概念
- 顶点
- 边
- 度
- 入度
- 出度
- 方向
-
图的存储方式
邻接矩阵
邻接矩阵的底层依赖一个二维数组。
对于无向图来说,如果顶点 i 与顶点 j 之间有边,我们就将
A[i][j]和A[j][i]标记为 1;- 对于有向图来说,如果顶点 i 到顶点 j 之间,有一条箭头从顶点 i 指向顶点 j 的边,那我们就将
A[i][j]标记为 1。同理,如果有一条箭头从顶点 j 指向顶点 i 的边,我们就将A[j][i]标记为 1。 - 对于带权图,数组中就存储相应的权重。
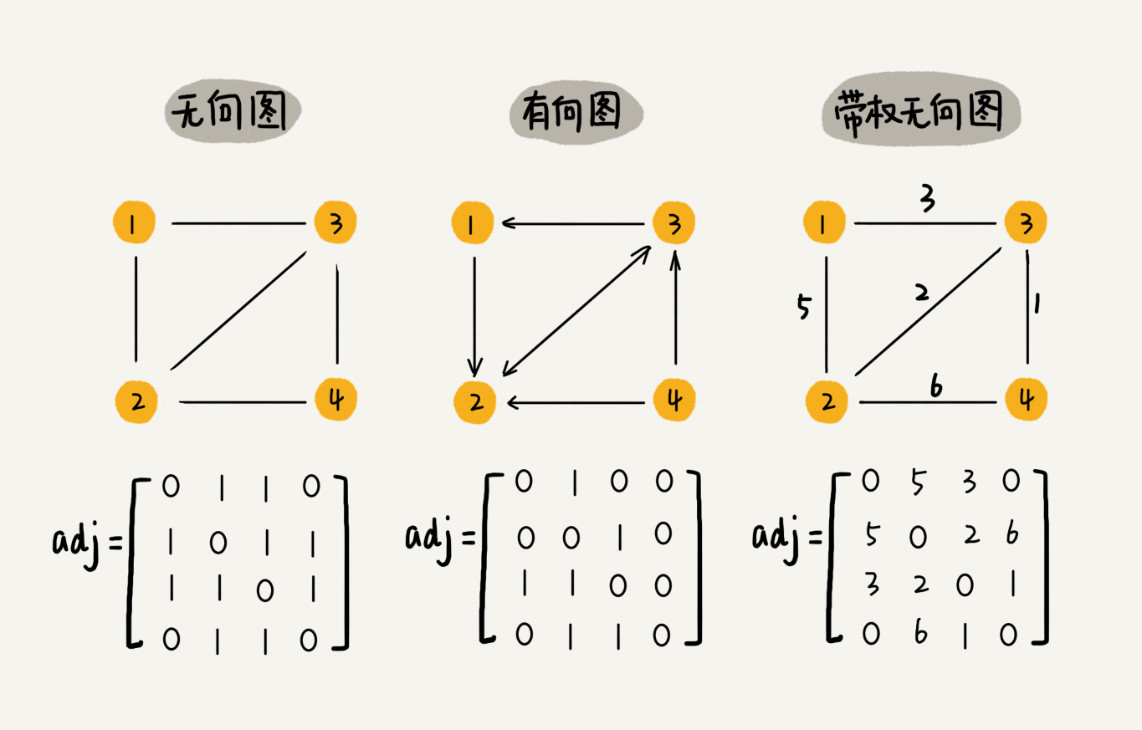
用邻接矩阵来表示一个图,虽然简单、直观,但是比较浪费存储空间。为什么这么说呢?
对于无向图来说,如果 A[i][j]等于 1,那 A[j][i]也肯定等于 1。实际上,我们只需要存储一个就可以了。也就是说,无向图的二维数组中,如果我们将其用对角线划分为上下两部分,那我们只需要利用上面或者下面这样一半的空间就足够了,另外一半白白浪费掉了。
还有,如果我们存储的是稀疏图(Sparse Matrix),也就是说,顶点很多,但每个顶点的边并不多,那邻接矩阵的存储方法就更加浪费空间了。比如微信有好几亿的用户,对应到图上就是好几亿的顶点。但是每个用户的好友并不会很多,一般也就三五百个而已。如果我们用邻接矩阵来存储,那绝大部分的存储空间都被浪费了。
但这也并不是说,邻接矩阵的存储方法就完全没有优点。首先,邻接矩阵的存储方式简单、直接,因为基于数组,所以在获取两个顶点的关系时,就非常高效。其次,用邻接矩阵存储图的另外一个好处是方便计算。这是因为,用邻接矩阵的方式存储图,可以将很多图的运算转换成矩阵之间的运算。比如求解最短路径问题时会提到一个Floyd-Warshall 算法,就是利用矩阵循环相乘若干次得到结果。
邻接表
针对上面邻接矩阵比较浪费内存空间的问题,来看另外一种图的存储方法,邻接表(Adjacency List)。
每个顶点对应一条链表,链表中存储的是与这个顶点相连接的其他顶点。下图中画的是一个有向图的邻接表存储方式,每个顶点对应的链表里面,存储的是指向的顶点。对于无向图来说,也是类似的,不过,每个顶点的链表中存储的,是跟这个顶点有边相连的顶点。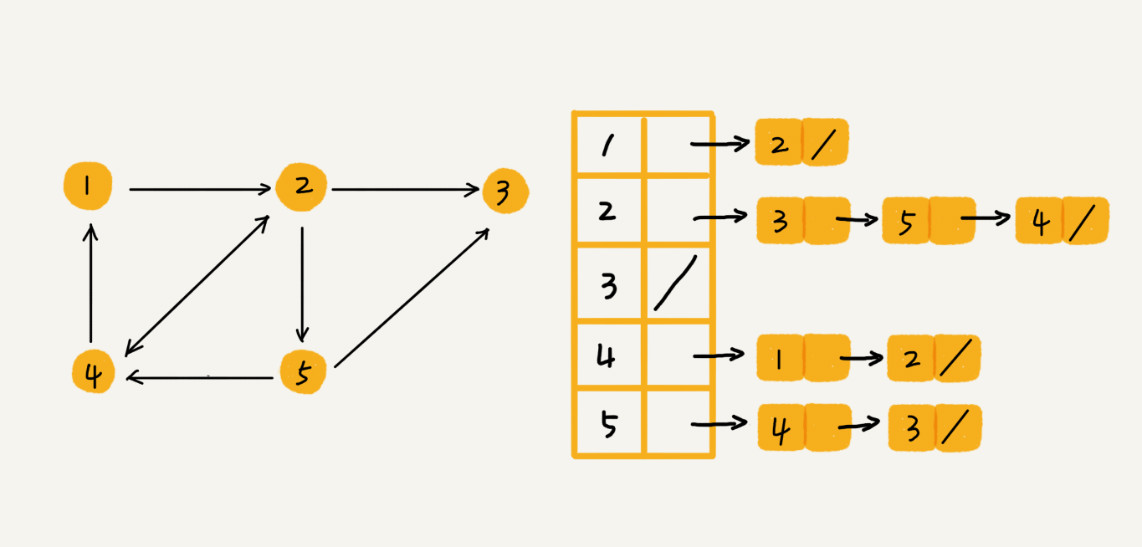
leetcode题目
案例
参考地址

若有收获,就点个赞吧
0 人点赞
