因为二分查找底层依赖的是数组随机访问的特性,所以只能用数组来实现。如果数据存储在链表中,就真的没法用二分查找算法了吗?
实际上,我们只需要对链表稍加改造,就可以支持类似“二分”的查找算法。我们把改造之后的数据结构叫作跳表(Skip list)。
原理
对于一个单链表来讲,即便链表中存储的数据是有序的,如果我们要想在其中查找某个数据,也只能从头到尾遍历链表。这样查找效率就会很低,时间复杂度会很高,是 O(n)。
那怎么来提高查找效率呢?如果像下图中那样,对链表建立“索引”,查找起来是不是就会更快一些呢?每两个结点提取一个结点到上一级,我们把抽出来的那一级叫作索引或索引层。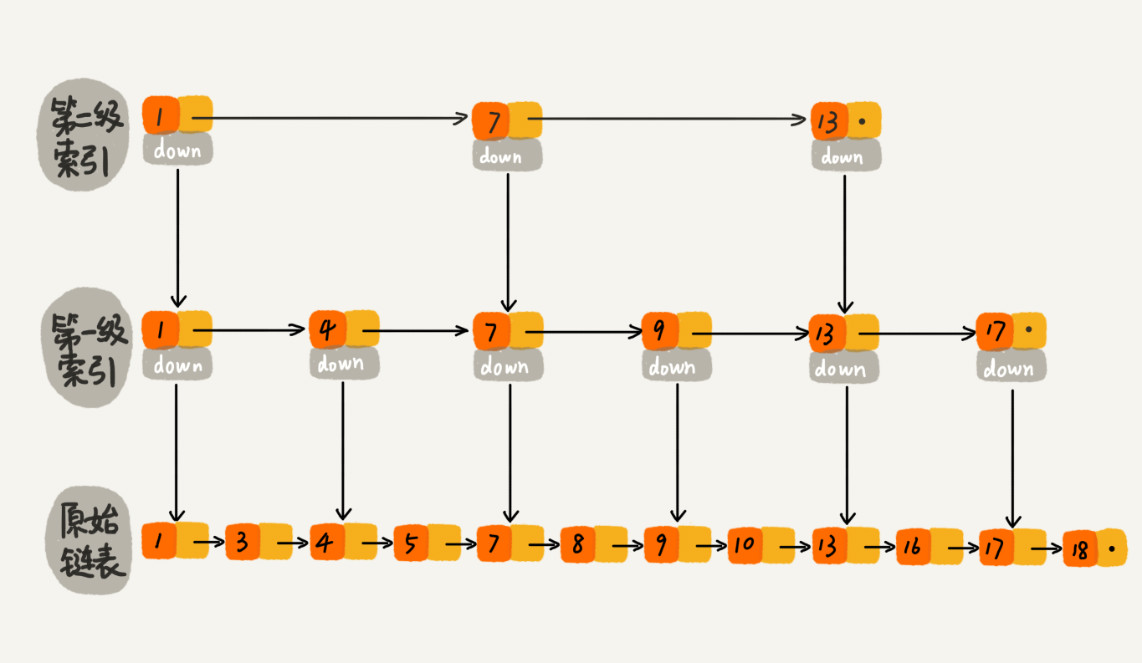
这种链表加多级索引的结构,就是跳表。**
时间复杂度分析
如果每两个结点会抽出一个结点作为上一级索引的结点,那第一级索引的结点个数大约就是 n/2,第二级索引的结点个数大约就是 n/4,第三级索引的结点个数大约就是 n/8,依次类推,也就是说,第 k 级索引的结点个数是第 k-1 级索引的结点个数的 1/2,那第 k级索引结点的个数就是 n/(2k)。
假设索引有 h 级,最高级的索引有 2 个结点。通过上面的公式,我们可以得到 n/(2h)=2,从而求得 。如果包含原始链表这一层,整个跳表的高度就是 。我们在跳表中查询某个数据的时候,如果每一层都要遍历 m 个结点,那在跳表中查询一个数据的时间复杂度就是。
高效的动态插入和删除
跳表长什么样子我想你应该已经很清楚了,它的查找操作上文也介绍过了。实际上,跳表这个动态数据结构,不仅支持查找操作,还支持动态的插入、删除操作,而且插入、删除操作的时间复杂度也是 **O(logn)**。
插入
如何在跳表中插入一个数据,以及它是如何做到 O(logn) 的时间复杂度的?
我们知道,在单链表中,一旦定位好要插入的位置,插入结点的时间复杂度是很低的,就是 O(1)。但是,这里为了保证原始链表中数据的有序性,我们需要先找到要插入的位置,这个查找操作就会比较耗时。
对于纯粹的单链表,需要遍历每个结点,来找到插入的位置。但是,对于跳表来说,我们讲过查找某个结点的的时间复杂度是 O(logn),所以这里查找某个数据应该插入的位置,方法也是类似的,时间复杂度也是 O(logn)。
动态更新索引
当我们不停地往跳表中插入数据时,如果我们不更新索引,就有可能出现某 2 个索引结点之间数据非常多的情况。极端情况下,跳表还会退化成单链表。
作为一种动态数据结构,我们需要某种手段来维护索引与原始链表大小之间的平衡,也就是说,如果链表中结点多了,索引结点就相应地增加一些,避免复杂度退化,以及查找、插入、删除操作性能下降。
如果你了解红黑树、AVL 树这样平衡二叉树,你就知道它们是通过左右旋的方式保持左右子树的大小平衡(如果不了解也没关系,我们后面会讲),而跳表是通过随机函数来维护前面提到的“平衡性”。
当我们往跳表中插入数据的时候,我们可以选择同时将这个数据插入到部分索引层中。如何选择加入哪些索引层呢?
我们通过一个随机函数,来决定将这个结点插入到哪几级索引中,比如随机函数生成了值 K,那我们就将这个结点添加到第一级到第 K 级这 K 级索引中。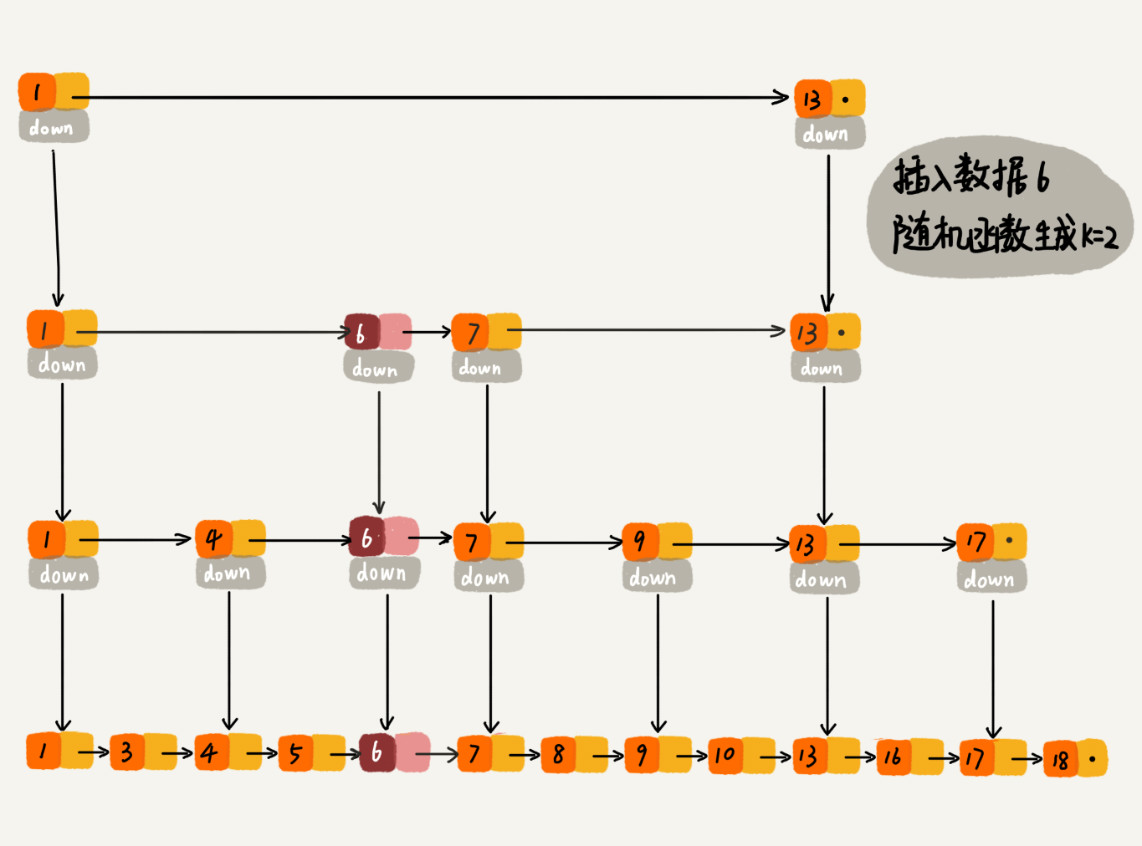
随机函数的选择很有讲究,从概率上来讲,能够保证跳表的索引大小和数据大小平衡性,不至于性能过度退化。对于随机数的选择,可以参考 Redis 中关于有序集合的跳表实现。
删除
如果这个结点在索引中也有出现,我们除了要删除原始链表中的结点,还要删除索引中的。因为单链表中的删除操作需要拿到要删除结点的前驱结点,然后通过指针操作完成删除。所以在查找要删除的结点的时候,一定要获取前驱结点。当然,如果用的是双向链表,就不需要考虑这个问题了。

若有收获,就点个赞吧
0 人点赞
