机器学习分类通用代码
本文主要提供一种通用的机器学习分类代码,通过重写两个函数完成处理和评价。
提供两种主函数代码,一个用于常规单模型训练和保存,一个用于选取最优模型并生成对比模型数据表格。
主要步骤为:
- 重写数据预处理函数(本文以文本数据TF-IDF为例子)
- 重写评价函数(根据需求从metrics中选取,文本以准去率、精确率、召回率、F1值作为评价标准)
- 载入主函数(数据尽量使用pandas读取结构化类型数据为主,可以先用选优模型主函数调参选取最优模型,再使用单模型调最优模型)
后续版本将要更新的内容:
- 增加预测函数 (读取保存的模型和预处理配置,预测单条数据或多条数据)
- 增加分类结果可视化
- 增加不同的预处理方式样例(增加图片预处理、增加表格数据预处理、增加时序数据预处理)
- 增加不同的评测方法函数
导包
```python 导包 import json import time import joblib import pickle import jieba import pandas as pdsklearn
from sklearn.preprocessing import LabelEncoder from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.linear_model import RidgeClassifier,LogisticRegression from sklearn.naive_bayes import MultinomialNB,BernoulliNB,ComplementNB from sklearn.ensemble import RandomForestClassifier,AdaBoostClassifier,GradientBoostingClassifier from sklearn.svm import SVC from sklearn.tree import DecisionTreeClassifier from sklearn.model_selection import train_test_split from sklearn.metrics import precision_score,recall_score,f1_score,accuracy_score from lightgbm import LGBMClassifier import warnings warnings.filterwarnings(“ignore”, category=DeprecationWarning) warnings.simplefilter(“ignore”)
<a name="AuGXF"></a>## 数据预处理函数```python# 以文本数据为例子,文本数据预处理通常需要使用某种技术转化为稠密向量# 以TF_IDF为例子def TF_IDF_Deal(train_data,content_col,label_col):# 数据预处理部分train_data.drop(0, inplace=True, axis=0)train_data = train_data[[content_col,label_col]]# sample(表示随机抽取 frac表示比例)# train_data = train_data.sample(frac=1.0)# 标签编码并保存target_names = train_data[label_col].value_counts().indexlbl = LabelEncoder().fit(target_names)train_data[label_col] = lbl.transform(train_data[label_col])name_label = {i:str(j) for i, j in zip(lbl.classes_, lbl.transform(target_names))}label_name = {str(j):i for i, j in zip(lbl.classes_, lbl.transform(target_names))}# target_names = dict(sorted(key_value.items(), key=lambda kv: (kv[1], kv[0])))with open("label_name.json","w") as f:json.dump(label_name,f)with open("name_label.json","w") as f:json.dump(name_label,f)# 仅对标题做分词def strcut(s):seg_list = jieba.cut(s)return ' '.join(list(seg_list))train_title = train_data[content_col].apply(strcut)# TF-IDFtfidf = TfidfVectorizer(ngram_range=(1, 1))tfidf.fit_transform(train_title)train_title_ttidf = tfidf.fit_transform(train_title)with open("savemodel/TF_IDF.pkl","wb") as f:pickle.dump(tfidf,f)# 分割数据集tr_x, val_x, tr_tfidf, val_tfidf, tr_y, val_y = train_test_split(train_data[content_col], train_title_ttidf, train_data[label_col],stratify=train_data[label_col],# shuffle=True,test_size=0.2,random_state=666)return tr_x, val_x, tr_tfidf, val_tfidf, tr_y, val_y
评测函数
def predict_metrics_PRF(clf,clf_name,val_tfidf,val_y,with_return=False):val_pred = clf.predict(val_tfidf)accuracy = accuracy_score(y_true=val_y,y_pred=val_pred)precision = precision_score(y_true=val_y,y_pred=val_pred,average='macro')recall = recall_score(y_true=val_y,y_pred=val_pred,average='macro')f1score = f1_score(y_true=val_y,y_pred=val_pred,average='macro')if with_return:return accuracy,precision,recall,f1scoreelse:print("{}:".format(clf_name))print("accuracy: {:.3f}\nprecision: {:.3f}".format(accuracy, precision))print("recall: {:.3f}\nf1score: {:.3f}".format(recall, f1score))
主函数
根据自己数据类型和数据处理方式的不同重写 数据预处理函数
根据自己所需的评价指标重写 评测函数
重写上述两个函数后,可以通过以下结构的代码进行调用,仅用7行代码构成主函数完成一个对机器学习分类模型的训练和保存
if __name__ == '__main__':# 读取数据train_data = pd.read_excel('../data/3_训练数据集20210414_A1.xlsx')# 数据预处理函数tr_x, val_x, tr_tfidf, val_tfidf, tr_y, val_y = TF_IDF_Deal(train_data, 'NEWS_TITLE', 'LABEL')# 模型建立、模型训练、模型保存clf_name = "RidgeClassifier"clf = RidgeClassifier()clf.fit(tr_tfidf, tr_y) # 训练joblib.dump(clf, "savemodel/{}.model".format(clf_name)) # 保存模型# 评测函数predict_metrics_PRF(clf, clf_name,val_tfidf, val_y)
选优模型代码
考虑到不管是比赛还是写paper都需要模型对比,故提供一种选优模型代码,通过遍历所有sklearn库中的分类方法来查看最优模型。
注意:
- 原始代码中模型API都为默认参数,可自己进行调参
- 某些模型必须使用稠密向量,故没有加入进入,如LDA判别模型等
if __name__ == '__main__':# company_name = pd.read_excel('../data/2_企业公司名.xlsx', names=['name'])train_data = pd.read_excel('../data/3_训练数据集20210414_A1.xlsx')# 数据预处理tr_x, val_x, tr_tfidf, val_tfidf, tr_y, val_y = TF_IDF_Deal(train_data,'NEWS_TITLE','LABEL')# model comparemodel_names = ['RidgeClassifier','LogisticRegression','SGDClassifier', # 线性模型'MultinomialNB','BernoulliNB','ComplementNB', # 贝叶斯模型 未加入GaussianNB'KNeighborsClassifier', # 紧邻模型'RandomForestClassifier','AdaBoostClassifier','GradientBoostingClassifier', # 集成模型'SVC', 'DecisionTreeClassifier', # #支持向量机、决策树模型'LGBMClassifier', # LGB kaggle三大杀器之一]models = [RidgeClassifier(),LogisticRegression(),SGDClassifier(),MultinomialNB(),BernoulliNB(),ComplementNB(),KNeighborsClassifier(),RandomForestClassifier(),AdaBoostClassifier(),GradientBoostingClassifier(),SVC(),DecisionTreeClassifier(),LGBMClassifier()]# 找到最优模型all_time = time.time() # 记录开始时间metrics_df = pd.DataFrame([],columns=["model","accuracy","precision","recall","f1_score"]) # 存表for idx,(model,model_name) in enumerate(zip(models,model_names)):start = time.time()clf = model.fit(tr_tfidf,tr_y)# 如果重写了评测函数 需要修改这边的返回值 以及更改生成列表的columns名accuracy,precision,recall,f1score = predict_metrics_PRF(clf,model_name,val_tfidf,val_y,with_return=True)metrics_df.loc[len(metrics_df)] = [model_name,accuracy,precision,recall,f1score]print("{}/{} {} 耗时: {:.3f}sec".format(idx+1,len(model_names),model_name,time.time()-start)) # 打印进度print("总耗时: {:.3f}sec".format(time.time()-all_time))print(metrics_df)metrics_df.to_csv("best_model_metrics.csv",index=False)
效果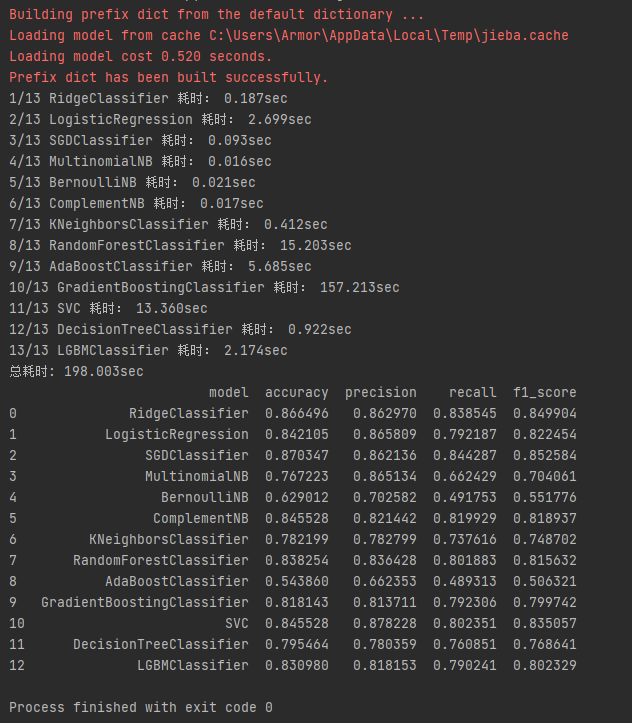
完整代码
#!/usr/bin/env python# -*- encoding: utf-8 -*-'''@File : TF_IDF_Deal.py@Contact : htkstudy@163.com@Modify Time @Author @Version @Desciption------------ ------- -------- -----------2021/5/7 18:29 Armor(htk) 1.0 None'''import jsonimport timeimport joblibimport pickleimport jiebaimport pandas as pdfrom sklearn.preprocessing import LabelEncoderfrom sklearn.svm import SVCfrom sklearn.tree import DecisionTreeClassifierfrom sklearn.neighbors import KNeighborsClassifierfrom sklearn.feature_extraction.text import TfidfVectorizerfrom sklearn.linear_model import RidgeClassifier,LogisticRegression,SGDClassifierfrom sklearn.naive_bayes import MultinomialNB,BernoulliNB,ComplementNB,GaussianNBfrom sklearn.ensemble import RandomForestClassifier,AdaBoostClassifier,GradientBoostingClassifierfrom sklearn.discriminant_analysis import LinearDiscriminantAnalysis,QuadraticDiscriminantAnalysisfrom sklearn.model_selection import train_test_splitfrom sklearn.metrics import precision_score,recall_score,f1_score,accuracy_scorefrom lightgbm import LGBMClassifierimport warningswarnings.filterwarnings("ignore", category=DeprecationWarning)warnings.simplefilter("ignore")def TF_IDF_Deal(train_data,content_col,label_col):# 数据预处理部分train_data.drop(0, inplace=True, axis=0)train_data = train_data[[content_col,label_col]]# sample(表示随机抽取 frac表示比例)# train_data = train_data.sample(frac=1.0)# 标签编码并保存target_names = train_data[label_col].value_counts().indexlbl = LabelEncoder().fit(target_names)train_data[label_col] = lbl.transform(train_data[label_col])name_label = {i:str(j) for i, j in zip(lbl.classes_, lbl.transform(target_names))}label_name = {str(j):i for i, j in zip(lbl.classes_, lbl.transform(target_names))}# target_names = dict(sorted(key_value.items(), key=lambda kv: (kv[1], kv[0])))with open("label_name.json","w") as f:json.dump(label_name,f)with open("name_label.json","w") as f:json.dump(name_label,f)# 仅对标题做分词def strcut(s):seg_list = jieba.cut(s)return ' '.join(list(seg_list))train_title = train_data[content_col].apply(strcut)# TF-IDFtfidf = TfidfVectorizer(ngram_range=(1, 1))tfidf.fit_transform(train_title)train_title_ttidf = tfidf.fit_transform(train_title)with open("savemodel/TF_IDF.pkl","wb") as f:pickle.dump(tfidf,f)# 分割数据集tr_x, val_x, tr_tfidf, val_tfidf, tr_y, val_y = train_test_split(train_data[content_col], train_title_ttidf, train_data[label_col],stratify=train_data[label_col],# shuffle=True,test_size=0.2,random_state=666)return tr_x, val_x, tr_tfidf, val_tfidf, tr_y, val_ydef predict_metrics_PRF(clf,clf_name,val_tfidf,val_y,with_return=False):val_pred = clf.predict(val_tfidf)val_true = val_y.values.tolist()accuracy = accuracy_score(y_true=val_true,y_pred=val_pred)precision = precision_score(y_true=val_true,y_pred=val_pred,average='macro')recall = recall_score(y_true=val_true,y_pred=val_pred,average='macro')f1score = f1_score(y_true=val_true,y_pred=val_pred,average='macro')if with_return:return accuracy,precision,recall,f1scoreelse:print("{}:".format(clf_name))print("accuracy: {:.3f}\nprecision: {:.3f}".format(accuracy, precision))print("recall: {:.3f}\nf1score: {:.3f}".format(recall, f1score))def model_example():# company_name = pd.read_excel('../data/2_企业公司名.xlsx', names=['name'])train_data = pd.read_excel('../data/3_训练数据集20210414_A1.xlsx')# 数据预处理tr_x, val_x, tr_tfidf, val_tfidf, tr_y, val_y = TF_IDF_Deal(train_data, 'NEWS_TITLE', 'LABEL')# 模型构造clf_name = "RidgeClassifier"clf = RidgeClassifier()clf.fit(tr_tfidf, tr_y) # 训练joblib.dump(clf, "savemodel/{}.model".format(clf_name)) # 保存模型# 评价效果predict_metrics_PRF(clf, clf_name,val_tfidf, val_y)# if __name__ == '__main__':# # 数据预处理# with open("savemodel/TF_IDF.pkl",'rb') as f:# tfidf = pickle.load(f)# val_x = tfidf.fit_transform(val_x)# print(val_x)# # 加载模型# clf = joblib.load(savemodel_path)# # 预测# val_pred = clf.predict(val_x)# with open("label_name.json",'r') as f:# key_values = json.load(f)# label_pred = [key_values[str(i)] for i in val_pred]# return val_pred,label_predif __name__ == '__main__':# company_name = pd.read_excel('../data/2_企业公司名.xlsx', names=['name'])train_data = pd.read_excel('../data/3_训练数据集20210414_A1.xlsx')# 数据预处理tr_x, val_x, tr_tfidf, val_tfidf, tr_y, val_y = TF_IDF_Deal(train_data,'NEWS_TITLE','LABEL')# model comparemodel_names = ['RidgeClassifier','LogisticRegression','SGDClassifier', # 线性模型'MultinomialNB','BernoulliNB','ComplementNB', # 贝叶斯模型 未加入GaussianNB'KNeighborsClassifier', # 紧邻模型'RandomForestClassifier','AdaBoostClassifier','GradientBoostingClassifier', # 集成模型'SVC', 'DecisionTreeClassifier', # #支持向量机、决策树模型'LGBMClassifier', # LGB kaggle三大杀器之一]models = [RidgeClassifier(),LogisticRegression(),SGDClassifier(),MultinomialNB(),BernoulliNB(),ComplementNB(),KNeighborsClassifier(),RandomForestClassifier(),AdaBoostClassifier(),GradientBoostingClassifier(),SVC(),DecisionTreeClassifier(),LGBMClassifier()]# 找到最优模型all_time = time.time() # 记录开始时间metrics_df = pd.DataFrame([],columns=["model","accuracy","precision","recall","f1_score"]) # 存表for idx,(model,model_name) in enumerate(zip(models,model_names)):start = time.time()clf = model.fit(tr_tfidf,tr_y)# 如果重写了评测函数 需要修改这边的返回值 以及更改生成列表的columns名accuracy,precision,recall,f1score = predict_metrics_PRF(clf,model_name,val_tfidf,val_y,with_return=True)metrics_df.loc[len(metrics_df)] = [model_name,accuracy,precision,recall,f1score]print("{}/{} {} 耗时: {:.3f}sec".format(idx+1,len(model_names),model_name,time.time()-start)) # 打印进度print("总耗时: {:.3f}sec".format(time.time()-all_time))print(metrics_df)metrics_df.to_csv("best_model_metrics.csv",index=False)

若有收获,就点个赞吧
0 人点赞
