参考:https://blog.csdn.net/qq_26230421/article/details/80366649
集群
# 查看集群是否健康GET _cat/health?v# 查看集群节点GET _cat/nodes?v# 查看有什么索引GET _cat/indices
索引
一个分片就是一个Lucene索引,根据自己情况合理设置,每30G(20亿数据)新增一个分片。 备份数可以提高查询性能,根据节点数合理设置,一般1-3个。
- 创建
PUT /people{"settings": {"number_of_shards": 1, # 分片数"number_of_replicas": 0, # 备份数"index.analysis.analyzer.default.type": "ik_max_word" # 自定义默认分词器,默认:english}}
- 删除
DELETE /people# 也可以删除多个索引DELETE /index_one,index_two
mapping
追加或设置mappingPUT /people/_mapping/doc{"dynamic": "strict","properties": {"name": {"type": "text","analyzer": "ik_max_word", # 索引分词器,如果不加,则text会使用默认分词器,"search_analyzer": "ik-smart" # 搜索分词器,如果不加,默认和索引分词器一致。},"age": {"type": "integer"},"birthday": {"type": "date","format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"}}}# 可以为字段设置keyword(方便精确匹配)PUT /people/_mapping/man{"properties": {"question":{"type": "text","fields": {"keyword":{"type": "keyword"}}}}}# 查看mappingGET /people/_mapping
“dynamic”: “strict” 表示如果遇到陌生field会报错 “dynamic”: “true” 表示如果遇到陌生字段,就进行dynamic mapping
“dynamic”: “false” 表示如果遇到陌生字段,就忽略
别名
# 创建别名PUT /people/_alias/test# 查询索引的别名GET /people/_alias>>>{"people": {"aliases": {"test": {}}}}# 查询别名指向哪一个索引GET /*/_alias/test>>>{"people": {"aliases": {"test": {}}}}
文档
增加
put必须设置id,post则不用
PUT /people/man/1{"name": "叶良辰","country": "china","age": 25,"birthday": "1993-01-01","desc": "叶良辰,本地人,狂妄自大,惹了他,会有一百种方法让你呆不下去!与赵日天是好基友,两个人风风火火闯九州"}》》》{"_index": "people","_type": "man","_id": "1","_version": 1,"result": "created","_shards": {"total": 1,"successful": 1,"failed": 0},"created": true}
POST /people/man{"name": "叶良辰","country": "china","age": 25,"birthday": "1993-01-01","desc": "叶良辰,本地人,狂妄自大,惹了他,会有一百种方法让你待不下去!与赵日天是好基友,两个人风风火火闯九州"}》》》{"_index": "people","_type": "man","_id": "AW7P2HV23ydeaETTj2Cz","_version": 1,"result": "created","_shards": {"total": 1,"successful": 1,"failed": 0},"created": true}
修改
- 全文修改使用的是PUT命令,把所有字段都带上
PUT /people/man/1{"name": "叶良辰","country": "china","age": 26,"birthday": "1993-01-01","desc": "叶良辰,本地人,狂妄自大,惹了他,会有一百种方法让你呆不下去!与赵日天是好基友,两个人风风火火闯九州"}》》》{"_index": "people","_type": "man","_id": "1","_version": 2,"result": "updated","_shards": {"total": 1,"successful": 1,"failed": 0},"created": false}
- 部分修改使用POST
POST /people/man/1/_update{"doc": {"name": "zhangsan"}}》》》{"_index": "people","_type": "man","_id": "1","_version": 3,"result": "updated","_shards": {"total": 1,"successful": 1,"failed": 0}}
- 脚本修改
POST /people/man/1/_update{"script": "ctx._source.age += 10"}
删除
DELETE /people/man/1POST /people/man/_delete_by_query?conflicts=proceed{"query": {"match_all": {}}}
查询
简单查询
match分词查询
方式一(简单查询):GET /people/_search方式二:POST /people/_search{"query": {"match_all": {}}}GET people/man/_search?_source=name,country{"query": {"match": {"age": "25"}}}
排序
POST /people/_search{"query": {"match": {"name": "叶良辰"}},"sort": [{"birthday": {"order": "desc"}}]}
多字段搜索
GET /people/_search{"query": {"multi_match": {"query": "页良","fields": ["name","desc"]}}}
match_phrase:分词,并且要全部包含
完全匹配可能比较严,我们会希望有个可调节因子,少匹配一个也满足,那就需要使用到slop。{"query": {"match_phrase": {"content" : {"query" : "我的宝马多少马力","slop" : 1}}}}
query_string
GET /people/_search{"query": {"query_string": {"default_field": "desc","query": "(叶良辰 AND 风)"}}}“叶良辰 AND 风”会先把“叶良辰”拆分成“叶”、“良”和“辰”,然后后面必须有“风”GET /people/_search{"query": {"query_string": {"query": "(叶良辰 AND 火) OR (赵日天 AND 风)","fields": ["name","desc"]}}}
term
GET /people/_search{"query": {"term": {"name": "叶良辰"}}}
分页
GET people/_search{"query": {"match_all": {}},"from": 0,"size": 1}
范围查询
数字
GET /people/_search{"query": {"range": {"age": {"gte": 10,"lte": 26}}}}
日期
GET /people/_search{"query": {"range": {"birthday": {"gte": "1993-01-01","lte": "now"}}}}
过滤查询
过滤很快,但是没有评分,后面的boost就是默认的分数。
POST /people/man/_search{"query": {"constant_score": {"filter": {"range": {"age": {"gte": 20,"lte": 30}}},"boost": 1.2}}}
也可以使用bool must 过滤
GET /city/_search{"query": {"bool": {"must": [{"match_all": {}}],"filter": {"geo_distance": {"distance": "1000km","location": {"lat": 23.73,"lon": 112.1}}}}}}
布尔查询
shoud 相当于 or
must 相当于and
POST /people/_search{"query": {"bool": {"should": [{"match": {"name": "叶良辰"}},{"match": {"desc": "赵日天"}}]}}}
POST /people/_search{"query": {"bool": {"must": [{"match": {"name": "叶良辰"}},{"match": {"desc": "赵日天"}}]}}}
高亮
GET /people/_search{"query": {"match": {"name": "叶良辰2"}},"highlight": {"fields": {"name": {}}}}
效果:
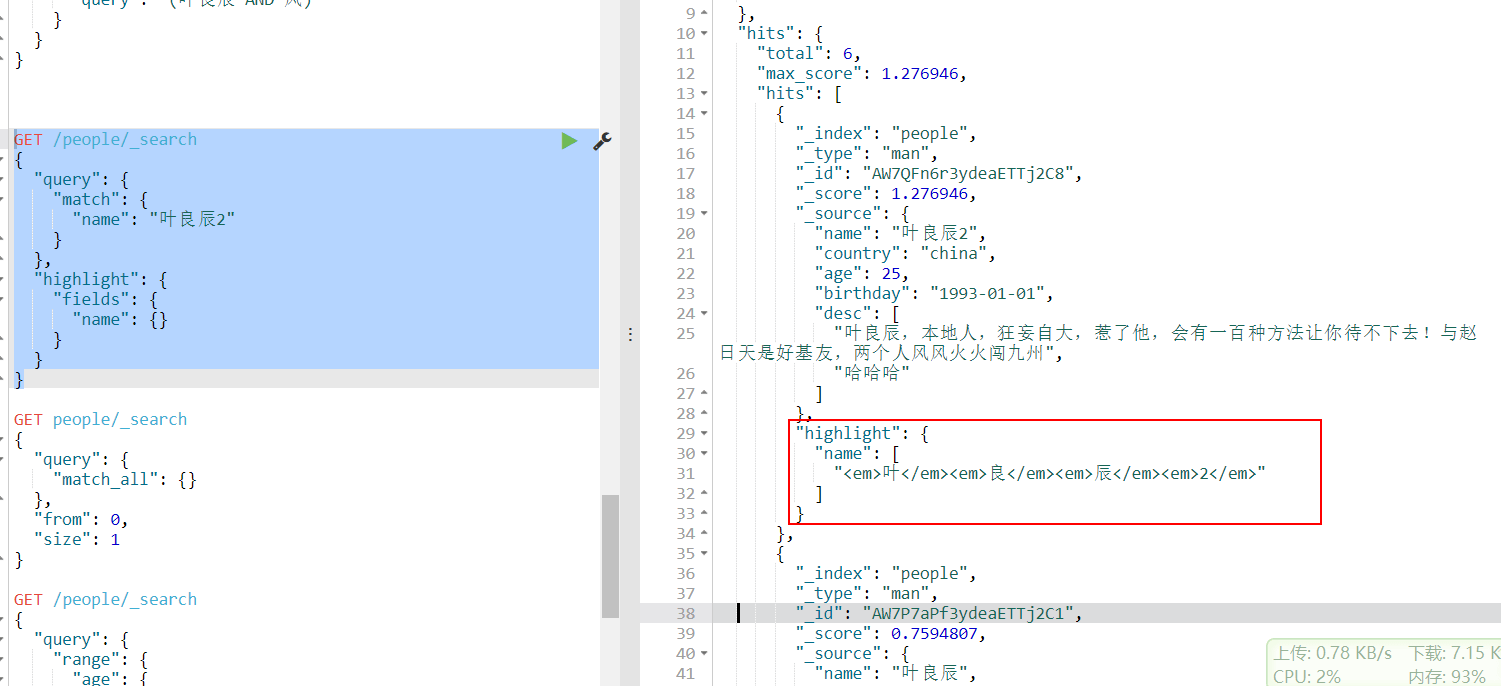
当前,也可以指定标签(虽然感觉没啥用)
GET people/_search{"query": {"match": {"name": "叶良辰"}},"highlight": {"pre_tags": ["<b>"],"post_tags": ["</b>"],"fields": {"name": {}}}}
聚合
根据字段类型查询
GET /people/_search{"query": {"match": {"name": "叶良辰"}},"aggs": {"groupByAge": {"terms": {"field": "age","size": 10}}},"size": 0}>>>{…………………………………………………………………………"aggregations": {"groupByAge": {"doc_count_error_upper_bound": 0,"sum_other_doc_count": 0,"buckets": [{"key": 25,"doc_count": 5},{"key": 26,"doc_count": 1}]}}}
统计:求和、平均值
GET /people/_search{"query": {"match": {"name": "叶良辰"}},"aggs": {"groupByAge": {"stats": { // 可以替换为min等"field": "age"}}},"size": 0}》》》"aggregations": {"groupByAge": {"count": 6,"min": 25,"max": 26,"avg": 25.166666666666668,"sum": 151}}
先分组再计算
GET /people/_search{"aggs": {"groupByAge": {"terms": {"field": "key"},"aggs": {"avg-age": {"avg": {"field": "age"}}}}},"size": 0}》》》"aggregations": {"groupByAge": {"doc_count_error_upper_bound": 0,"sum_other_doc_count": 0,"buckets": [{"key": "叶良辰","doc_count": 1,"avg-age": {"value": 26}}]}}提示:group字段必须没有分词,并且设置fielddata,如下,否则会报错(不一定)POST /people/_mapping/man{"properties": {"name":{"type": "text","fielddata": true}}}
深度排序
实时查询:使用search-after
第一步正常查询,但是排序的时候,多加一个字段_uid:
POST /people/_search{"query": {"match": {"name": "叶良辰"}},"sort": [{"birthday": {"order": "desc"},"_uid":{"order": "desc"}}]}》》》"_index": "people","_type": "man","_id": "AW7P7ag_3ydeaETTj2C3","_score": null,"_source": {"name": "叶良辰","country": "china","age": 25,"birthday": "1993-01-01","desc": "叶良辰,本地人,狂妄自大,惹了他,会有一百种方法让你待不下日天是好基友,两个人风风火火闯九州"},"sort": [725846400000,"man#AW7P7ag_3ydeaETTj2C3"]},
返回的结果里面会sort的值,
第二步查询的时候加上第一次返回的最后的值,然后就OK啦
POST /people/_search{"query": {"match": {"name": "叶良辰"}},"sort": [{"birthday": {"order": "desc"},"_uid":{"order": "desc"}}],"search_after": [725846400000, "man#AW7QFn6r3ydeaETTj2C8"]}
后台任务可以使用scroll
**
相当于获取一个镜像,然后可以随意处理
第一步
POST /people/_search?scroll=1m{"query": {"match": {"name": "叶良辰"}},"sort": "_doc","size": 2}
获得scroll_id
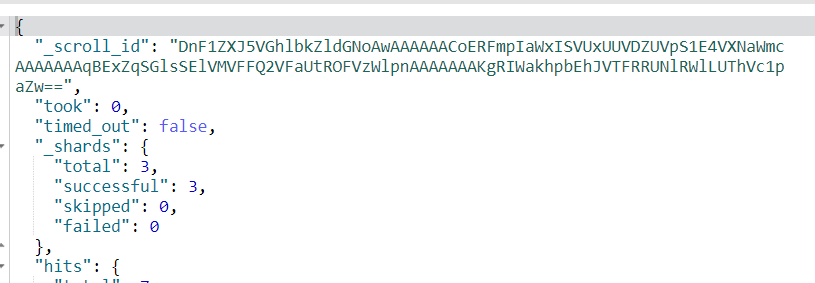
第二步或者第N步(id不会变化)
POST /_search/scroll{"scroll": "1m","scroll_id":"DnF1ZXJ5VGhlbkZldGNoAwAAAAAACoDvFmpIaWxISVUxUUVDZUVpS1E4VXNaWmcAAAAAAAqA7hZqSGlsSElVMVFFQ2VFaUtROFVzWlpnAAAAAAAKgPAWakhpbEhJVTFRRUNlRWlLUThVc1paZw=="}
分词查询
GET _analyze{"analyzer": "ik_smart","text": ["今天天气不错"]}GET _analyze{"analyzer": "standard","text": ["今天天气不错"]}
地理位置查询
设置索引
PUT /city{"settings": {"number_of_shards": 1,"number_of_replicas": 0},"mappings": {"doc":{"properties":{"city":{"type":"text"},"state": {"type": "text"},"location":{"type":"geo_point"}}}}}
插入数据
POST /city/doc{"city": "Guangzhou","state": "GD","location": {"lat": "23.16667","lon": "113.23333"}}
查询
GET /city/_search{"query": {"bool": {"must": [{"match_all": {}}],"filter": {"geo_distance": {"distance": "1000km","location": {"lat": 23.73,"lon": 112.1}}}}}}

若有收获,就点个赞吧
0 人点赞
