文章的方法是通过对齐隐藏层特征的梯度,进而达到对齐隐藏层特征的目的。之所以这样做,是因为作者总结了以前的一些工作:(1)隐藏层特征的梯度方向可能倾向于指向其最近的决策边界,所以越靠近的特征可能拥有越相似的特征梯度;(2)因为这些特征处于高维空间,所以决策边界往往是高度复杂的,因此对于两个不同的特征,它们的特征梯度可能存在着显著的差异;(3)对于两个差异不是非常大的特征,它们的特征梯度可能指向高度复杂的决策边界的不同部分,所以特征梯度之间的差异可能比特征之间的差异更加明显。前两点表明,对齐特征梯度的分布也可以减少特征分布的差异,可以帮助源域和目标域的对齐,第三点表明,对齐特征梯度的方法可能比对齐特征的方法更有效。3. 其他
3.1 解决的问题
第一张图是未对齐的结果;第二张图是以往方法对齐后的结果(直接对齐特征分布),虽然两个域的特征中心点非常接近,但是任然还有上升空间,并且梯度平均值的方向很不一样;第三张图是这篇文章的方法对齐后的结果(对齐特征梯度分布),比第二张图的效果更好。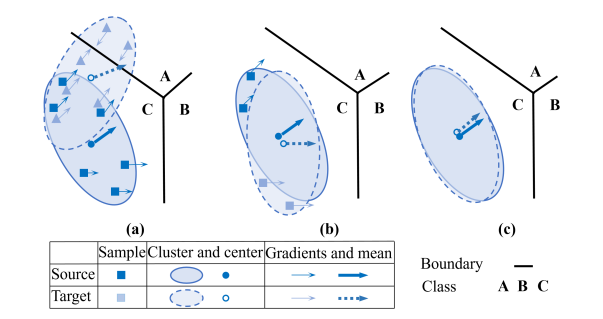
下图是对齐特征梯度分布后的结果。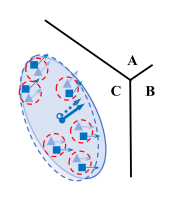
3.2 FGDA
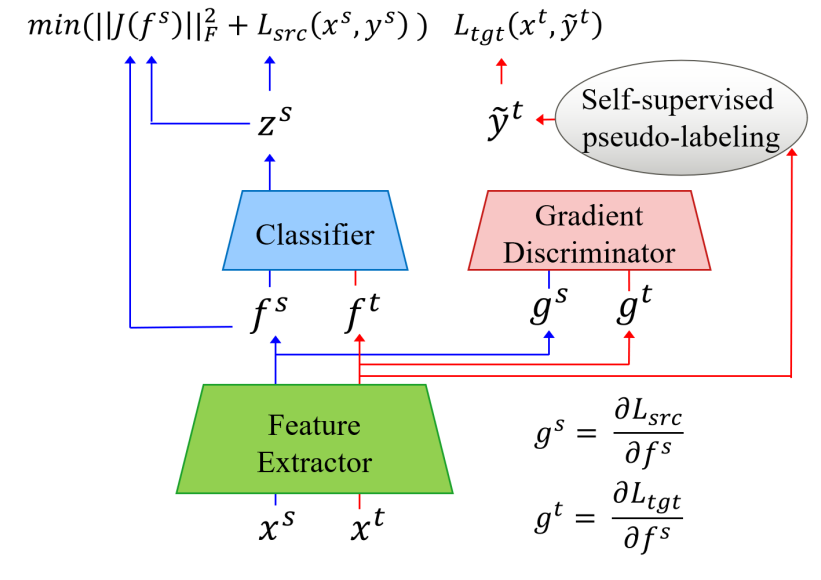
3.2.1 源域标签分类损失
用交叉熵来表示源域的标签分类损失: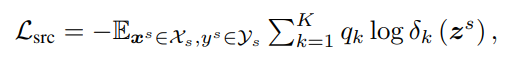
3.2.2 基于特征梯度的域判别损失
与GAN形式类似的二元交叉熵: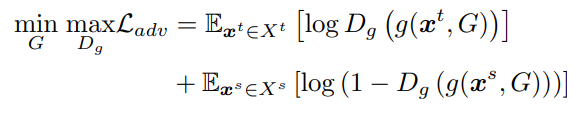
特征梯度: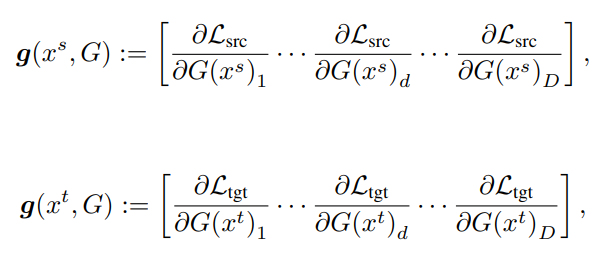
3.2.3 Jacobian正则化
d代表第d个源域样本经过G后的表征,k代表这个样本的标签被C预测为第k类的分数(相当于C的第k个直接输出),然后用这个分数对对应的表征求偏导,全部求出来之后,相当于做一个L2正则化,作为损失函数的一部分。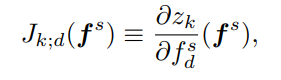
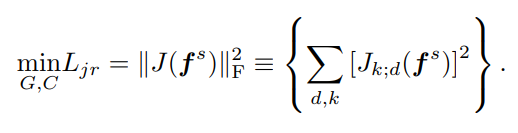
3.2.4 自监督的伪标签
因为3.2.2中是需要目标域的标签的,但是实际情况下是没有的,所以需要计算一个伪标签。
先是计算初始的伪标签,C_hat和G_hat代表上一次迭代的C和G,也就是上一次更新前的C和G,第一个式子是加权求和,求出每一个标签类别的中心,第二个式子是计算各个特征和每一个标签类别中心余弦距离(Mf表示余弦距离),就近加入对应的类别。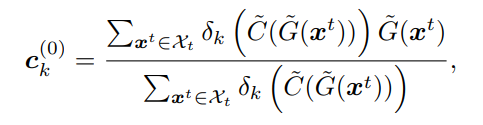
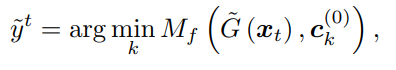
之后就如同k-means进行如下步骤若干轮: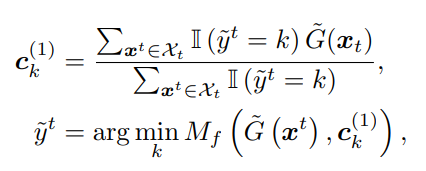
3.2.5 总体损失函数
因为目标域数据用了伪标签,所以把Ladv的符号改成了Ladv_hat。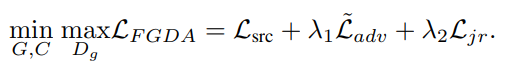
可以把FGDA和一些传统的基于特征的对抗域自适应的方法结合在一起,如DANN、CDNN、MDD,下面式子中的Lfada就是对应方法的对抗部分的损失。
3.3 实验
(1)数据集:Office-31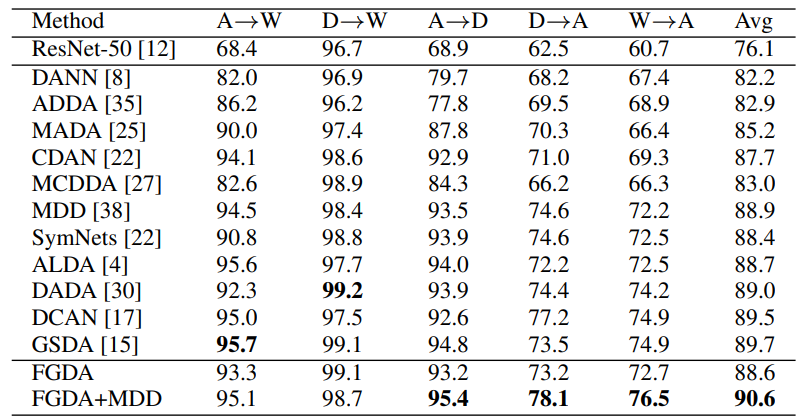
(2)数据集:Office-Home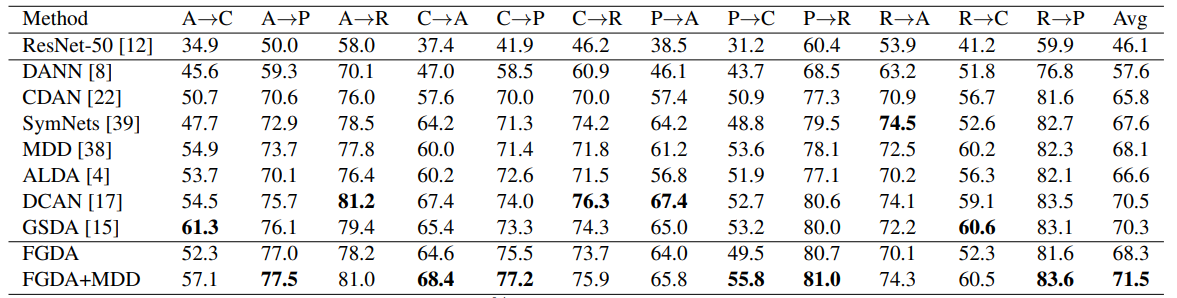
(3)特征可视化(利用了t-SNE降到了二维)
图中蓝色和红色代表不同的域,下面那组效果比较明显,加了FGDA后的效果好很多。

若有收获,就点个赞吧
0 人点赞
