目的:
- 梳理垃圾回收器相关概念
- 整理不同垃圾回收器特点
相关概念:
- 并发:垃圾收集器和用户线程同时进行。
- 并行:多条垃圾收集器线程同时工作,用户线程暂停。
- 吞吐量:运行用户代码时间 /(运行用户代码时间 + 垃圾收集时间)。
垃圾回收器算法
- 复制算法
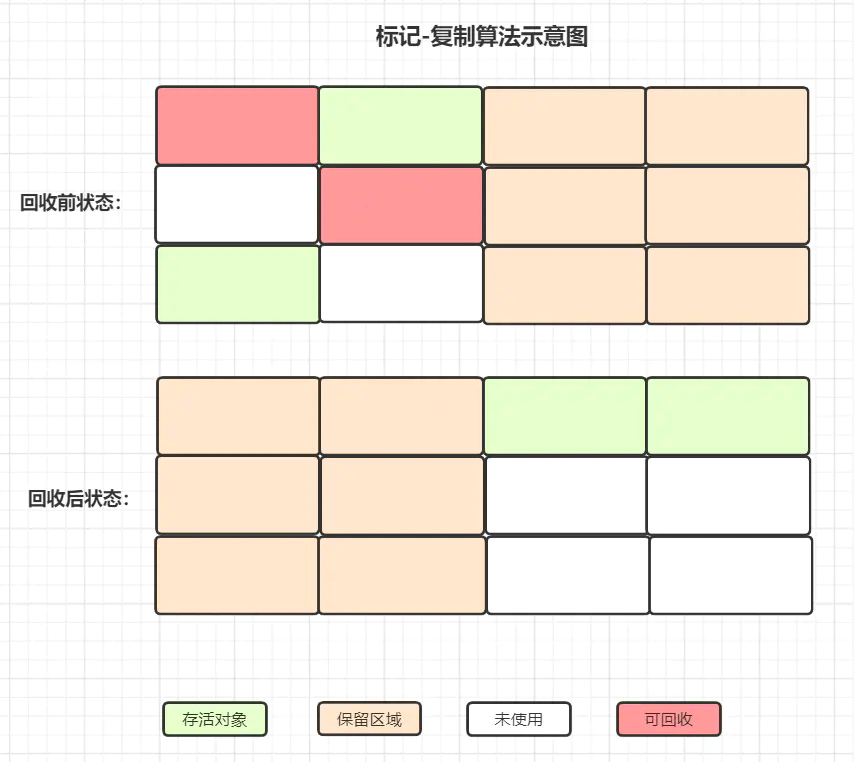
将存活对象移动到空闲区域,适用于新生代,对象存活率低,速度快。
- 标记整理
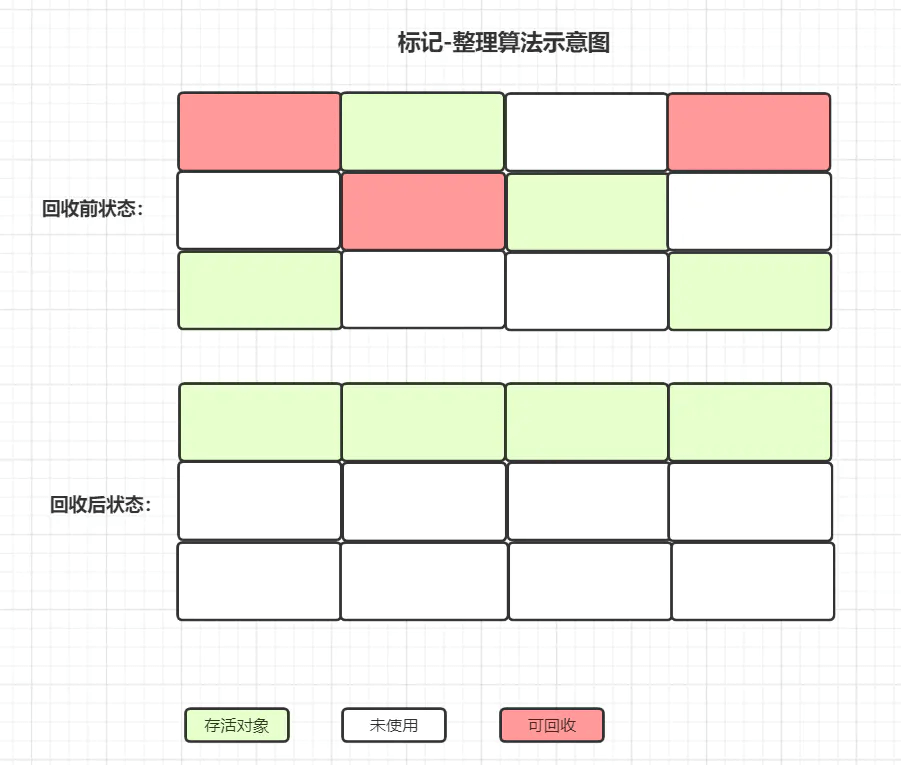
将存活对象移动到一侧,算法复杂但是吞吐量更大,适用于老年代。
- 标记清理
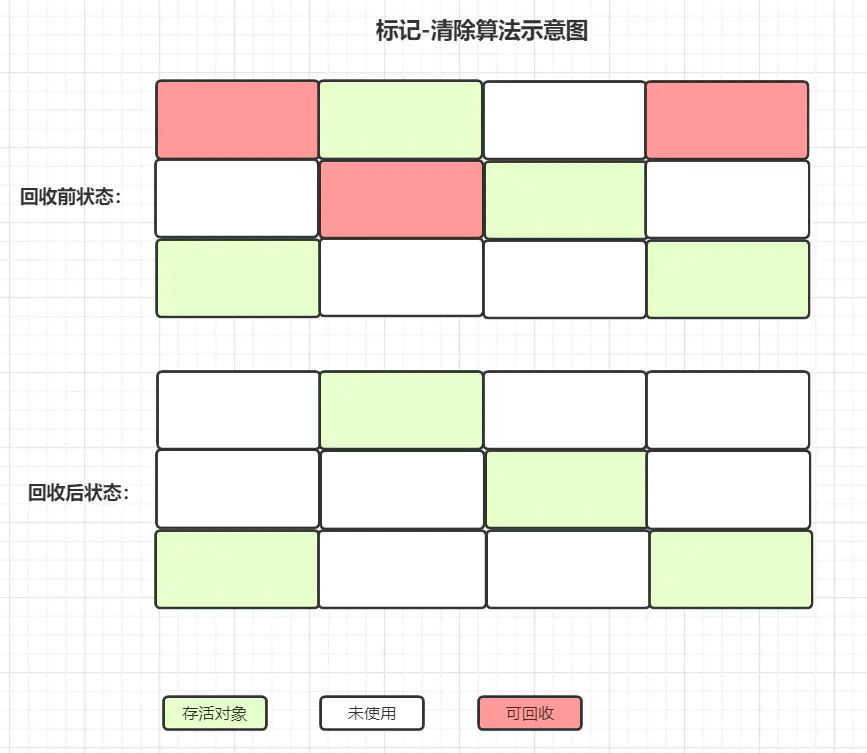
直接回收垃圾对象,速度快,但是有空间碎片化问题,停顿时间端,适用于老年代。
垃圾回收器
新生代收集器
- Serial
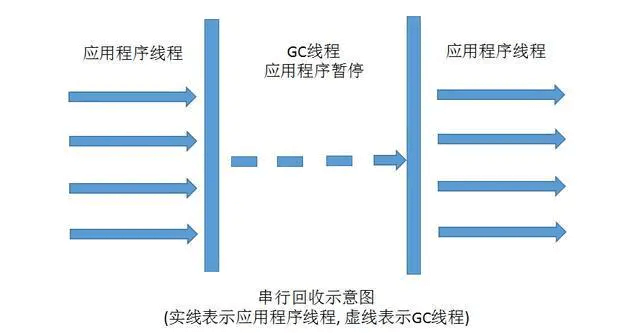
单线程收集器,复制算法。
优点:简单高效,单核效率比较高。
缺点:会在用户不知道的情况下停止所有工作线程,用户体验感差。
场景:单核处理器
- ParNew
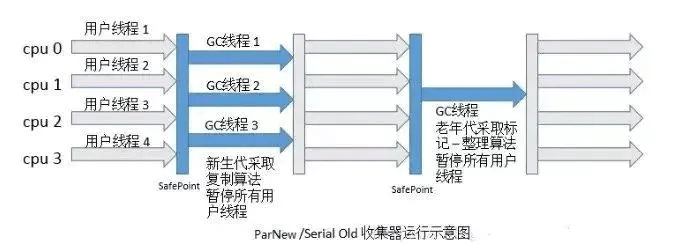
Serial收集器的多线程版本,多核效率高,但是缺点和Serial处理器一样。
场景:多核处理器
- Parallel Scavenge
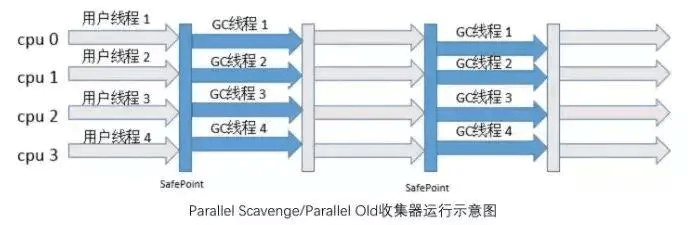
多线程+复制算法,在ParNew的基础上多了一个可控吞吐量的优点。
场景:多核+注重吞吐量
老年代收集器
- Serial Old
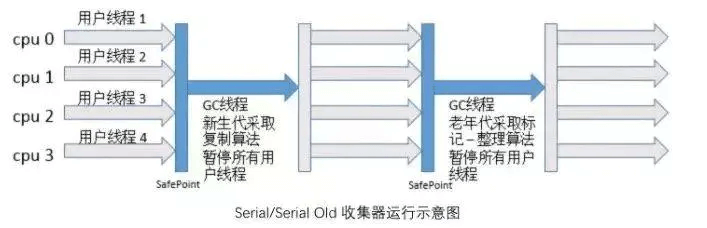
特点和新生代的Serial处理器一直,采用标记整理算法。
- CMS
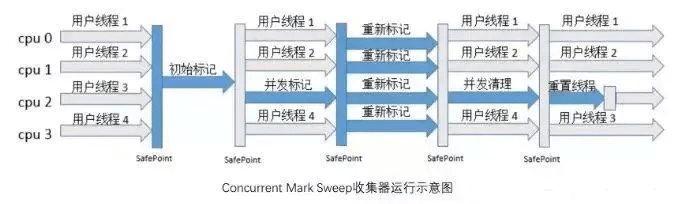
采用标记清理算法,并发收集+低延迟。
- Parallel Old
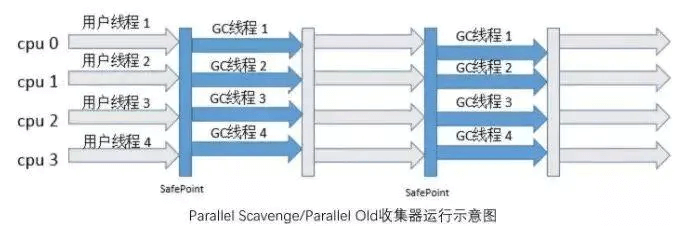
Parallel Scavenge的老年代版本,标记整理算法,注重吞吐量。
新生代和老年代收集器
- G1
首先讨论为什么会有G1收集器?
因为之前的收集器都有两个问题:
1、GC要扫描整个堆内存,分配内存越大时间越长。
2、JVM初始时就要固定新生代和老年代的虚拟内存位置。
内存结构模拟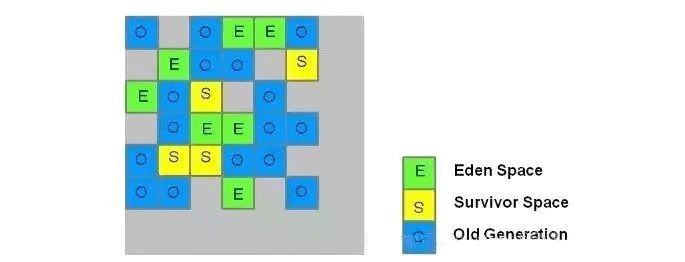
G1收集器将这个Java堆划分为多个大小相等的独立区域(Region),可以有计划地避免在整个Java堆全区域的垃圾收集。
优点:
1、大内存效果更好(8G)。
2、GC时间可控。
3、没有内存碎片。
缺点:
每个区域都要维护对象引用关系来加快扫描,所以相对而言会消耗一部分内存。

若有收获,就点个赞吧
0 人点赞
