常见问题
- 优先级队列
- 求 Top K 问题
快速计算 TP99 指标(99分位数,50分位数就是中位数)
堆的定义
堆是一颗完全二叉树,这样实现的堆也被称为二叉堆**;**
堆中节点的值都大于等于(或小于等于)其子节点的值,堆中如果节点的值都大于等于其子节点的值,我们把它称为大顶堆,如果都小于等于其子节点的值,我们将其称为小顶堆。
完全二叉树:它的叶子节点都在最后一层,并且这些叶子节点都是靠左排序的。
完全二叉树底层通常用一个数组来表示;如下图所示: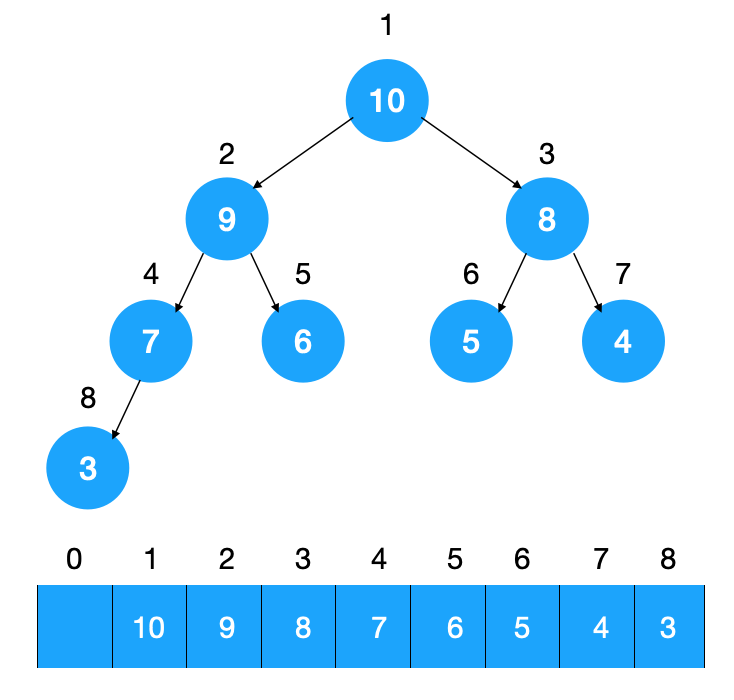 **
**
给完全二叉树按从上到下从左到右编号,则对于任意一个节点来说,很容易得知如果它在数组中的位置为 i,则它的左右子节点在数组中的位置为 2i,2i + 1,通过这种方式可以定位到树中的每一个节点,从而串起整颗树。
基本操作
插入元素
往堆中插入元素后(如下图示),我们需要继续满足堆的特性,所以需要不断调整元素的位置直到满足堆的特点为止(堆中节点的值都大于等于(或小于等于)其子节点的值),我们把这种调整元素以让其满足堆特点的过程称为堆化(heapify)。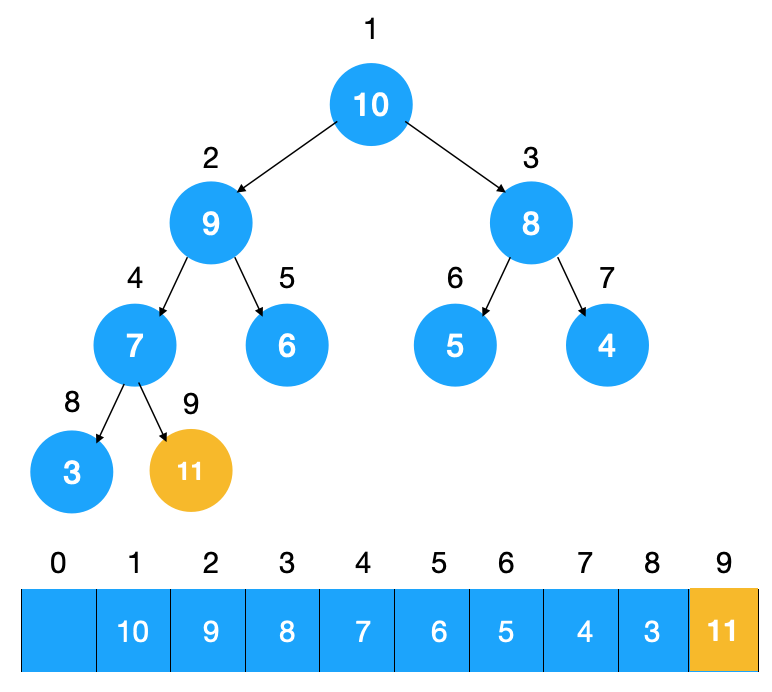
由于上图中的堆是个大顶堆,所以我们需要调整节点以让其符合大顶堆的特点。怎么调整?不断比较子节点与父节点,如果子节点大于父节点,则交换,不断重复此过程,直到子节点小于其父节点。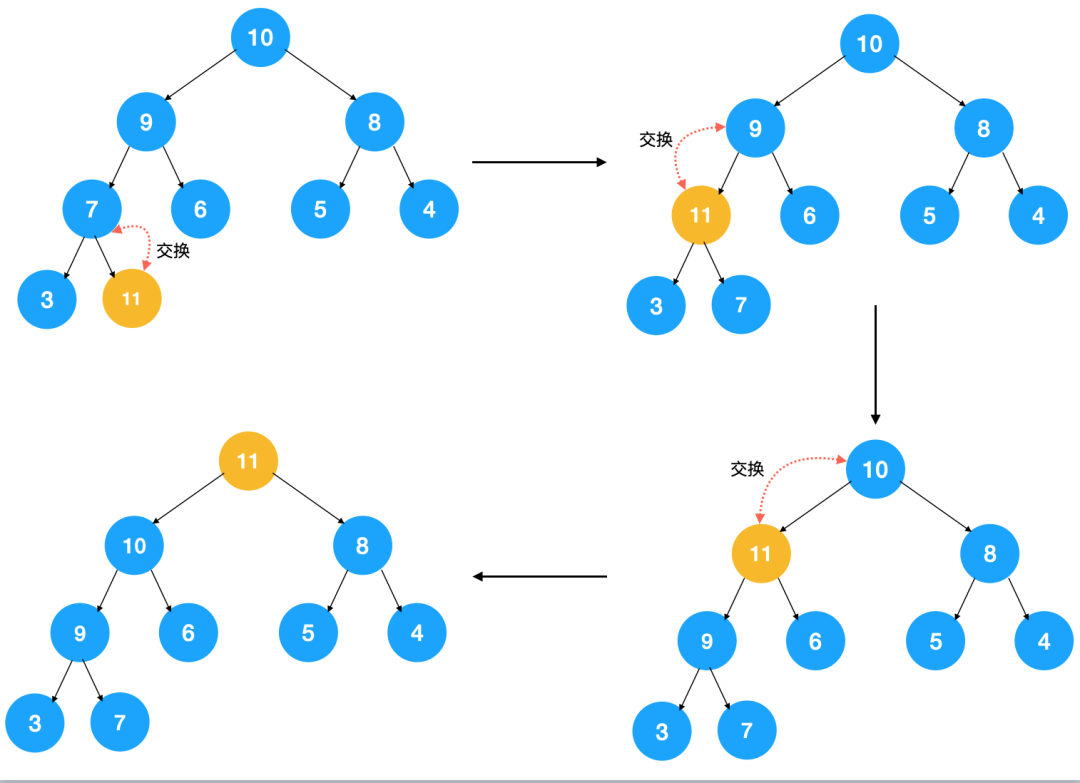
删除堆顶元素
当删除堆顶元素后,也需要调整子节点,以让其满足堆(大顶堆或小顶堆)的条件。
假设我们要操作的堆是大顶堆,则删除堆顶元素后,要找到原堆中第二大的元素以填补堆顶元素,而第二大的元素无疑是在根节点的左右子节点上,假设是左节点,则用左节点填补堆顶元素之后,左节点空了,此时需要从左节点的左右节点中找到两者的较大值填补左节点…,不断迭代此过程,直到调整完毕,调整过程如下图示: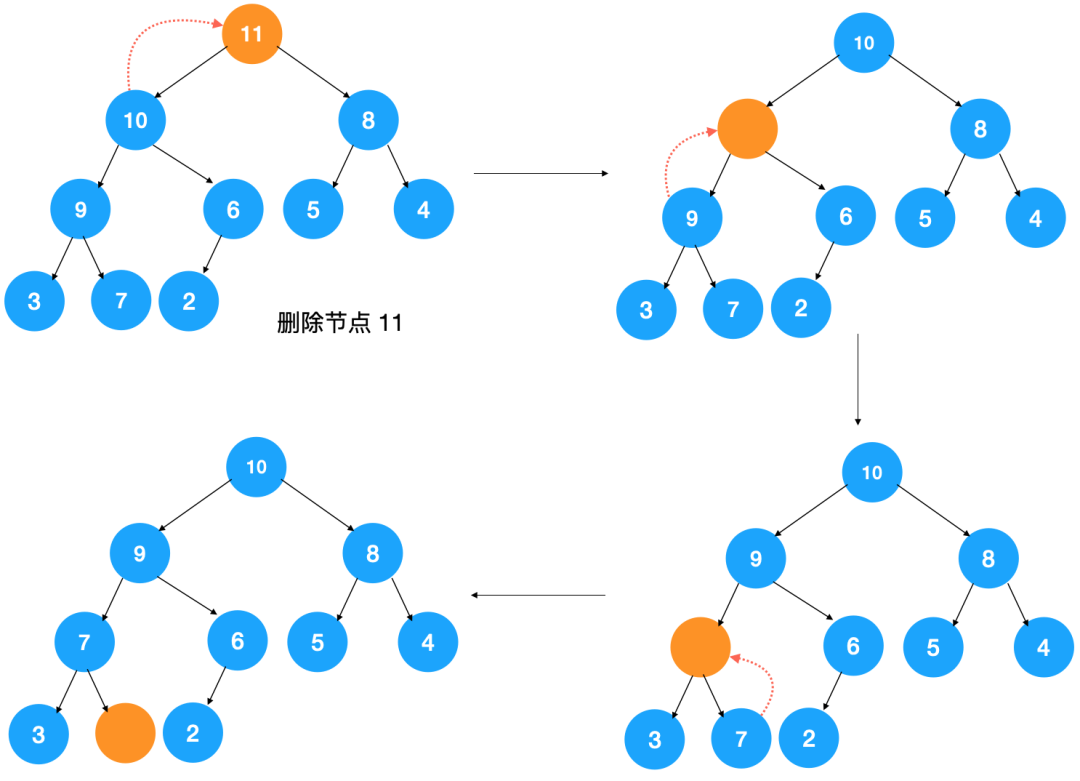
这时候会出现一个问题,那就是调整后可能就不再是完全二叉树了,要怎么避免这个问题呢?可以用最后一个元素覆盖堆顶元素,然后在进行调整操作。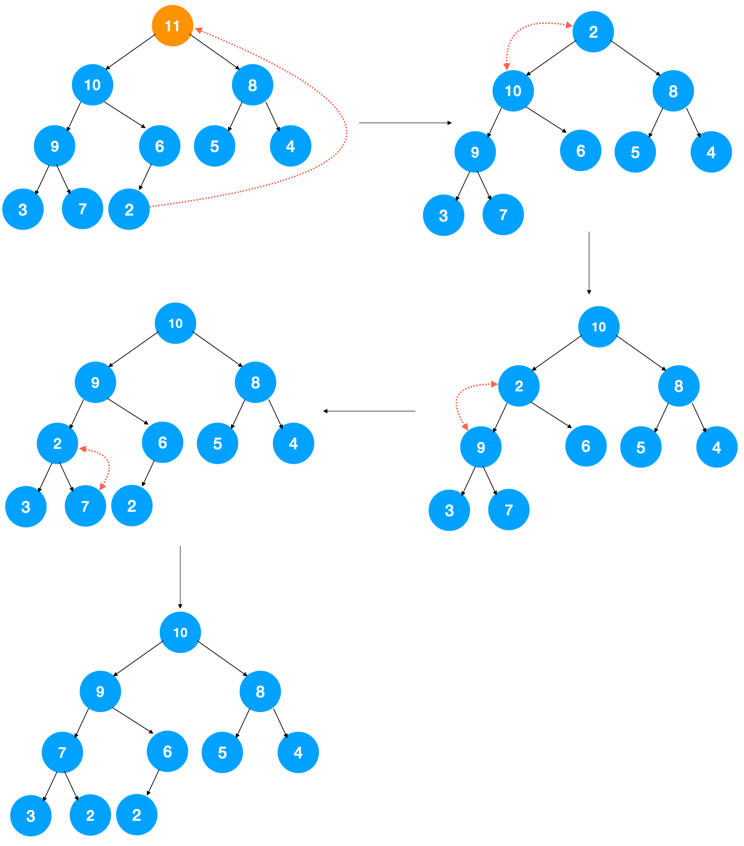
将一个数组堆化(heapify)
方法一:堆中插入一个元素的思路。尽管数组中包含 n 个数据,但是我们可以假设,起初堆中只包含一个数据,就是下标为 1 的数据。然后,我们调用前面讲的插入操作,将下标从 2 到 n 的数据依次插入到堆中。这样我们就将包含 n 个数据的数组,组织成了堆。
方法二:对于所有非叶子节点,自下而上不断调整使其满足大顶堆的条即可(递归)。
因为叶子节点往下堆化只能自己跟自己比较,所以我们直接从第一个非叶子节点开始,依次堆化就行了。
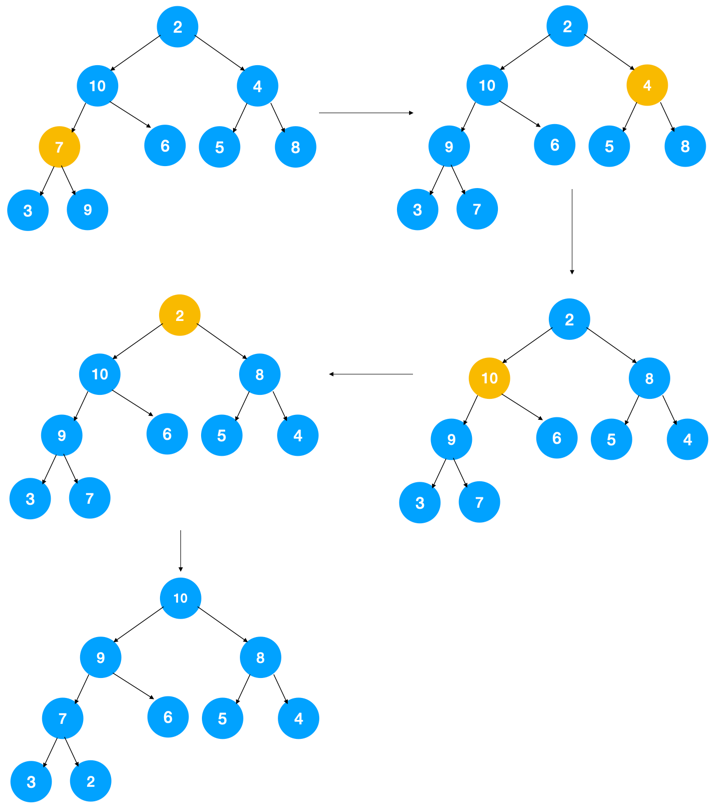
对于完全二叉树来说,下标从 n/2 + 1 到 n 的节点都是叶子节点(此处假设堆在数组中是从索引为1的位置开始存储的)。
堆排序 vs 快排
堆排序的时间复杂度为 ,和快排时间复杂度一样,那么为什么生产中更多的使用快排而不是堆排序呢?
,和快排时间复杂度一样,那么为什么生产中更多的使用快排而不是堆排序呢?
- 快排在递归排序的过程中,都是拿 pivot 与相邻的元素比较,会用到计算机中一个非常重要的定理:局部性原理,啥叫局部性原理,可以简单理解为当 CPU 读取到某个数据的时候,它认为这个数据附近相邻的数据也有很大的概率会被用到,所以干脆把被读取到数据的附近的数据也一起加载到 Cache 中,这样下次还需要再读取数据进行操作时,就直接从 Cache 里拿数据即可(无需再从内存里拿了),数据量大的话,极大地提升了性能;
- 堆排序的一个重要步骤是把堆顶元素移除,重新进行堆化,每次堆化都会导致大量的元素比较,这也是堆排序性能较差的一个原因;
- 堆排序不是稳定排序。
应用
优先级队列
如何实现一个优先级队列呢?方法有很多,但是用堆来实现是最直接、最高效的。这是因为,堆和优先级队列非常相似。一个堆就可以看作一个优先级队列。很多时候,它们只是概念上的区分而已。往优先级队列中插入一个元素,就相当于往堆中插入一个元素;从优先级队列中取出优先级最高的元素,就相当于取出堆顶元素。
合并有序小文件
假设我们有 100 个小文件,每个文件的大小是 100MB,每个文件中存储的都是有序的字符串。我们希望将这些 100 个小文件合并成一个有序的大文件。
思路:从这 100 个文件中,各取第一个字符串,放入堆中,取出最小的那个字符串放入合并后的大文件中,并从堆中删除,然后从最小字符所在文件继续获取下一个字符。
高性能定时器
假设我们有一个定时器,定时器中维护了很多定时任务,每个任务都设定了一个要触发执行的时间点。定时器每过一个很小的单位时间(比如 1 秒),就扫描一遍任务,看是否有任务到达设定的执行时间。如果到达了,就拿出来执行。
但是,这样每过 1 秒就扫描一遍任务列表的做法比较低效,主要原因有两点:第一,任务的约定执行时间离当前时间可能还有很久,这样前面很多次扫描其实都是徒劳的;第二,每次都要扫描整个任务列表,如果任务列表很大的话,势必会比较耗时。
针对这些问题,我们就可以用优先级队列来解决。我们按照任务设定的执行时间,将这些任务存储在优先级队列中,队列首部(也就是小顶堆的堆顶)存储的是最先执行的任务。
这样,定时器就不需要每隔 1 秒就扫描一遍任务列表了。它拿队首任务的执行时间点,与当前时间点相减,得到一个时间间隔 T。
这个时间间隔 T 就是,从当前时间开始,需要等待多久,才会有第一个任务需要被执行。这样,定时器就可以设定在 T 秒之后,再来执行任务。从当前时间点到(T-1)秒这段时间里,定时器都不需要做任何事情。
topK 问题
假设我们要求前 K 个最大的元素,我们可以按如下步骤来做
- 取 n 个元素的前 K 个元素构建一个小顶堆
- 遍历第 K + 1 到 n 之间的元素,每一个元素都与小顶堆的堆顶元素进行比较,如果小于堆顶元素,不做任何操作,如果大于堆顶元素,则将堆顶元素替换成当前遍历的元素,再堆化以让其满足小顶的要求,这样遍历完成后此小顶堆的所有元素就是我们要求的 TopK。
每个元素堆化的时间复杂度是
,n 个元素时间复杂度是
。
TP99问题(99分位数)
先来解释下什么是 TP99,它指的是在一个时间段内(如5分钟),统计某个接口(或方法)每次调用所消耗的时间,并将这些时间按从小到大的顺序进行排序,取第99%的那个值作为 TP99 值。
思路如下:
- 创建一个大顶堆和一个小顶堆,大顶堆的堆顶元素比小顶堆的堆顶元素更小,大顶堆维护 99% 的请求时间,小顶堆维护 1% 的请求时间;
- 每产生一个元素(请求时间),如果它比大顶堆的堆顶元素小,则将其放入到大顶堆中,如果它比小顶堆的堆顶元素大,则将其插入到小顶堆中(插入过程可能会导致大顶堆和小顶堆中元素的比例不为 99:1,此时就要做相应的调整);
- 大顶堆的堆顶元素值就是所要求的 TP99 值。
参考链接
https://mp.weixin.qq.com/s/AsLVyq6ih-t2tI1qOclzYQ
https://docs.python.org/zh-cn/3/library/heapq.html
https://time.geekbang.org/column/article/69913
https://time.geekbang.org/column/article/70187

若有收获,就点个赞吧
0 人点赞
