对同一个排序算法,待排序数据的有序度不一样,排序的执行时间就会有很大的差别。极端情况下,如果数据已经是有序的,那排序算法不需要做任何操作,执行时间就会非常短。除此之外,如果测试数据规模太小,测试结果可能无法真实地反应算法的性能。比如,对于小规模的数据排序,插入排序可能反倒会比快速排序要快!
如何分析一个“排序算法”?
执行效率
- 最好情况/最坏情况/平均情况时间复杂度
我们在分析排序算法的时间复杂度时,要分别给出最好情况、最坏情况、平均情况下的时间复杂度。除此之外,你还要说出最好、最坏时间复杂度对应的要排序的原始数据是什么样的。
为什么要区分这三种时间复杂度呢?第一,有些排序算法会区分,为了好对比,所以我们最好都做一下区分。第二,对于要排序的数据,有的接近有序,有的完全无序。有序度不同的数据,对于排序的执行时间肯定是有影响的,我们要知道排序算法在不同数据下的性能表现。
- 时间复杂度的系数/常数/低阶
我们知道,时间复杂度反应的是数据规模 n 很大的时候的一个增长趋势,所以它表示的时候会忽略系数、常数、低阶。但是实际的软件开发中,我们排序的可能是 10 个、100 个、1000 个这样规模很小的数据,所以,在对同一阶时间复杂度的排序算法性能对比的时候,我们就要把系数、常数、低阶也考虑进来。
- 比较次数和交换/移动次数
基于比较的排序算法的执行过程,会涉及两种操作,一种是元素比较大小,另一种是元素交换或移动。所以,如果我们在分析排序算法的执行效率的时候,应该把比较次数和交换(或移动)次数也考虑进去。
内存消耗
稳定性
如果待排序的序列中存在值相等的元素,经过排序之后,相等元素之间原有的先后顺序不变。我们就说这个排序算法是稳定的排序算法
n^2的排序算法
下述三种算法只有插入排序会在生产环境中实际使用了,其他也就只能停留在理论层面了
冒泡排序
冒泡排序只会操作相邻的两个数据。每次冒泡操作都会对相邻的两个元素进行比较,看是否满足大小关系要求。如果不满足就让它俩互换。一次冒泡会让至少一个元素移动到它应该在的位置,重复 n 次,就完成了 n 个数据的排序工作。
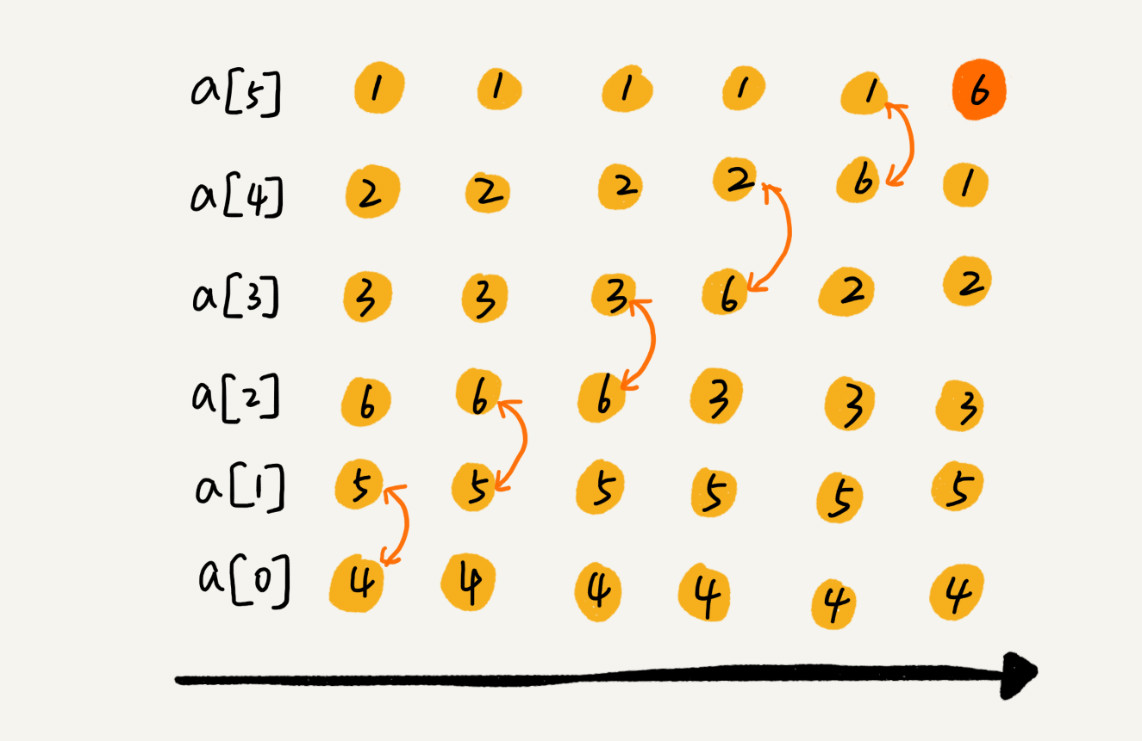
当某次冒泡操作已经没有数据交换时,说明已经达到完全有序,不用再继续执行后续的冒泡操作。
插入排序
我们先来看一个问题。一个有序的数组,我们往里面添加一个新的数据后,如何继续保持数据有序呢?很简单,我们只要遍历数组,找到数据应该插入的位置将其插入即可。
那插入排序具体是如何借助上面的思想来实现排序的呢?首先,我们将数组中的数据分为两个区间,已排序区间和未排序区间。初始已排序区间只有一个元素,就是数组的第一个元素。
插入算法的核心思想是取未排序区间中的元素,在已排序区间中找到合适的插入位置将其插入,并保证已排序区间数据一直有序。重复这个过程,直到未排序区间中元素为空,算法结束。

希尔排序
希尔排序是对插入排序的一个优化,减少了插入排序的移动次数。
原理:
希尔排序是将待排序的数组元素 按下标的一定增量分组 ,分成多个子序列,然后对各个子序列进行直接插入排序算法排序;然后依次缩减增量再进行排序,直到增量为1时,进行最后一次直接插入排序,排序结束。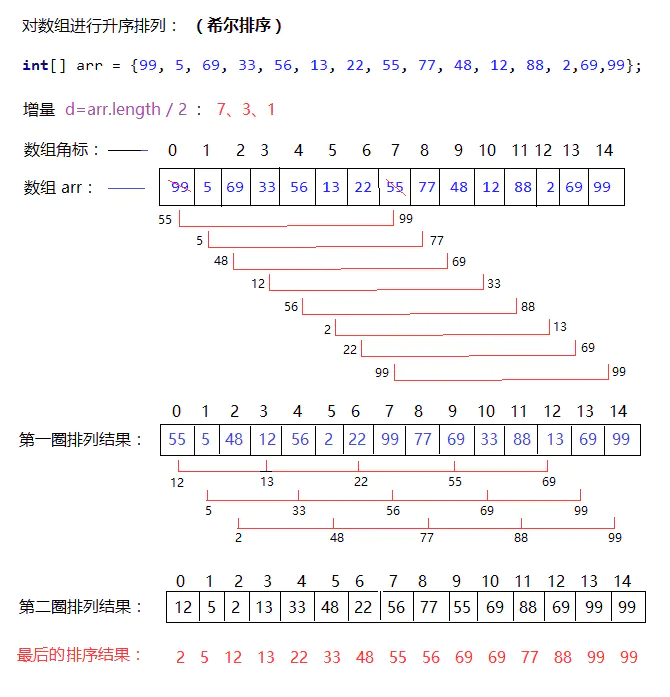
选择排序
选择排序算法的实现思路有点类似插入排序,也分已排序区间和未排序区间。但是选择排序每次会从未排序区间中找到最小的元素,将其放到已排序区间的末尾。

假设要排序数组中下标从 p 到 r 之间的一组数据
- 选择 p 到 r 之间的任意一个数据作为 pivot(分区点);
- 遍历 p 到 r 之间的数据,将小于 pivot 的放到左边,将大于 pivot 的放到右边,将 pivot 放到中间;
- 根据分治、递归的处理思想,我们可以用递归排序下标从 p 到 q-1 之间的数据和下标从 q+1 到 r 之间的数据,直到区间缩小为 1,就说明所有的数据都有序了。
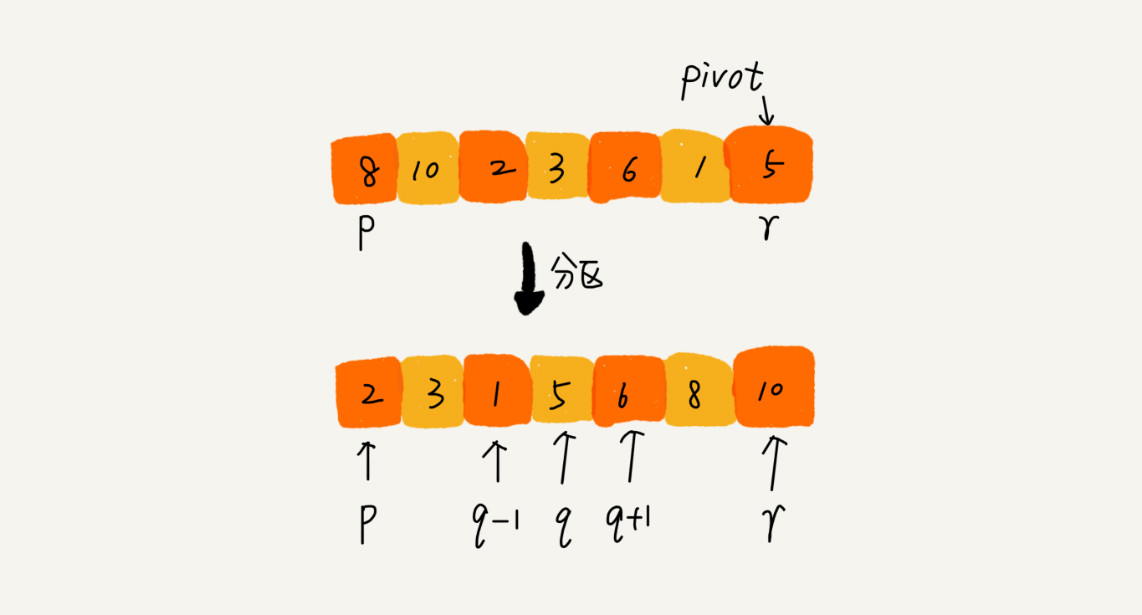
- 快排是一种原地、不稳定的排序算法。
如何优化快速排序?
为什么最坏情况下快速排序的时间复杂度是 O(n^2) 呢?我们前面讲过,如果数据原来就是有序的或者接近有序的,每次分区点都选择最后一个数据,那快速排序算法就会变得非常糟糕,时间复杂度就会退化为 O(n^2)。实际上,这种 O(n^2) 时间复杂度出现的主要原因还是因为我们分区点选的不够合理。
那什么样的分区点是好的分区点呢?或者说如何来选择分区点呢?最理想的分区点是:被分区点分开的两个分区中,数据的数量差不多。
两个比较常用、比较简单的分区算法:
- 三数取中法
- 从区间的首、尾、中间,分别取出一个数,然后对比大小,取这 3 个数的中间值作为分区点。
- 随机法
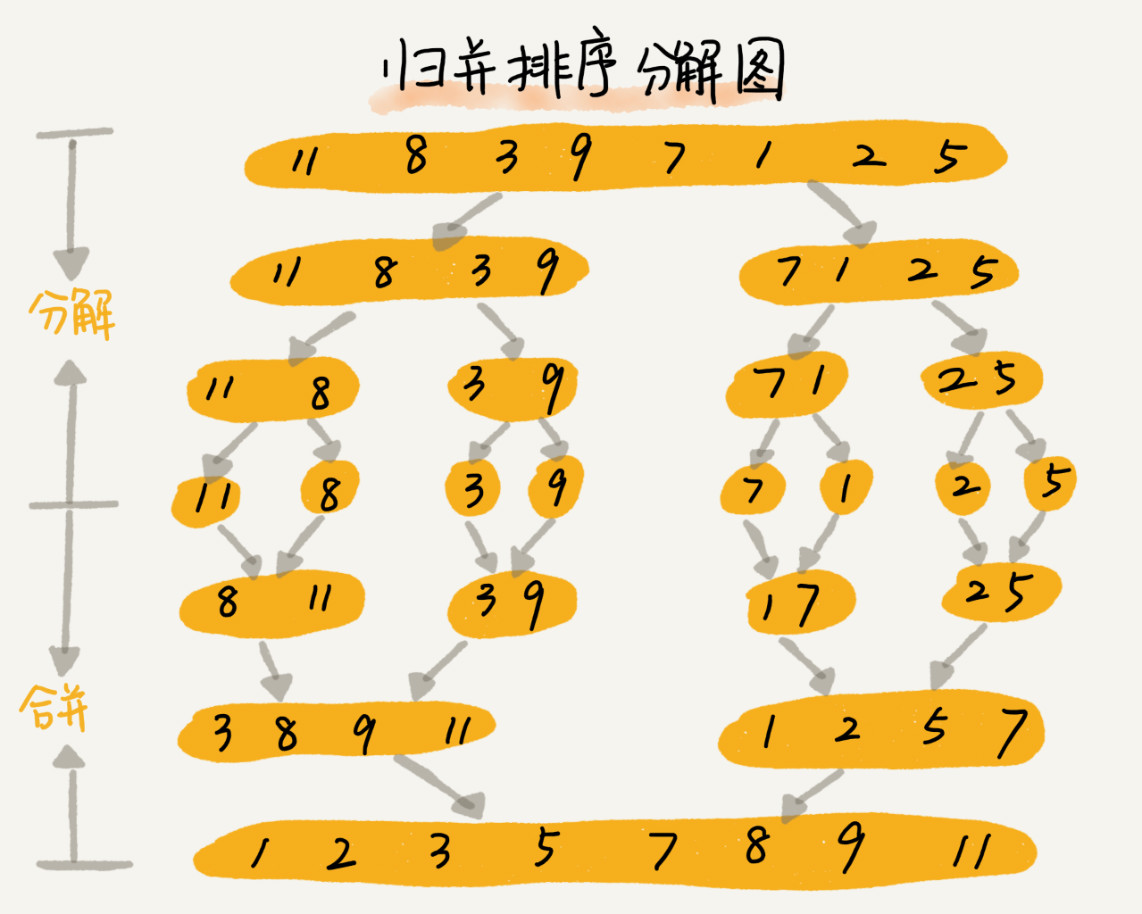
堆排序
线性排序算法
之所以能做到线性的时间复杂度,主要原因是,以下三个算法是非基于比较的排序算法,都不涉及元素之间的比较操作。
这几种排序算法理解起来都不难,时间、空间复杂度分析起来也很简单,但是对要排序的数据要求很苛刻,所以掌握这些排序算法的适用场景是非常重要的。
桶排序
桶排序,顾名思义,会用到“桶”,核心思想是将要排序的数据分到几个有序的桶里,每个桶里的数据再单独进行排序。桶内排完序之后,再把每个桶里的数据按照顺序依次取出,组成的序列就是有序的了。

- 桶排序对要排序数据的要求是非常苛刻的
- 要排序的数据需要很容易就能划分成 m 个桶,并且,桶与桶之间有着天然的大小顺序
- 数据在各个桶之间的分布是比较均匀的
桶排序比较适合用在外部排序中。所谓的外部排序就是数据存储在外部磁盘中,数据量比较大,内存有限,无法将数据全部加载到内存中。
计数排序
计数排序其实是桶排序的一种特殊情况。当要排序的 n 个数据,所处的范围并不大的时候,比如最大值是 k,我们就可以把数据划分成 k 个桶。每个桶内的数据值都是相同的,省掉了桶内排序的时间。
基数排序
来看这样一个排序问题。假设我们有 10 万个手机号码,希望将这 10 万个手机号码从小到大排序,你有什么比较快速的排序方法呢?
假设要比较两个手机号码 a,b 的大小,如果在前面几位中,a 手机号码已经比 b 手机号码大了,那后面的几位就不用看了。
借助稳定排序算法,这里有一个巧妙的实现思路。先按照最后一位来排序手机号码,然后,再按照倒数第二位重新排序,以此类推,最后按照第一位重新排序。经过 11 次排序之后,手机号码就都有序了。
基数排序的思路就是这样
根据每一位来排序,我们可以用刚讲过的桶排序或者计数排序,它们的时间复杂度可以做到 O(n)。如果要排序的数据有 k 位,那我们就需要 k 次桶排序或者计数排序,总的时间复杂度是 O(k*n)。当 k 不大的时候,比如手机号码排序的例子,k 最大就是 11,所以基数排序的时间复杂度就近似于 O(n)。
实际上,有时候要排序的数据并不都是等长的。对于这种不等长的数据,基数排序还适用吗?实际上,我们可以把所有的单词补齐到相同长度,位数不够的可以在后面补“0”,这样就可以继续用基数排序了。
基数排序对要排序的数据是有要求的,需要可以分割出独立的“位”来比较,而且位之间有递进的关系,如果 a 数据的高位比 b 数据大,那剩下的低位就不用比较了。除此之外,每一位的数据范围不能太大,要可以用线性排序算法来排序,否则,基数排序的时间复杂度就无法做到 O(n) 了。
leetcode 题目参考
前K个高频单词
参考链接
https://time.geekbang.org/column/article/41802
https://time.geekbang.org/column/article/41913
https://time.geekbang.org/column/article/42038
https://time.geekbang.org/column/article/42359
https://www.jianshu.com/p/d730ae586cf3
https://visualgo.net/en——可视化算法

若有收获,就点个赞吧
0 人点赞
