EDA(Exploratory Data Analysis)通常是数据科学比赛的第一步,当我们拿到训练集时往往需要先探索一下,确认数据的分布状况、缺失值、字符串、时间标签等,通常EDA时最花费时间但也是能提升模型效果最有效的方法之一,借用大佬们常说的“数据质量决定算法的上限,算法只是逼近这个上限”
之前EDA都是一行一码敲出来再进行统计分析,接下来介绍几个快速进行EDA的探索工具。
- Pandas Profiling
- Sweetviz
- Dataprep
演示数据集
kaggle经典数据集 - 泰坦尼克号生存预测
数据集地址:https://www.kaggle.com/c/titanic/data?select=train.csv
关于kaggle这里不做过多的介绍了,先导入数据
import pandas as pddf = pd.read_csv('/content/train.csv')
1. Pandas Profiling
地址:https://github.com/pandas-profiling/pandas-profilingPandas Profiling 应该是最出名的Auto EDA工具之一,其本身是pandas的延伸产物,仅需二三行代码就可以完成EDA。该工具笔者最早在kaggle上某个大佬的数据分析notenook上了解到的。首先安装工具:
pip install pandas-profiling
pandas-profiling会将EDA结果绘制成一份可以交互的html报表,针对每个特征进行分析,包含数据分布、缺失值、相关性等。使用方法非常简单,代码如下:
import pandas as pdfrom pandas_profiling import ProfileReportreport = ProfileReport(df, title="Titanic Dataset")report.to_file("Titanic_Dataset_Pandas_Profiling.html")
EDA效果展示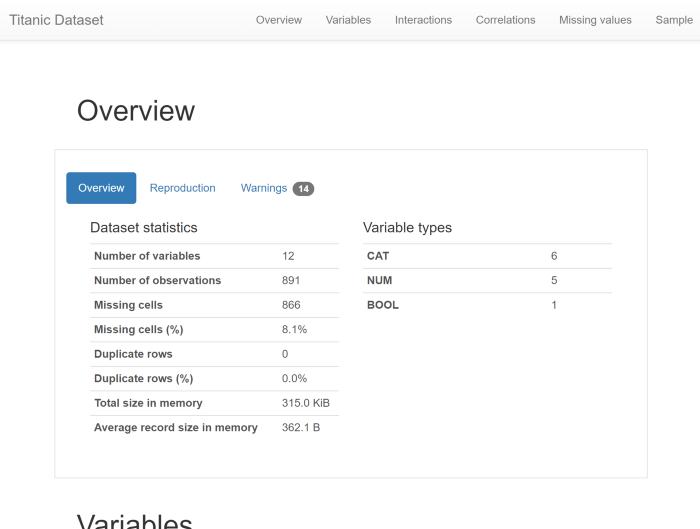
pandas-profiling的有优点是全面,基本包含了所有数据EDA信息。但相对界面比较单调,不够灵活。
2. Sweetviz
地址:https://github.com/fbdesignpro/sweetvizSweetviz也是近期非常流行的EDA工具,和上面的Pandas Profiling的一样可以数据的快速探索,但对变量间的相关分析比较少。
安装:
pip install sweetviz
代码:
import sweetviz as svreport = sv.analyze(df)report.show_html(filepath='Titanic_Dataset_Sweetviz.html')
Sweetviz会生成色彩艳丽的报表,且因为运算做过优化,生成速度也会比Pandas Profiling快一些。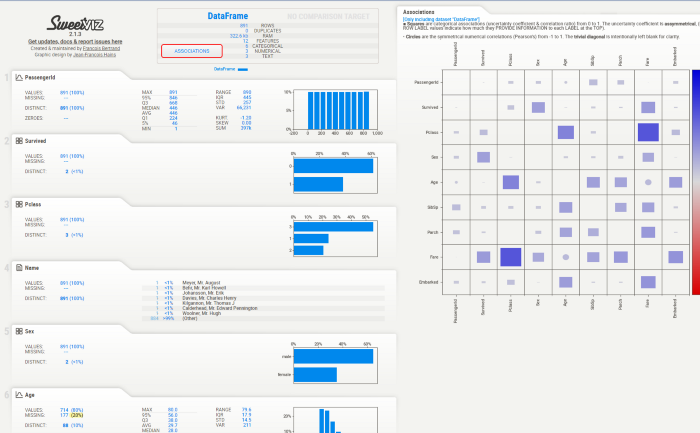
Sweetviz 另一个特别的功能是可以做两个数据集之间的比较。
例如,联合 Training data 和 Testing data 的分析: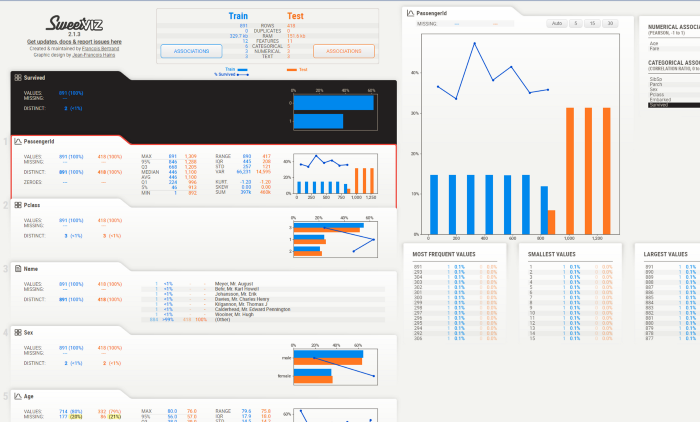
3.Dataprep
地址:https://github.com/sfu-db/dataprepDataprep也是一个快速建立EDA报表的工具,且功能丰富强大,很成为热门工具的潜力。
安装:
pip install dataprep
使用代码:
from dataprep import eda as dpedareport = dpeda.create_report(df, title='Titanic Dataset')report.save('Titanic_Dataset_Dataprep')
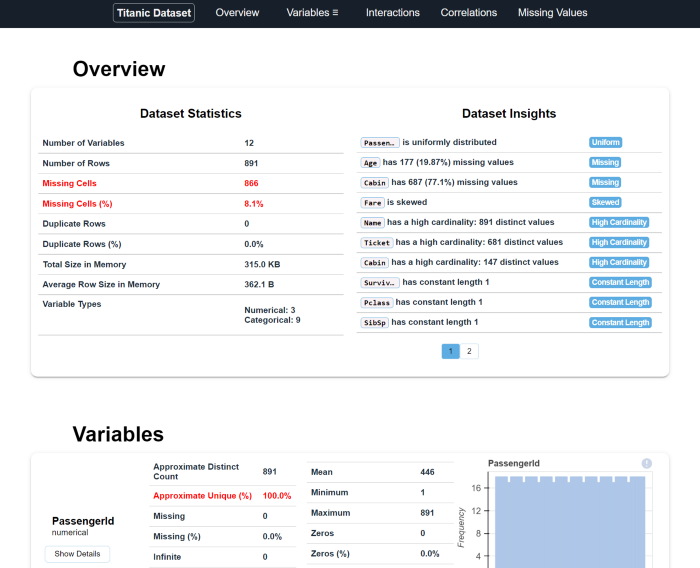
Dataprep的呈现方式和pandas-profiling很像但是更细腻,也更细粒度。对文本特征内容会用词云图进行展示。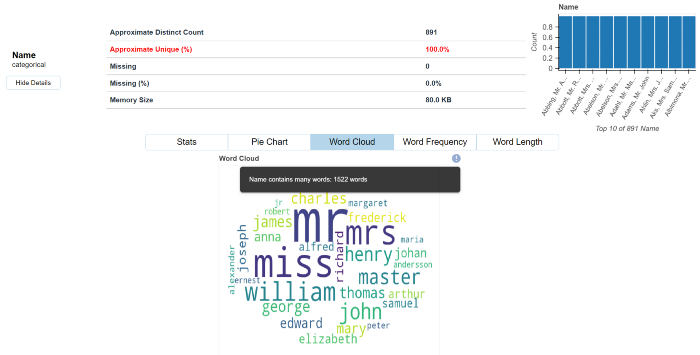
更多的功能就期待大家自己探索了
此外,自动化EDA还有其他工具,例如AutoViz、ExploriPy、speedML 等,但功能比较偏半自动化。

若有收获,就点个赞吧
0 人点赞
