参考笔记:掘金-NLP预处理技术
笔者根据其框架并根据自身学习扩充了对应的特征提取的Feature Extraction内容
1.特征提取
为了能够更好的训练模型,我们需要将文本的原始特征转化成具体特征,转化的方式主要有两种:统计和Embedding。
原始特征:需要人类或者机器进行转化,如:文本、图像。
具体特征:已经被人类进行整理和分析,可以直接使用,如:物体的重要、大小。
1.1 统计
- 词频,是指某一个给定的词在该文件中出现的频率,需要进行归一化,避免偏向长文本
- 逆向文件频率,是一个词普遍重要性的度量,由总文件数目除以包含该词的文件数目
那么,每个词都会得到一个TF-IDF值,用来衡量它的重要程度,计算公式如下:
其中的式子中
是该词在文件
中的出现次数,而分母则是在文件
中所有词的出现次数之和。
而的式子中
表示语料库中文件总数,
表示包含词
的文件数目,而
是对结果做平滑处理。
TF_IDF可以使用sklearn机器学习库进行快速搭建,也可以使用jieba等自然语言工具调用。
可参考资料:sklearn-TfidfVectorizer彻底说清楚
1)下面的代码使用了sklearn的TFIDF算法进行特征提取
# 使用 sklearn的TFIDF算法进行特征提取import jiebafrom sklearn.feature_extraction.text import TfidfTransformer,TfidfVectorizer,CountVectorizercorpus = ["词频,是指某一个给定的词在该文件中出现的频率,需要进行归一化,避免偏向长文本","逆向文件频率,是一个词普遍重要性的度量,由总文件数目除以包含该词的文件数目"]corpus_list = []for corpu in corpus:corpus_list.append(" ".join(jieba.cut_for_search(corpu)))print("\n语料大小:{}\n{}".format(len(corpus_list),corpus_list))vectorizer = TfidfVectorizer(use_idf=True, smooth_idf=True, norm=None)tfidf = vectorizer.fit_transform(corpus_list)weight = tfidf.toarray()vocab = vectorizer.get_feature_names()print("\n词汇表大小:{}\n{}".format(len(vocab),vocab))print("\n权重形状:{}\n{}".format(weight.shape,weight))

2)使用jieba分词中的TFIDF算法进行关键词提取
# jieba分词中 基于TFIDF的关键词提取import jiebaimport jieba.analysesentences = ['中华蜜蜂原产于中国,是中国的土著蜂,适应中国各地的气候和蜜源条件,适于定地饲养且稳产,尤其是在南方山区,有着其他蜂种不可替代的地位。','东方蜜蜂原产地在东方、简称东蜂,是蜜蜂属中型体中等的一个品种,分布于亚洲的中国、伊朗、日本、朝鲜等多个国家以及俄罗斯远东地区。该品种个体耐寒性强,适应利用南方冬季蜜源。']seg_list = []for sentence in sentences:seg_list.append(", ".join(jieba.cut(sentence, cut_all=True)))print("\n语料大小:{}\n{}".format(len(seg_list),seg_list))keywords = jieba.analyse.extract_tags(sentences[0], topK=20, withWeight=True, allowPOS=('n','nr','ns'))print("\n关键词大小:{}\n{}".format(len(keywords),keywords))keywords = jieba.analyse.extract_tags(sentences[1], topK=20, withWeight=True, allowPOS=('n','nr','ns'))print("\n关键词大小:{}\n{}".format(len(keywords),keywords))

1.2 Embedding - Word2vec 实践
Embedding是将词嵌入到一个由神经网络的隐藏层权重构成的空间中,让语义相近的词在这个空间中距离也是相近的。Word2vec就是这个领域具有表达性的方法,大体的网络结构如下: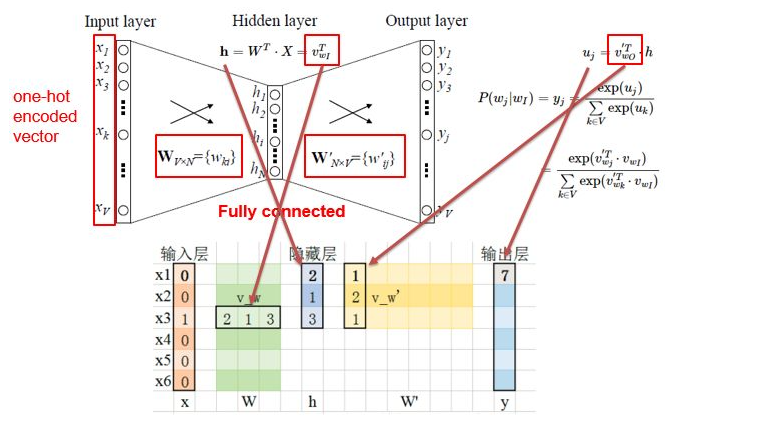
输入层是经过One-Hot编码的词,隐藏层是我们想要得到的Embedding维度,而输出层是我们基于语料的预测结果。不断迭代这个网络,使得预测结果与真实结果越来越接近,直到收敛,我们就得到了词的Embedding编码,一个稠密的且包含语义信息的词向量,可以作为后续模型的输入。
参考资料:
部分资料版本老旧代码失效,gensim请以教程版本为准,保准代码可以run通
[1] : getting-started-with-word2vec-and-glove-in-python
[2] : python︱gensim训练word2vec及相关函数与功能理解
[3] : gensim中word2vec使用
[4] : gensim中word2vec使用
5.2.1.1 自建数据集创建和训练Word2vec
import gensimprint("gensim 版本:",gensim.__version__)# gensim 版本: 3.8.3
gensim是一款强大的自然语言处理工具,里面包括N多常见模型:
基本的语料处理工具、LSI、LDA、HDP、DTM、DIM、TF-IDF、word2vec、paragraph2vec
第一种方法:最简单的训练方法(快速)
# 最简单的训练方式 - 一键训练# 引入 word2vecfrom gensim.models import word2vec# 引入数据集sentences = ['中华蜜蜂原产于中国,是中国的土著蜂,适应中国各地的气候和蜜源条件,适于定地饲养且稳产,尤其是在南方山区,有着其他蜂种不可替代的地位。','东方蜜蜂原产地在东方、简称东蜂,是蜜蜂属中型体中等的一个品种,分布于亚洲的中国、伊朗、日本、朝鲜等多个国家以及俄罗斯远东地区。该品种个体耐寒性强,适应利用南方冬季蜜源。']seg_list = []for sentence in sentences:seg_list.append(" ".join(jieba.cut(sentence, cut_all=True)))# 切分词汇sentences = [s.split() for s in seg_list]# 构建模型model = word2vec.Word2Vec(sentences, min_count=1,size=100)"""Word2Vec的参数min_count:在不同大小的语料集中,我们对于基准词频的需求也是不一样的。譬如在较大的语料集中,我们希望忽略那些只出现过一两次的单词,这里我们就可以通过设置min_count参数进行控制。一般而言,合理的参数值会设置在 0~100 之间。size:参数主要是用来设置词向量的维度,Word2Vec 中的默认值是设置为 100 层。更大的层次设置意味着更多的输入数据,不过也能提升整体的准确度,合理的设置范围为 10~数百。workers:参数用于设置并发训练时候的线程数,不过仅当Cython安装的情况下才会起作用。"""# 进行相关性比较model.wv.similarity('东方','中国')
第二种方法:分阶段式的训练方法(灵活)
# 引入数据集sentences = ['中华蜜蜂原产于中国,是中国的土著蜂,适应中国各地的气候和蜜源条件,适于定地饲养且稳产,尤其是在南方山区,有着其他蜂种不可替代的地位。','东方蜜蜂原产地在东方、简称东蜂,是蜜蜂属中型体中等的一个品种,分布于亚洲的中国、伊朗、日本、朝鲜等多个国家以及俄罗斯远东地区。该品种个体耐寒性强,适应利用南方冬季蜜源。']seg_list = []for sentence in sentences:seg_list.append(" ".join(jieba.cut(sentence, cut_all=True)))# 切分词汇sentences = [s.split() for s in seg_list]# 先启动一个空模型 an empty modelnew_model = gensim.models.Word2Vec(min_count=1)# 建立词汇表new_model.build_vocab(sentences)# 训练word2vec模型new_model.train(sentences, total_examples=new_model.corpus_count, epochs=new_model.epochs)# 进行相关性比较new_model.wv.similarity('东方','中国')
分阶段训练的另一个作用:增量训练
# 增量训练old_model = gensim.models.Word2Vec.load(temp_path)# old_model = new_modelmore_sentences = [['东北','黑蜂','分布','在','中国','黑龙江省','饶河县',',','它','是','在','闭锁','优越','的','自然环境','里',',','通过','自然选择','与','人工','进行','所','培育','的','中国','唯一','的','地方','优良','蜂种','。']]old_model.build_vocab(more_sentences, update=True)old_model.train(more_sentences, total_examples=model.corpus_count, epochs=model.epochs)# 进行相关性比较new_model.wv.similarity('东方','中国')
5.2.1.2 外部语料库导入得到的word2vec
text8下载地址
第一种方式:载入语料法
# 外部语料引入 【text8】:http://mattmahoney.net/dc/text8.zipsentences = word2vec.Text8Corpus('./text8')model = word2vec.Word2Vec(sentences, size=200)
flag = Falseif flag:class Text8Corpus(object):"""Iterate over sentences from the "text8" corpus, unzipped from http://mattmahoney.net/dc/text8.zip ."""def __init__(self, fname, max_sentence_length=MAX_WORDS_IN_BATCH):self.fname = fnameself.max_sentence_length = max_sentence_lengthdef __iter__(self):# the entire corpus is one gigantic line -- there are no sentence marks at all# so just split the sequence of tokens arbitrarily: 1 sentence = 1000 tokenssentence, rest = [], b''with utils.smart_open(self.fname) as fin:while True:text = rest + fin.read(8192) # avoid loading the entire file (=1 line) into RAMif text == rest: # EOFwords = utils.to_unicode(text).split()sentence.extend(words) # return the last chunk of words, too (may be shorter/longer)if sentence:yield sentencebreaklast_token = text.rfind(b' ') # last token may have been split in two... keep for next iterationwords, rest = (utils.to_unicode(text[:last_token]).split(),text[last_token:].strip()) if last_token >= 0 else ([], text)sentence.extend(words)while len(sentence) >= self.max_sentence_length:yield sentence[:self.max_sentence_length]sentence = sentence[self.max_sentence_length:]
第二种方法:载入模型文件法
# 此种方法需保证有vectors.npymodel_normal = gensim.models.KeyedVectors.load('text.model')model_binary = gensim.models.KeyedVectors.load_word2vec_format('text.model.bin', binary=True)
5.2.1.3 word2vec的两种格式的存储和读取方法
# 普通保存model.wv.save('text.model')# model = Word2Vec.load('text8.model')model_normal = gensim.models.KeyedVectors.load('text.model')# 二进制保存model.wv.save_word2vec_format('text.model.bin', binary=True)# model = word2vec.Word2Vec.load_word2vec_format('text.model.bin', binary=True)model_binary = gensim.models.KeyedVectors.load_word2vec_format('text.model.bin', binary=True)
5.2.1.4 训练好的word2vec怎么用? 养兵千日用兵一时
# 相似度 比较model.similarity('肖战', '王一博'),model.similarity('肖战', '张艺兴'),model.similarity('王一博', '张艺兴')
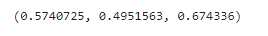
# 相近词 排列model.most_similar(positive=['腾讯'], topn=10)

# 不相关词 识别model.doesnt_match("早饭 中饭 晚饭 土豆 夜宵 加餐".split())

# 比较两个列表的相似度model.n_similarity(['皇帝','国王',"朕","天子"],['陛下'])

# 得到词向量model["重庆"]

# 获取词汇表model.vocab.keys()vocab = model.index2word[:100]
5.2.1.5 word2vec 和 深度学习框架
word2vec 如何与神经网络相结合呢?
- tensorflow 版本
- torch 版本
参考资料: https://zhuanlan.zhihu.com/p/210808209
import numpy as npimport tensorflow as tffrom tensorflow.keras.preprocessing.sequence import pad_sequencesfrom tensorflow.keras.preprocessing.text import Tokenizerfrom tensorflow.keras.utils import to_categorical#导入word2vec模型并进行预处理def w2v_model_preprocessing(content,w2v_model,embedding_dim,max_len=32):# 初始化 `[word : index]` 字典word2idx = {"_PAD": 0}# 训练数据 词汇表构建tokenizer = Tokenizer()tokenizer.fit_on_texts(sentences)vocab_size = len(tokenizer.word_index) # 词库大小print(tokenizer.word_index)error_count = 0# 存储所有 word2vec 中所有向量的数组,其中多一位,词向量全为 0, 用于 paddingembedding_matrix = np.zeros((vocab_size + 1, w2v_model.vector_size))print(embedding_matrix.shape)for word, i in tokenizer.word_index.items():if word in w2v_model:embedding_matrix[i] = w2v_model.wv[word]else:error_count += 1# 训练数据 词向量截断补全(padding)seq = tokenizer.texts_to_sequences(sentences)trainseq = pad_sequences(seq, maxlen=max_len,padding='post')return embedding_matrix,trainseq# 从文本 到 tf可用的word2vecsentences = ['中华蜜蜂原产于中国,是中国的土著蜂,适应中国各地的气候和蜜源条件,适于定地饲养且稳产,尤其是在南方山区,有着其他蜂种不可替代的地位。','东方蜜蜂原产地在东方、简称东蜂,是蜜蜂属中型体中等的一个品种,分布于亚洲的中国、伊朗、日本、朝鲜等多个国家以及俄罗斯远东地区。该品种个体耐寒性强,适应利用南方冬季蜜源。']seg_list = []for sentence in sentences:seg_list.append(" ".join(jieba.cut(sentence, cut_all=True)))sentences = [s.split() for s in seg_list]# 一些超参数max_len = 64embedding_dim = model.vector_sizeembedding_matrix,train_data = w2v_model_preprocessing(sentences,model,embedding_dim,max_len)embedding_matrix.shape,train_data.shape
from tensorflow.keras.models import Sequential,Modelfrom tensorflow.keras.models import load_modelfrom tensorflow.keras.layers import Dense,Dropout,Activation,Input, Lambda, Reshape,concatenatefrom tensorflow.keras.layers import Embedding,Conv1D,MaxPooling1D,GlobalMaxPooling1D,Flatten,BatchNormalizationfrom tensorflow.keras.losses import categorical_crossentropyfrom tensorflow.keras.optimizers import Adamfrom tensorflow.keras.regularizers import l2def build_textcnn(max_len,embeddings_dim,embeddings_matrix):#构建textCNN模型main_input = Input(shape=(max_len,), dtype='float64')# 词嵌入(使用预训练的词向量)embedder = Embedding(len(embeddings_matrix), #表示文本数据中词汇的取值可能数,从语料库之中保留多少个单词embeddings_dim, # 嵌入单词的向量空间的大小input_length=max_len, #规定长度weights=[embeddings_matrix],# 输入序列的长度,也就是一次输入带有的词汇个数trainable=False # 设置词向量不作为参数进行更新)embed = embedder(main_input)flat = Flatten()(embed)dense01 = Dense(5096, activation='relu')(flat)dense02 = Dense(1024, activation='relu')(dense01)main_output = Dense(2, activation='softmax')(dense02)model = Model(inputs=main_input, outputs=main_output)model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])model.summary()return modelTextCNN = build_textcnn(64,embedding_dim,embedding_matrix)# 数据集加载X_train, y_train = train_data,to_categorical([0,1], num_classes=2)# 粗糙的模型训练history = TextCNN.fit(X_train, y_train,batch_size=2,epochs=3,verbose=1)
5.2.1.6 word2vec的可视化方法
from sklearn.decomposition import PCAimport matplotlib.pyplot as pltdef wv_visualizer(model,word):# 寻找出最相似的十个词words = [wp[0] for wp in model.wv.most_similar(word,topn=10)]# 提取出词对应的词向量wordsInVector = [model.wv[word] for word in words]wordsInVector# 进行 PCA 降维pca = PCA(n_components=2)pca.fit(wordsInVector)X = pca.transform(wordsInVector)# 绘制图形xs = X[:, 0]ys = X[:, 1]# drawplt.figure(figsize=(12,8))plt.scatter(xs, ys, marker = 'o')for i, w in enumerate(words):plt.annotate(w,xy = (xs[i], ys[i]), xytext = (6, 6),textcoords = 'offset points', ha = 'left', va = 'top',**dict(fontsize=10))plt.show()# 调用时传入目标词组即可wv_visualizer(model,["man","king"])


若有收获,就点个赞吧
0 人点赞
