介绍
哈希表 是一种使用 哈希函数 组织数据,以支持 快速插入和搜索 的数据结构。
有两种不同类型的哈希表:哈希集合 和 哈希映射。
- 哈希集合是集合数据结构的实现之一,用于存储 非重复值。
- 哈希映射是映射 数据结构的实现之一,用于存储
(key, value)键值对。原理
hash表用的就是数组支持按照下标随机访问的时候,时间复杂度是 O(1) 的特性。我们通过散列函数把元素的键值映射为下标(桶),然后将数据存储在数组中对应下标(桶)的位置。当我们按照键值查询元素时,我们用同样的散列函数,将键值转化数组下标,从对应的数组下标的位置取数据。
哈希表的关键思想是使用哈希函数 将键映射到存储桶。更确切地说,
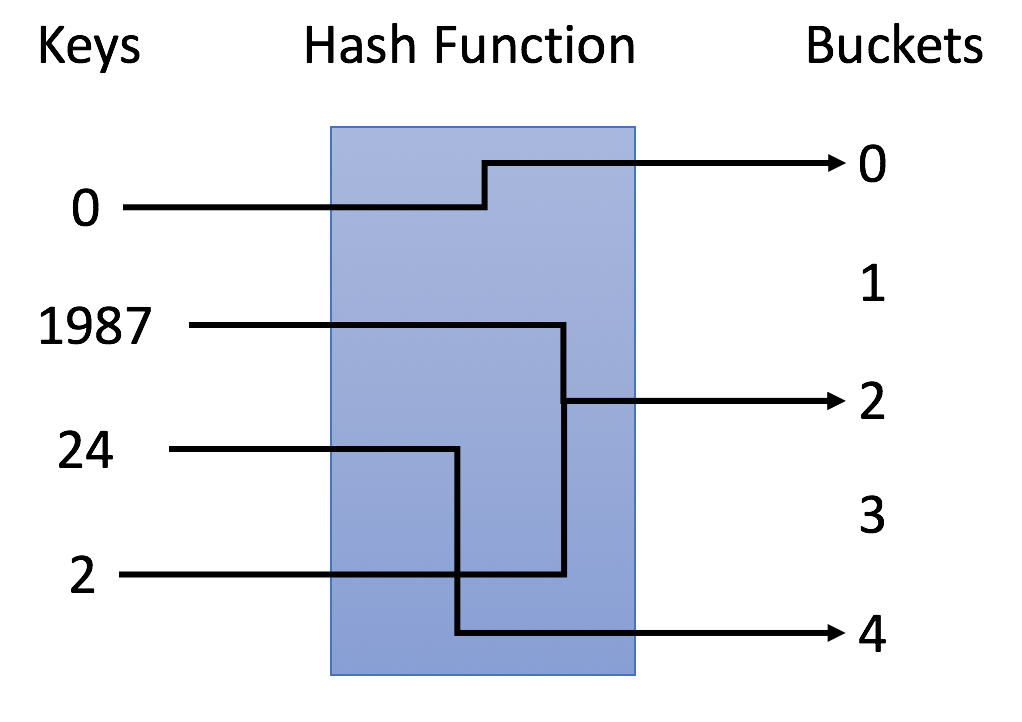
在上例中,使用 y = x % 5 作为哈希函数。让我们使用这个例子来完成插入和搜索策略:
- 插入:通过哈希函数解析键,将它们映射到相应的桶中。
- 例如,1987 分配给桶 2,而 24 分配给桶 4。
- 搜索:通过相同的哈希函数解析键,并仅在特定存储桶中搜索。
- 如果我们搜索 1987,我们将使用相同的哈希函数将1987 映射到 2。因此我们在桶 2 中搜索,我们在那个桶中成功找到了 1987。
- 如果我们搜索 23,将映射 23 到 3,并在桶 3 中搜索。我们发现 23 不在桶 3 中,这意味着 23 不在哈希表中。
设计哈希表的关键
哈希函数
哈希函数是哈希表中最重要的组件,用于将键映射到特定的桶。
散列函数将取决于 键值的范围 和 桶的数量。
下面是一些哈希函数的示例:
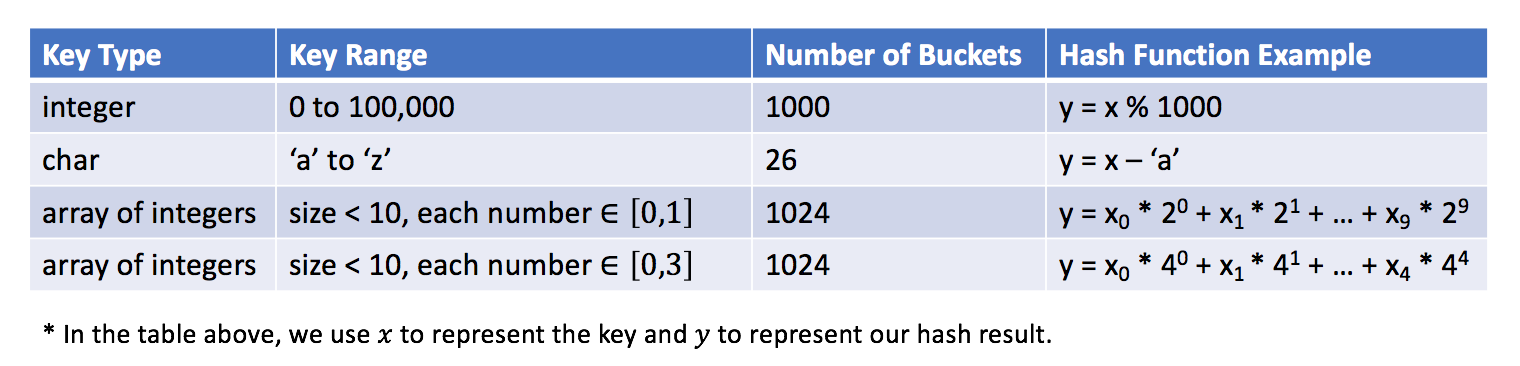
哈希函数的设计是一个开放的问题。其思想是尽可能将键分配到桶中,理想情况下,完美的哈希函数将是键和桶之间的一对一映射。然而,在大多数情况下,哈希函数并不完美,它需要在桶的数量和桶的容量之间进行权衡。
装载因子
当hash表中空闲位置不多的时候,hash冲突的概率就会大大提高。为了尽可能保证hash表的操作效率,一般晴空下,需要尽可能保证hash表中有一定比例的空闲。一般使用 装载因子 来表示空位的多少。
计算公式:
装载因子 = 填入表中的元素个数 / hash表的长度
_
装载因子越大,说明空闲位置越少,冲突越多,散列表的性能会下降。
哈希冲突
再好的hash函数也无法避免冲突。那究竟该如何解决hash冲突问题呢?常用的方法有两类,开放寻址法和链表法。
开放寻址法
开放寻址法的核心思想是,如果出现了散列冲突,我们就重新探测一个空闲位置,将其插入。那如何重新探测新的位置呢?
一个比较简单的探测方法是线性探测(Linear Probing)。
当往散列表中插入数据时,如果某个数据经过散列函数散列之后,存储位置已经被占用了,我们就从当前位置开始,依次往后查找,看是否有空闲位置,直到找到为止。
此时删除操作有些特别,删除的时候不能直接删除元素,而是将其标记为 deleted。当线性探测的时候遇到标记为deleted的空间并不是停下来,而是继续往下探测。
线性探测法其实存在很大问题。当散列表中插入的数据越来越多时,散列冲突发生的可能性就会越来越大,空闲位置会越来越少,线性探测的时间就会越来越久。极端情况下,我们可能需要探测整个散列表,所以最坏情况下的时间复杂度为 O(n)。同理,在删除和查找时,也有可能会线性探测整张散列表,才能找到要查找或者删除的数据。
二次探测
所谓二次探测,跟线性探测很像,线性探测每次探测的步长是 1,那它探测的下标序列就是 hash(key)+0,hash(key)+1,hash(key)+2……而二次探测探测的步长就变成了原来的“二次方”,也就是说,它探测的下标序列就是 hash(key)+0,hash(key)+1^2,hash(key)+2^2……
双重散列
所谓双重散列,意思就是不仅要使用一个散列函数。我们使用一组散列函数 hash1(key),hash2(key),hash3(key)……我们先用第一个散列函数,如果计算得到的存储位置已经被占用,再用第二个散列函数,依次类推,直到找到空闲的存储位置。**
链表法
链表法是一种更加常用的hash冲突解决办法,如下图所示,hash表中每个桶或者槽对应一个链表/数组,所有的值存储在对应的链表中。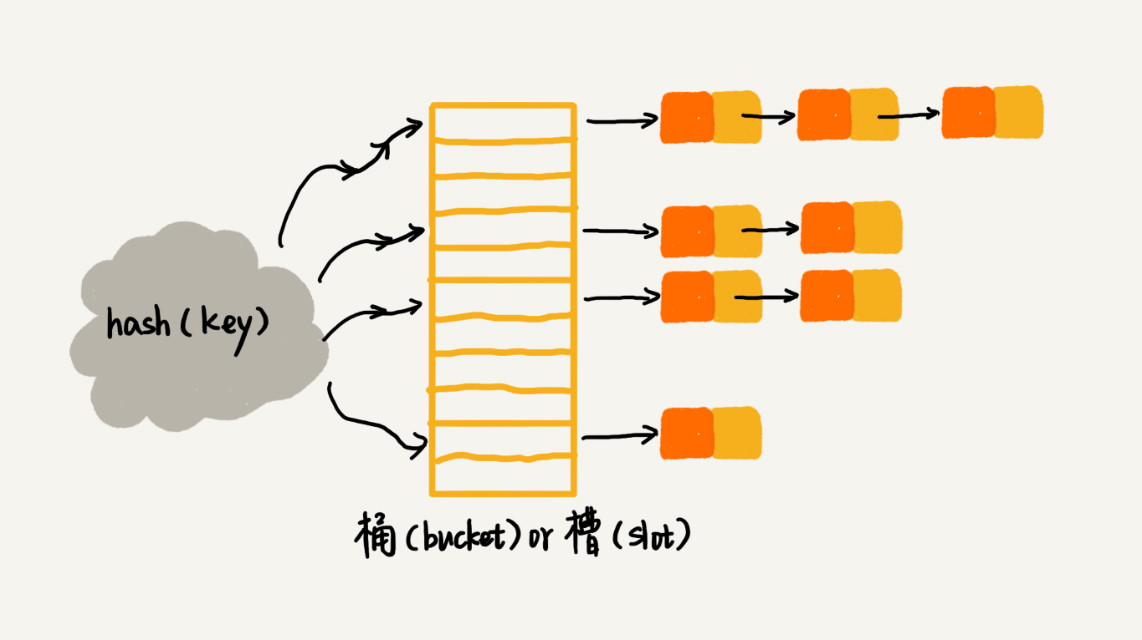
根据哈希函数,这些问题与 桶的容量 和 可能映射到同一个桶的键的数目 有关。
假设存储最大键数的桶有 N 个键。
- 如果
N是常数且很小,可以简单地使用一个数组将键存储在同一个桶中。 - 如果
N是可变的或很大,可能需要使用 高度平衡的二叉树 来代替。
如果使用数组来作为存储桶,
我们来看看 删除 操作。在找到元素的位置之后,需要从数组列表中删除元素。
假设我们要删除第 i 个元素,并且数组列表的大小为 n。
内置函数中使用的策略是把第 i 个元素后的所有元素向前移动一个位置。也就是说,必须移动 n - i 次。因此,从数组列表中删除元素的时间复杂度将为  。
。
考虑 i 取不同值的情况。平均而言,我们将移动 ((n - 1) + (n - 2) + ... + 1 + 0) / n = (n - 1) / 2 次。
有两种解决方案可以将时间复杂度从 降低到  。
。
- 交换
首先,用存储桶中的最后一个元素交换要移除的元素。然后删除最后一个元素。通过这种方法,成功地在 的时间复杂度中去除了元素。
- 链表
实现此目标的另一种方法是使用链表而不是数组列表。通过这种方式,可以在不修改列表中的顺序的情况下删除元素。该策略时间复杂度为 。
复杂度分析
如果总共有 M 个键,在使用哈希表时,可以很容易地达到  的空间复杂度。
的空间复杂度。
但是,你可能已经注意到哈希表的时间复杂度与设计有很强的关系。
我们中的大多数人可能已经在每个桶中使用 数组 来将值存储在同一个桶中,理想情况下,桶的大小足够小时,可以看作是一个常数。插入和搜索的时间复杂度都是 。
但在最坏的情况下,桶大小的最大值将为 N。插入时时间复杂度为 ,搜索时为 。
如何设计一个工业级hash表
https://time.geekbang.org/column/article/64586
语言内置哈希表
内置哈希表的典型设计是:
- 键值可以是 任何可哈希化的类型。并且属于可哈希类型的值将具有 哈希码。此哈希码将用于映射函数以获取存储区索引。
- 每个桶包含一个数组,用于在初始时将所有值存储在同一个桶中。
- 如果在同一个桶中 有太多的值,这些值将被保留在一个 高度平衡的二叉搜索树 中。
如果使用高度平衡的二叉搜索树,则插入和搜索的平均时间复杂度仍为 。最坏情况下插入和搜索的时间复杂度是  ,使用高度平衡的 BST。这是在插入和搜索之间的一种权衡。
,使用高度平衡的 BST。这是在插入和搜索之间的一种权衡。
hash表键的设计(参考)
- 当字符串 / 数组中每个元素的顺序不重要时,可以使用排序后的字符串 / 数组作为键。
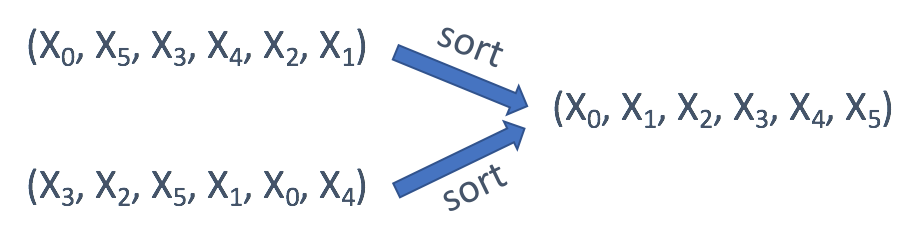
- 如果只关心每个值的偏移量,通常是第一个值的偏移量,则可以使用偏移量作为键。
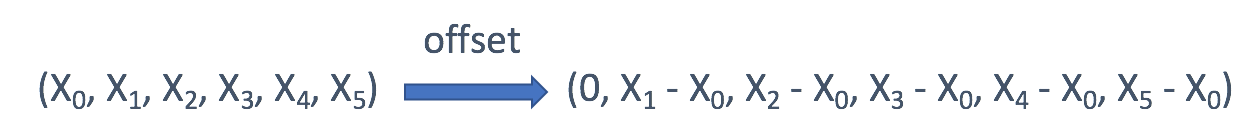
- 在树中,你有时可能会希望直接使用
TreeNode作为键。 但在大多数情况下,采用子树的序列化表述可能是一个更好的主意。
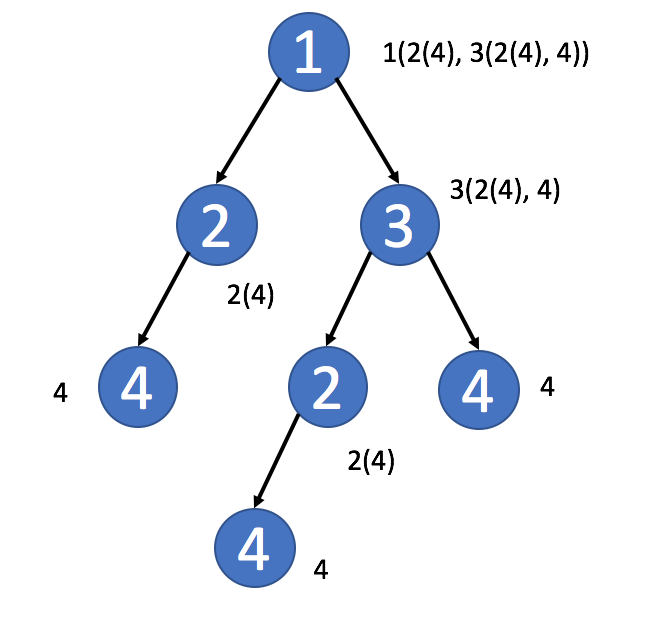
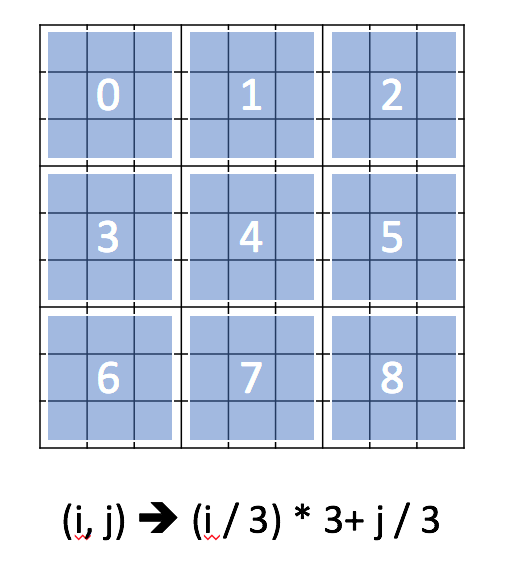
- 在矩阵中,你可能希望使用行索引或列索引作为键。
- 在数独中,可以将行索引和列索引组合来标识此元素属于哪个块。
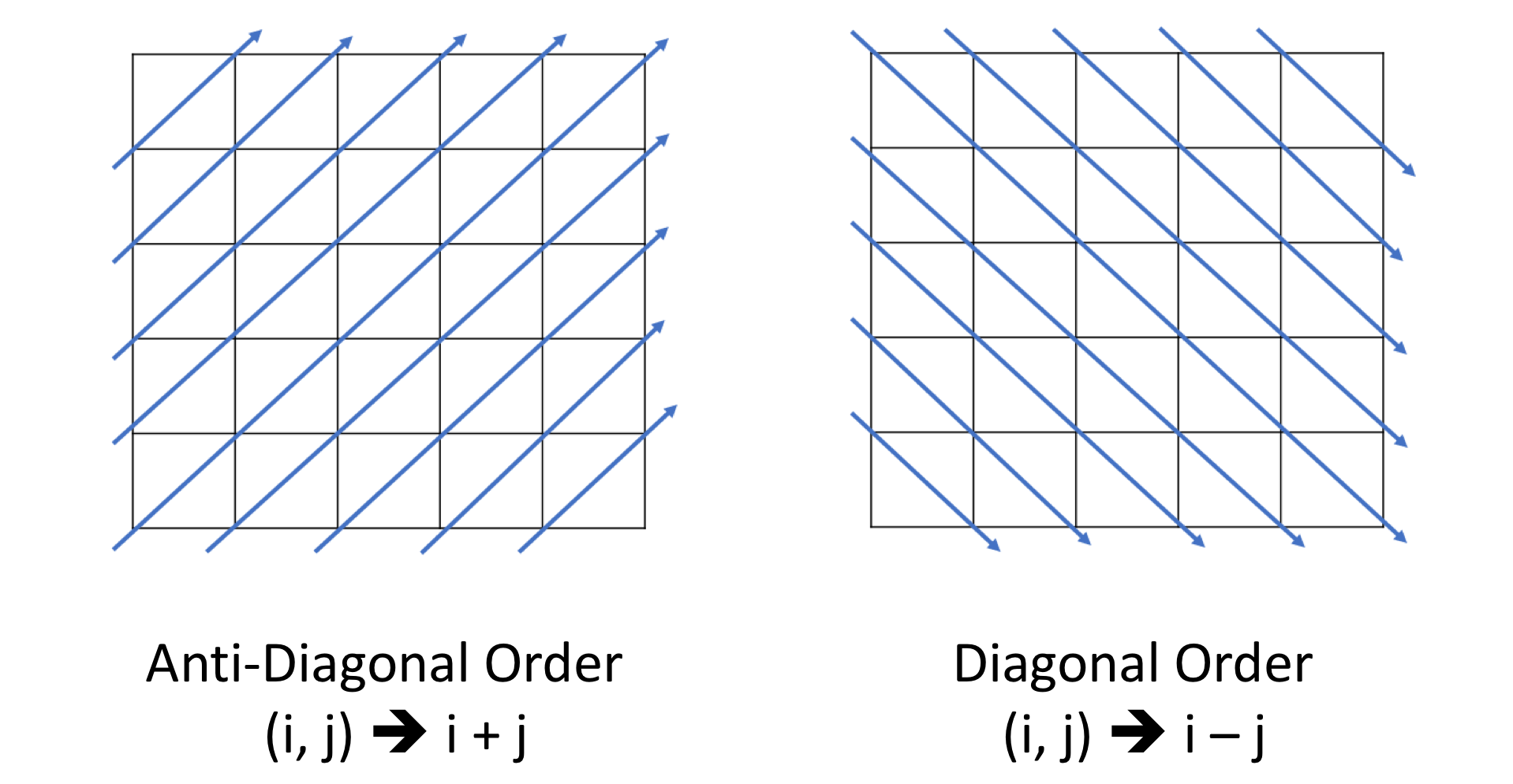
- 有时,在矩阵中,您可能希望将值聚合在同一对角线中。
为什么hash表和链表经常会一起使用?
https://time.geekbang.org/column/article/64858
散列表这种数据结构虽然支持非常高效的数据插入、删除、查找操作,但是散列表中的数据都是通过散列函数打乱之后无规律存储的。也就说,它无法支持按照某种顺序快速地遍历数据。如果希望按照顺序遍历散列表中的数据,那我们需要将散列表中的数据拷贝到数组中,然后排序,再遍历。
因为散列表是动态数据结构,不停地有数据的插入、删除,所以每当我们希望按顺序遍历散列表中的数据的时候,都需要先排序,那效率势必会很低。为了解决这个问题,我们将散列表和链表(或者跳表)结合在一起使用。
参考链接
https://leetcode-cn.com/explore/learn/card/hash-table/
https://leetcode-cn.com/explore/learn/card/hash-table/203/design-a-hash-table/798/
https://leetcode-cn.com/explore/learn/card/hash-table/203/design-a-hash-table/802/
https://leetcode-cn.com/explore/learn/card/hash-table/206/practical-application-design-the-key/824/
https://time.geekbang.org/column/article/64233

若有收获,就点个赞吧
0 人点赞
