
时间:Article 2020
单位:University of Texas at Dallas
文献来源:https://arxiv.org/pdf/2004.00387.pdf
Deep Learning on Knowledge Graph for Recommend.pdf
Abstract
- 背景
1.知识图谱为推荐系统提供了有价值的外部知识,从而增强了推荐系统的表现。
2.兴起的图神经网络(GNN)可以从KG中提取对象特征和关系,是推荐成功的因素之一。
- 主要工作介绍
1.本文对基于GNN的知识感知深度推荐系统(GNN-based knowledge aware depp recommender system,GNN-KADR)进行了全面的综述,特别是GNN-KADR中的soft框架,重点讨论了图嵌入这一核心模块,以及如何缓解推荐系统的可扩展性问题和冷启动问题。
2.总结了常用的基准数据集、评价指标以及开源代码
3.提出未来有发展潜力的方向
1 Introduction
【传统推荐系统和知识图谱】
传统的推荐系统主要有两种结构:基于内容的系统( Content-based system)和基于协同过滤的系统(collaborative-filtering based system)。基于内容的系统可以将数据映射到欧几里德空间中表示为向量,并基于向量相似度进行度量。基于协同过滤的系统通常假设每个用户-项目交互是一个不依赖附带附加信息编码的实例。然而,近期越来越多的应用程序将数据映射到非欧几里德域中生成并以知识图谱(KG)的形式表示。这种数据结构打破了依赖交互数据的假设,将项目与其属性联系起来。例如,在YouTube RS中(如图1所示),用户和电影之间的连接可能是诸如浏览、喜欢和评论之类的动作。另一方面,电影可以共享相同的类型、导演等。通过这些信息,知识感知的推荐系统不仅能够捕获用户-项目的交互信息,而且能够捕获丰富的用户/项目关系,从而做出更准确的推荐。值得注意的是,KG中的节点(例如,人或电影)可能具有不同的邻域大小(即相邻节点的数量),并且它们之间的关系也变化丰富,这使得使用KG进行推荐更具挑战性。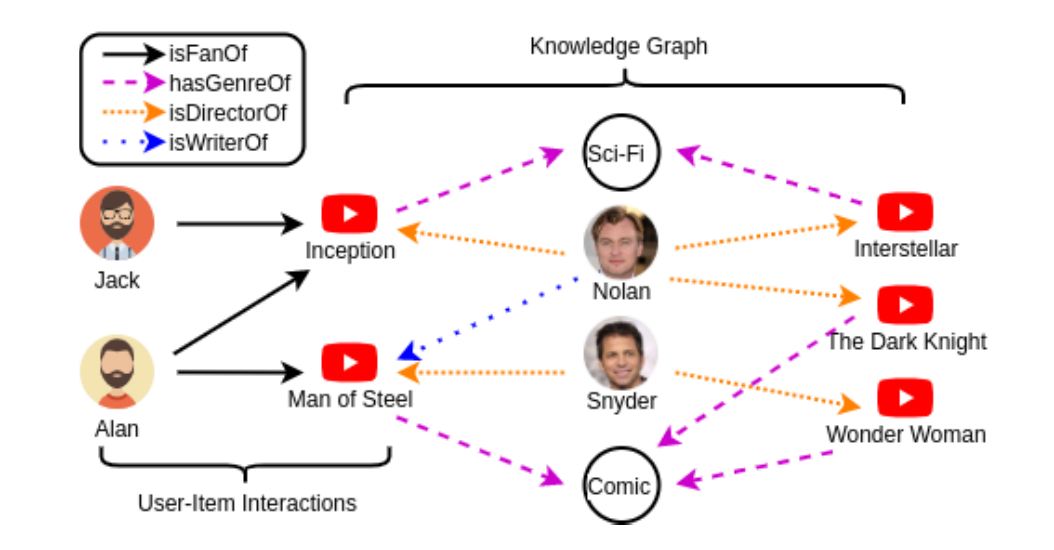
图1**
【图神经网络】
近年来,图结构数据的深度学习方法得到了越来越多的关注。如CNN、RNN和AE等深度学习算法,在过去的几年里,以处理图形数据的复杂性,一种新的神经网络结构正在迅速发展。这些类型的网络被称为图神经网络(GNNs),GNNs是知识感知深度推荐系统有效改进推荐表现的重要因素。关于图神经网络和知识图谱分析这两个主题,已有许多综述。Wu等概述了图神经网络在数据挖掘和机器学习领域的应用。虽然这是对GNNs的第一次全面回顾,但本次调查主要集中在网络体系结构上,仅简要介绍了应用GNNs进行推荐的可能性。另一方面,Shi等利用传统的知识图分析方法总结了推荐系统,但它忽略了基于GNN算法的最新发展。据我们所知,我们的调查是对最先进的深度推荐系统的首次回顾,这些系统利用GNNs从知识图中提取信息,以改进推荐。
【本文工作贡献】
我们的贡献:本文的主要贡献总结如下:
- 新分类法:知识感知深度推荐系统的核心组件是图嵌入模块(Graph Embedding module),它通常是GNN中的soft框架。GNN的每一层都由两个基本组件组成:聚合器(Aggregator )和更新器(Updater)。我们将论文中的聚合器分为三类:非关系感知聚合器(raltion-unaware aggregators)、关系感知子图聚合器(raltion-aware subgraph aggregators)和关系感知专用聚合器(raltion-aware attentive aggregators)。我们还将论文中的更新器分为三类,即仅上下文更新器 (content-only updater)、单交互更新器(single-interaction updater)和多交互更新器(multi-interaction updater)。
- 全面概述:我们提供了最全面的基于GNN的知识感知深度推荐(GNN-KADR)系统里soft方法的综述。本文对典型模型进行了详细的描述,并进行了必要的比较,讨论了它们对冷启动、可扩展性等实际推荐问题的解决方案。
- 资源收集:我们总结了有关GNN-KADR系统的资源,包括基准数据集、评估指标和开源代码。
- 未来方向:我们分析了现有研究的局限性,并提出了一些未来的研究方向,如动态性、可解释性、公平性等。
本文组织:其余部分安排如下。第2节定义了与基于GNN的知识感知的概念和本文中使用的相关符号。第3节概述了soft的GNN-KADR系统。第四节讨论了典型模型对实际推荐问题的解决方案。第5.1节概述了广泛使用的基准数据集、评估指标和开源代码。第六部分讨论了当前面临的挑战,并提出了未来的研究方向。第七节总结全文。
2 Preliminary And Notation
首先,让我们考虑一个电子商务网站上的一个典型场景:Jack是一个喜欢穿蓝色牛仔裤的客户,有一天他曾询问过“牛仔裤”。从返回的项目列表中,杰克点击了一些有吸引力的项目以获取详细信息。在这一周,他还去了一些网店,查看T恤。最后,在星期天,杰克从他最喜欢的品牌买了一件蓝色牛仔裤作为生日礼物,并在同一家商店的购物车里又添了一件T恤衫。根据Jack的行为,该平台收集了丰富的信息(提交查询词、点击物品、访问过的店铺、性价比优先级和品牌),以便向他推荐未来可能感兴趣的商品。这种推荐场景也可以在其他网站上看到。一般来说,多种对象和历史用户行为构成一个知识图。图2显示了电子商务网站上的一个玩具示例。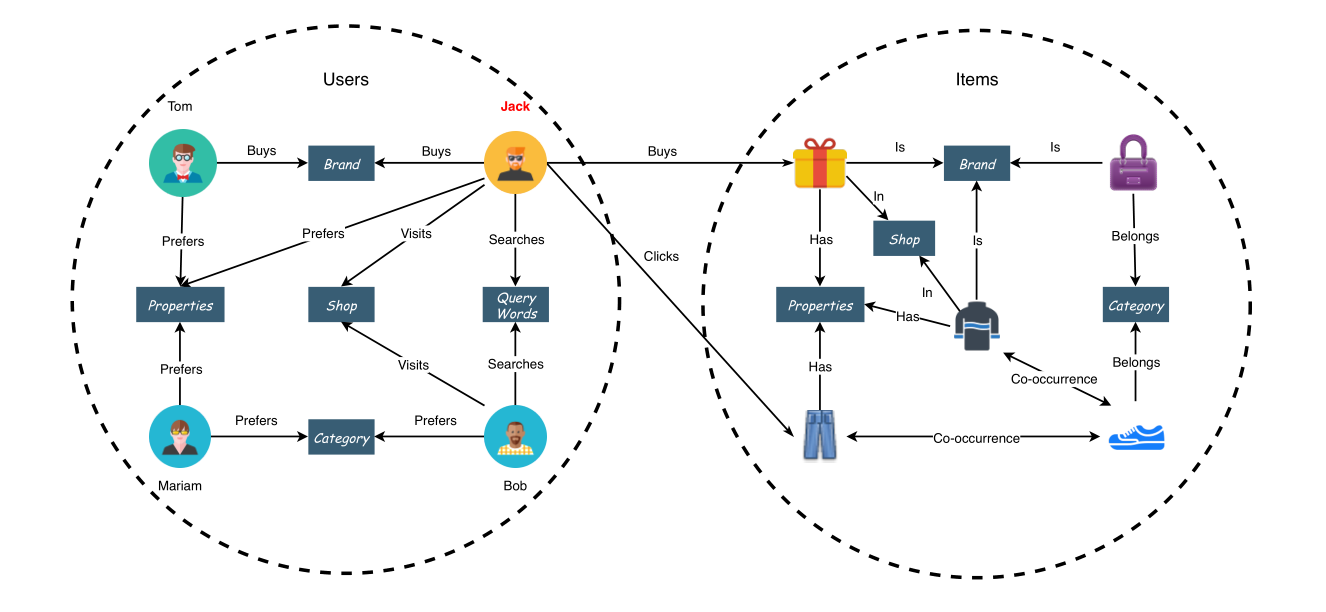
图2
定义2.1.Konwledge Graph (知识图谱)定义为有向图![2 [综述]Deep Learning on Knowledge Graph for Recommender System: A Survey - 图4](/uploads/projects/armor-novr7@work/add89c74b79ecae93f11933a8b11ccf8.svg) ,其中V是结点集合,E⊆V×V是结点集合V中各结点的边的集合。G与节点型映射函数ψ:V→a和边型映射函数ψ:E→R相关联,其中| a |>1和/或| R |>1。每个节点v∈V属于节点类型中的一个特定节点类型。
,其中V是结点集合,E⊆V×V是结点集合V中各结点的边的集合。G与节点型映射函数ψ:V→a和边型映射函数ψ:E→R相关联,其中| a |>1和/或| R |>1。每个节点v∈V属于节点类型中的一个特定节点类型。
集合A:ψ(v)∈A,每条边e∈e属于关系型集合R:ψ(e)∈R中的特定关系类型。挖掘知识图通常是基于一个基本的实体-关系-实体三元组(u,e,v),其中u∈v,e∈e,v∈v表示这个三元组的头、关系和尾部。为了简单起见,本文将这些实体-关系-实体三元组称为知识三元组。在这里,节点u和v的类型可以相同,也可以不同,这取决于上下文。
定义2.2.Neihborhood 邻域![2 [综述]Deep Learning on Knowledge Graph for Recommender System: A Survey - 图5](/uploads/projects/armor-novr7@work/b1598dd246aada583ed1539177c2c891.svg) 。给定知识图G=(V,E),对于节点V,其邻域N(V)定义为直接连接到V的节点集,即{w |(w,E,u)或(u,E,w),E∈E}。
。给定知识图G=(V,E),对于节点V,其邻域N(V)定义为直接连接到V的节点集,即{w |(w,E,u)或(u,E,w),E∈E}。
定义2.3.r-r-Neihborhood 邻域![2 [综述]Deep Learning on Knowledge Graph for Recommender System: A Survey - 图6](/uploads/projects/armor-novr7@work/6af1141ee5a3f790c88b8d1562ea7bf9.svg) 。给定一个知识图G=(V,E),对于节点V,其r-邻域nR(V)定义为与V相连的具有r型边的节点集,即{w |(w,E,u)或(u,E,w),其中E∈E,ψ(E)=r}。
。给定一个知识图G=(V,E),对于节点V,其r-邻域nR(V)定义为与V相连的具有r型边的节点集,即{w |(w,E,u)或(u,E,w),其中E∈E,ψ(E)=r}。
用户-项目推荐,一般来说,V可以进一步写成![2 [综述]Deep Learning on Knowledge Graph for Recommender System: A Survey - 图7](/uploads/projects/armor-novr7@work/72ab7bd43fc483a2b23e42b3224d2d39.svg) 。在推荐中,我们将v1表示为用户节点集,v2表示为项节点集,其中v3。,V n表示其他对象的节点(品牌、属性等)。我们还表示E=E label∪E unlabel,其中E label⊆v1×v2表示用户和项节点之间的一组边,E unlabel=E\E label表示其他边。由于现实世界中一个典型的推荐设置是根据用户的历史行为来预测用户的偏好项目,因此我们使用G=(V,E)来表示由历史数据构建的图,而G P=(vp,ep)来表示真实的未来图。因此,用户项推荐问题可以表述为基于历史数据构造的图上的链接预测问题:
。在推荐中,我们将v1表示为用户节点集,v2表示为项节点集,其中v3。,V n表示其他对象的节点(品牌、属性等)。我们还表示E=E label∪E unlabel,其中E label⊆v1×v2表示用户和项节点之间的一组边,E unlabel=E\E label表示其他边。由于现实世界中一个典型的推荐设置是根据用户的历史行为来预测用户的偏好项目,因此我们使用G=(V,E)来表示由历史数据构建的图,而G P=(vp,ep)来表示真实的未来图。因此,用户项推荐问题可以表述为基于历史数据构造的图上的链接预测问题:
输入:a KG G=(V,E)。
输出:一个预测的边缘集eb-ep标签,它是gp上真实边缘集ep标签的预测。
在本文中,粗体大写字符用于表示矩阵,粗体小写字符用于表示向量。除非特别说明,本文中使用的符号如表1所示。
表1
3 Categorization And Frameworks
基于GNN的知识感知深度推荐器(GNN-KADR)系统的一般工作流程如图3所示。GNN-KADR的图形嵌入模块首先学习为每个图节点(包括用户和项目节点)生成一个嵌入,对输入的知识图谱的信息进行编码。接下来,对于给定的用户,排名模块根据其对应的嵌入量计算该用户和每个候选项之间的匹配分数。那些匹配分数前N(或匹配分数高于用户指定阈值)的项目将链接(推荐)到此用户。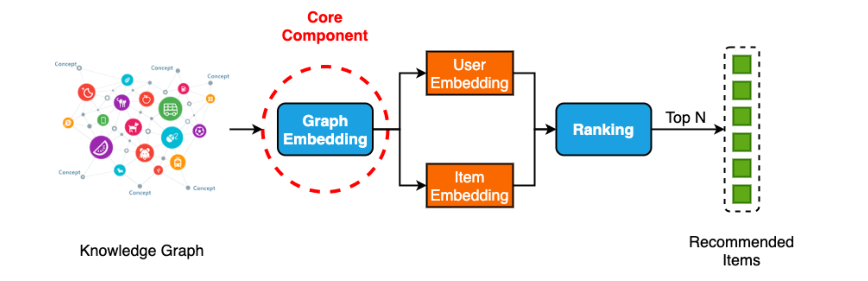
图3
在这个过程中,系统的核心部分是图形嵌入模块,它通常是最先进框架中(soft)的一个图神经网络(GNN)。GNN的每一层都由两个基本组件组成:聚合器和更新器。对于节点v,聚合器从v的邻域聚合特征信息以产生上下文表示。更新程序然后利用这个上下文表示以及其他输入信息来获得node v的新嵌入。堆叠K个不同的GNN层或重用相同的GNN层K次,可以将GNN的接受域扩展到K跳图邻域。
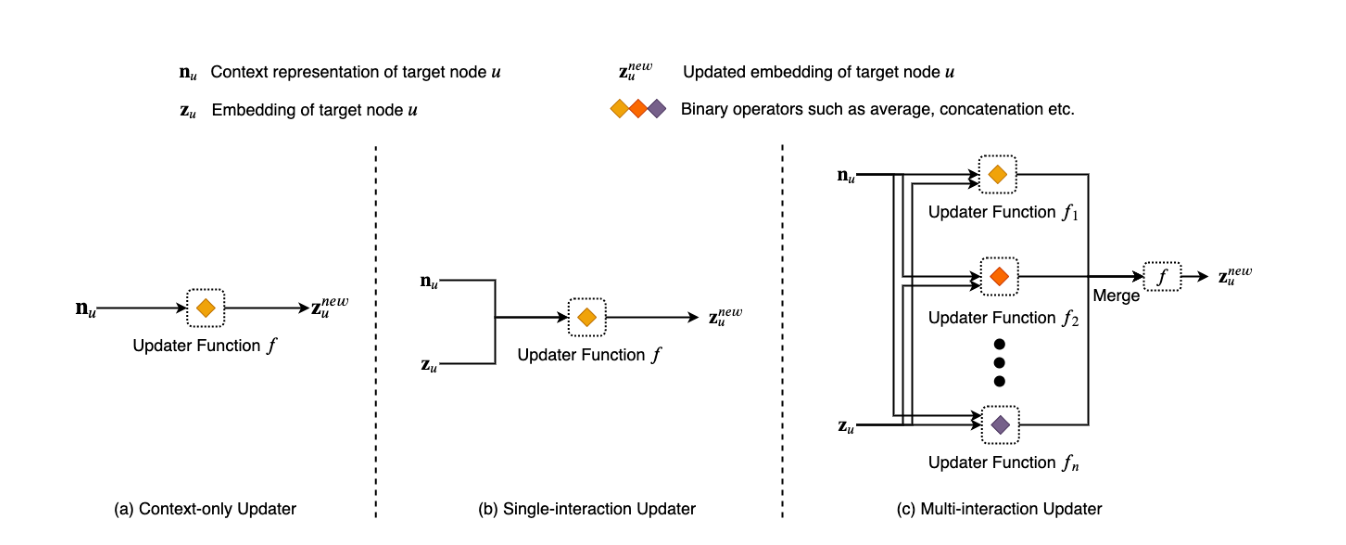
我们将GNNs的聚合器分为非关系感知聚合器、关系感知子图聚合器和关系感知关注聚合器。另一方面,我们将更新程序分为三类,即仅上下文更新器、单交互更新器和多交互更新器。图4和图5分别描述了聚合器和更新器的各种类别。下面,我们将详细讨论它们。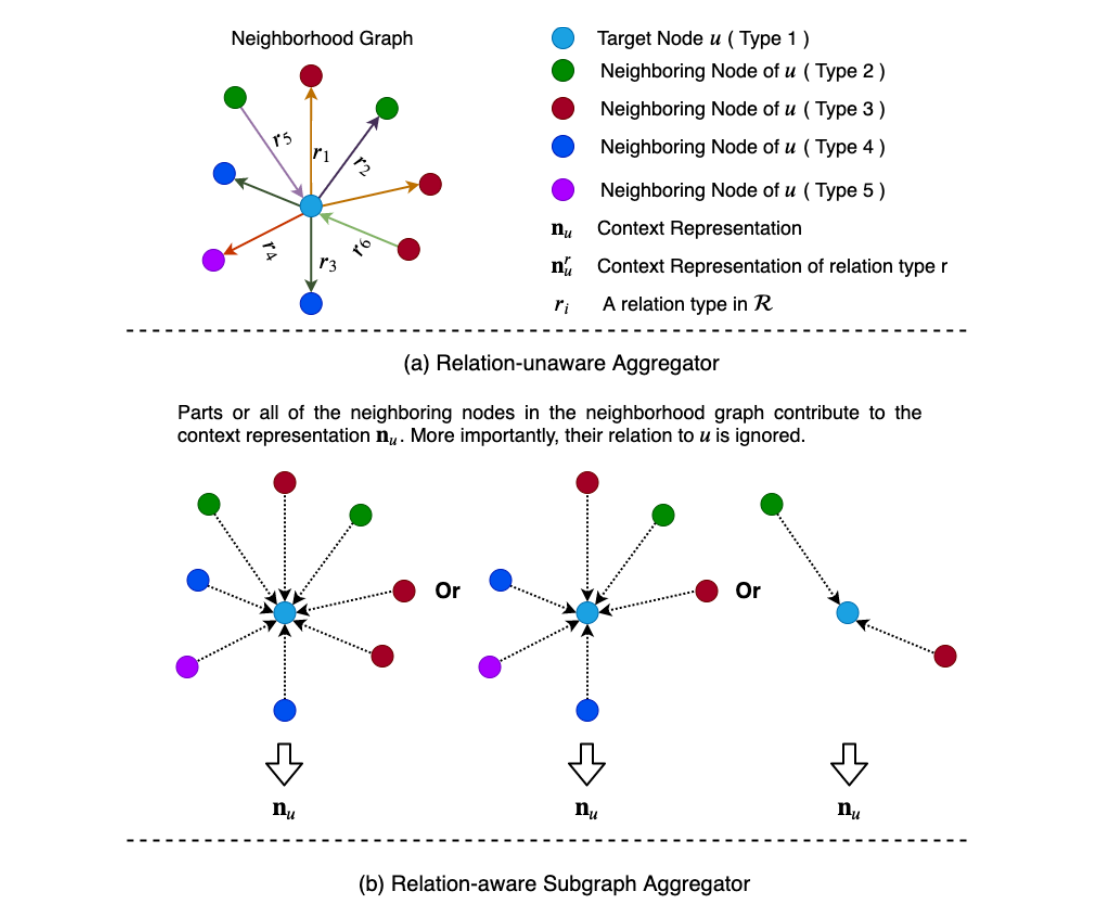
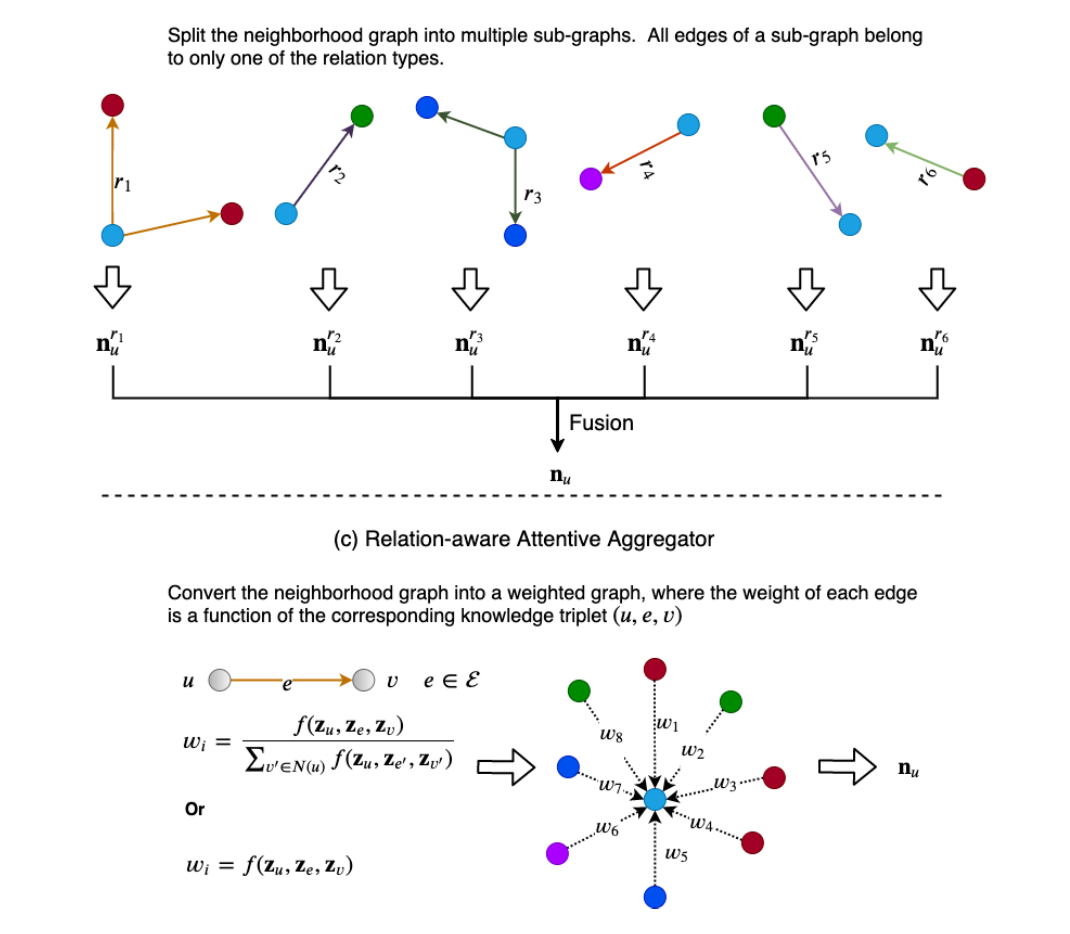
图4
3.1 Aggregator
3.1.1 Relation-unaware Aggregator
对于一个目标节点u,一个不依赖关系的聚合器旨在从u的部分或全部相邻节点聚集信息以产生上下文表示。然而,在这个过程中,目标节点u与任意节点之间的关系r=ψ(e)(e=eu,v或ev,u) 相邻节点v被忽略,因此其信息不在上下文表示nu中编码。
Fab【4】提出MEIRec。
3.1.2 Relation-aware Subgraph Aggregator
3.1.3 Relation-aware Attentive Aggregator
3.1.4 Discussion
3.2 Updater
3.2.1 Context-only Updater
3.2.2 Single-interaction Updater
3.2.3 Multi-interaction Updater
3.2.4 Discussion

4 Solution To Practical Recommendation Issues
在本节中,我们将讨论由最新的框架提出的解决方案,以解决诸如可扩展性、数据稀疏性等实际建议问题。
4.1 Cold Start
冷启动问题,即如何对新用户或新项目进行适当的推荐,是实际推荐系统中一个令人生畏的难题。一方面,新用户和新项目在真实场景下的应用程序中占比很大,比如YouTube。另一方面,推荐的性能在很大程度上依赖于足够数量的历史用户-项目交互数据,而对于新的用户/项目,推荐性能会显著降低。
Uniform Term Embedding (统一术语嵌入)。Fan等人提出的MEIRec是一个意向推荐框架,它根据用户的点击历史向用户推荐最相关的意向(即查询)。作者发现,项目的查询和标题都是由术语组成的,而且术语的数量并不多。因此他们建议用少量的术语嵌入来表示查询/标题。它大大减少了模型中训练参数的数目。以前从未搜索/添加过的新查询/项目也可以用这些术语表示。
Masked Embedding Training with Encoder-Decoder Architecture(采用编解码结构的掩蔽嵌入训练)。STAR-GCN[45]采用多块图编解码结构(multi-block graph encoder-decoder architecture)。每个块包含两个组件:一个图形编码器和一个图形解码器。图编码器通过对语义图结构和输入内容特征进行编码生成节点表示,解码器的目的是恢复输入节点的嵌入。为了训练STAR-GCN,作者随机掩蔽(mask)一定百分比的输入节点,然后利用其上下文信息重构干净的节点嵌入。这被称为掩蔽嵌入训练机制(masked embedding training mechanism)。利用这种机制,STAR-GCN可以学习训练阶段未观察到的节点的嵌入情况。在冷启动情况下,STAR-GCN将新节点的嵌入量初始化为零,并通过多个GNN编解码块逐步细化估计的嵌入量。
4.2 Scalability
在大多数现有的图神经网络中,其聚合器必须访问一个节点的整个邻域来生成其节点嵌入,这对于大规模的知识图来说是一个计算困难的问题。接下来,我们将展示所研究的方法对这个可伸缩性问题提出的一些解决方案。
Important Node Sampling(重要节点取样)。PinSage定义了基于重要性的邻域,而不是检查k-hop图邻域来计算节点嵌入,其中节点u的邻域被定义为对节点u施加最大影响的T节点。具体来说,它模拟从u开始的随机游走,并计算随机游走访问节点的L1规范化访问计数。因此,u的邻域是标准化访问计数最高的T节点。
Meta-path Defined Receptive Field(元路径定义的接收野)。MEIRec[4]和RecoGCN[41]提出利用语义感知的元路径为每个节点划分出简洁而相关的接受域,即元路径定义的接受域。
定义4.1.Meta-path元路径。元路径ρ被定义为知识图中的路径,其形式为t1 r1–→t2r2–···rl–→tl+1,其中在节点类型t1和tl+1之间存在一个复合关系r=r1◦r2··◦rl。
定义4.2.Meta-path defined Receptive Field (MRF) 元路径定义的感受野(MRF)。给定一个知识图G=(V,E),对于节点V和长度为l的元路径ρ,元路径定义了接受野FρV=(fρv(0),fρv(1),···,fρv(l))定义为可以通过元路径ρ到达或从nodev经过的节点集,其中fρv(k)表示ρ上k个跳跃到达的节点集。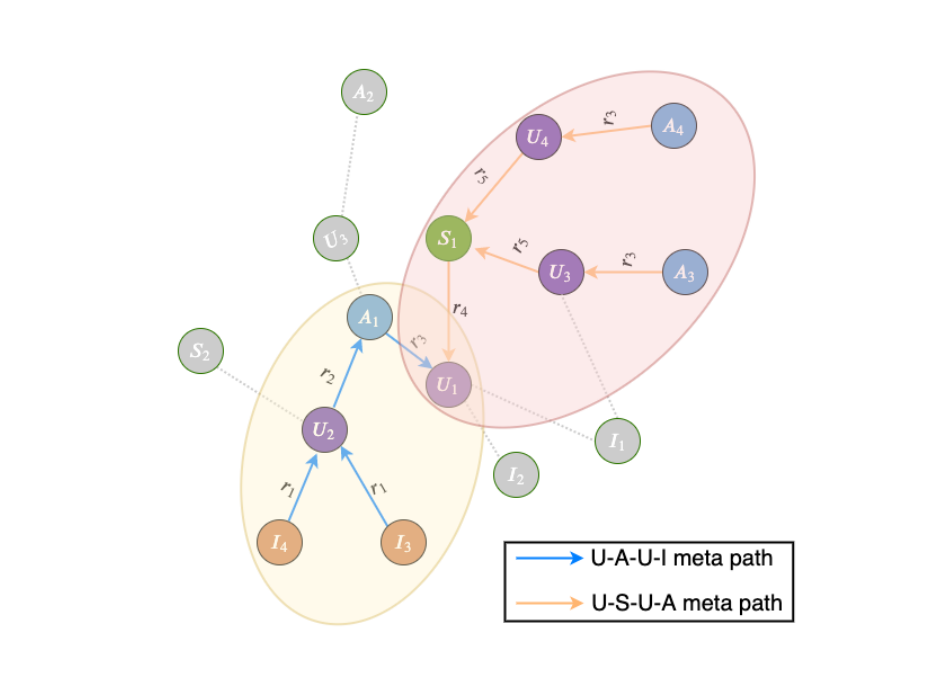
图6
图6显示了MRF的一个示例。与k-hop图邻域相比,MRF只关注基于先验知识选择的关系,并通过大大减少计算图中的节点数来加快训练速度。此外,可以通过计算沿着不同元路径的多个嵌入并将它们融合在一起以获得最终表示:公式(34)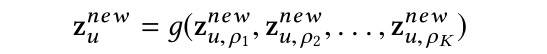
其中Д是一个融合函数。注意,这些嵌入的计算彼此独立,因此可以并行进行。
Meta-path defined Receptive Field (MRF) 矢量聚合器和更新器。为了克服大规模图聚类小图训练的局限性,IntentGC[46]引入了一种特殊的图神经网络,它用矢量聚合器和矢量更新器代替GNNs中的常规聚合器和更新器。其核心思想是用多个小矩阵积的和来代替一个巨大的权重矩阵和一个巨大的特征向量(由多个向量串联而成)之间昂贵的矩阵乘法,从而避免不必要的特征交互。具体配方见表3。
表3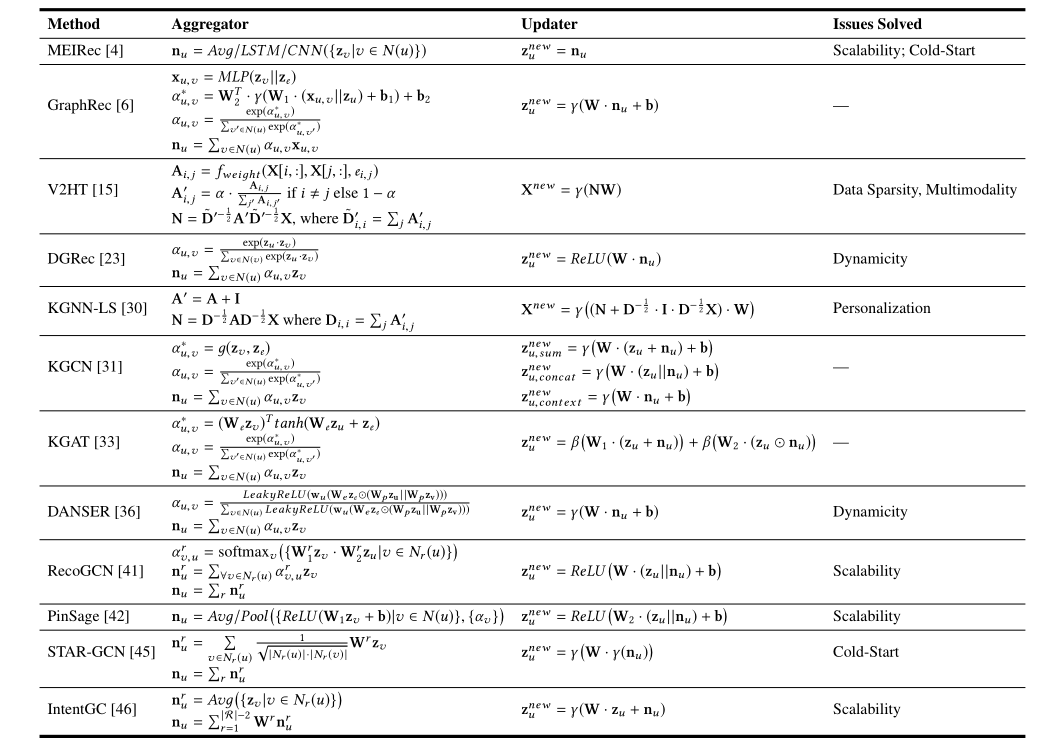
4.3 Personalization
Graph Translation图转换。KGNN-LS[30]通过将知识图谱转换为用户特定的加权图来进行个性化推荐,在该图上应用图神经网络计算个性化项目嵌入量。在这个新的图上,边的权重由一个可训练函数![2 [综述]Deep Learning on Knowledge Graph for Recommender System: A Survey - 图17](/uploads/projects/armor-novr7@work/cea92ed9a4457978d70f8a615290999e.svg) 计算,该函数的作用是给定用户识别重要的知识图谱关系。我们把这种技术称为图转换。
计算,该函数的作用是给定用户识别重要的知识图谱关系。我们把这种技术称为图转换。
4.4 Dynamicity
知识图谱可以随时间动态演化,即其节点/边可能出现或消失。例如,在社交推荐的场景中,用户的朋友列表可能会不时更改。当用户添加多个兴趣相似的新朋友时,推荐系统应相应地更新推荐策略,并将这种变化反映在推荐结果中。为了解决这个问题,Wu等人[23]考虑动态特征图设置。具体地说,对于每个用户,它们构建一个图,其中每个节点表示该用户或他/她的一个朋友。如果用户u有| N(u)|个朋友,则此图中的节点总数为| N(u)+1 |。在这个图中,朋友的节点特征保持不变,但是用户u的节点特征在u消费一个新项目时更新。此外,为了捕捉上下文相关的社会影响,作者提出了一种图-注意神经网络,它利用一种注意机制来引导其聚合器中的影响力传播。用户u的每个朋友都被分配了一个注意力权重,用来衡量其影响力的大小。
5 Datasets ,Codes And Evaluations
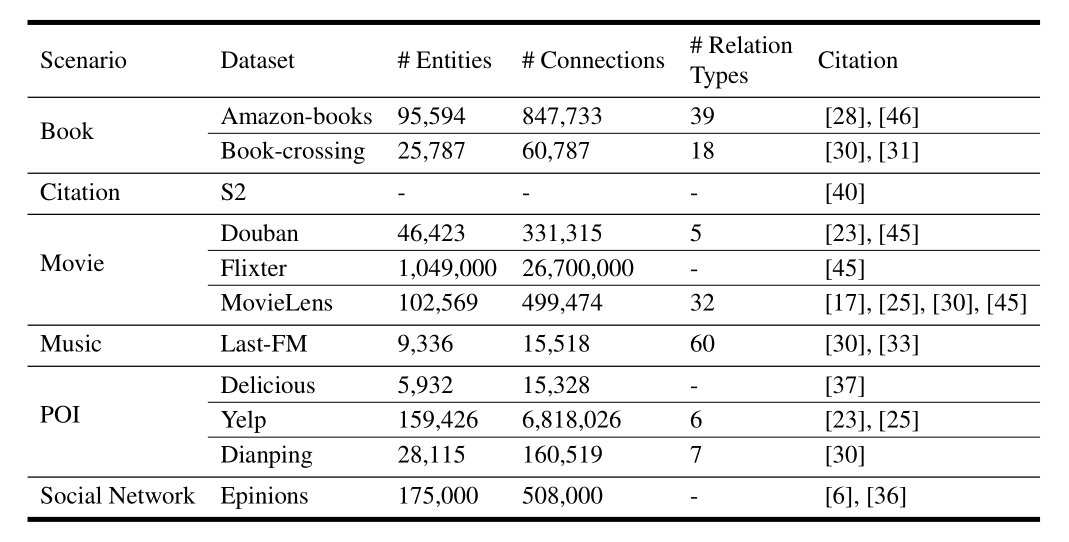
5.1 Datesets 数据集
5.2 Evaluations 评价准则

6 Future Directions
GNN-KADR是一个年轻和有潜力的研究领域,下面给出一些未来研究方向的建议
6.1 Scalability Trade-Off 可扩展性的权衡
现有GNN-KADR系统的可扩展性是以牺牲知识图谱完整性为代价的。通过采样固定数量的相邻节点,一个节点可能会失去其有影响力的邻居。通过用元路径定义接受域,模型感知到的知识图谱可以被剥夺一些重要的语义信息。此外,选择和加权元路径需要大量的先验知识,对于某些实际应用来说可能很困难。如何在可伸缩性和知识图谱完整性之间取得平衡是一个有趣的研究方向。
6.2 Dynamicity 动态性
知识图谱本质上是动态的,节点和边可能会出现或消失,节点/边的输入可能会随时间变化[38]。此外,在真实场景中,KG中节点之间的关系类型也可能随时间而变化。例如,在agent初始化的社交电子商务中,用户可能在将来某一天成为其朋友的销售代理。虽然Wu等人[23]提出的DGRec已经部分地解决了图的动态性,但是很少有GNN-KADR系统考虑将其框架适应知识图包含动态空间和语义关系的情况。需要新的聚合器和更新器来适应知识图的动态性。根据我们的文献调查,我们认为这仍然是一个有待进一步研究的领域。
6.3 Explainability of Recommendation 推荐系统的可解释性
与传统的基于内容或协作过滤的推荐系统相比,可解释性对于GNN-KADR系统尤为重要,因为非专家用户无法直观地确定知识图中的相关上下文,例如,在识别社交网络中有影响力的用户时,这些用户是很好的销售对象社会电子商务的代理人。此外,向用户作出可解释的预测,使他们能够了解网络推荐背后的因素(即,为什么推荐此项/服务?[19,39]),有助于赢得用户对系统的信任。这也有助于实践者通过概率权重和激活来了解更多关于模型的信息[26]。
现有的研究主要集中在GNNs的可解释性上。Ying等人提出的GNNEXPLAINER[43]是一种模型不可知论的方法,它为任何基于GNN的模型的预测提供了可解释的解释。给出一个实例,它标识了一个紧凑的子图结构和一小部分节点特征,它们在GNN–a´z预测中起着关键作用。Pope等人[18]将三种常见的解释方法,即基于梯度的显著性映射[21]、类激活映射(CAM)[44]和激励反向传播(EB)[44]从CNN扩展到GNNs,以识别计算的重要方面。然而,这些方法都是针对齐次图设计的,没有考虑知识图的异构性。
另一方面,其他一些方法,如kpn[35]、EIUM[10]、RuleRec[16],试图利用知识图形来获取信息来源纳布勒建议。但是这些方法通常从知识图中抽取路径,并通过RNN等非GNN算法从中提取信息。因此,与GNNs相比,知识图的拓扑和语义结构在这些情况下被破坏,导致性能不理想。
就我们所知,如何建立一个可解释的基于GNN的知识感知的深度推荐系统仍然是一个开放的问题,目前的文献中还没有对此进行探索。我们相信这是下一个前沿。
6.4 Fairness of Recommendation 推荐系统的公正性
如今,推荐系统被广泛应用于影响人们生活的各个领域。这引发了人们对这种制度可能加剧的偏见和歧视的担忧。一个典型的例子是新闻推荐,带有偏见立场的文章可能会影响人们的投票决定。推荐系统有两种固有的偏差[7]:观测偏差和来自不平衡数据的偏差。观察偏差的存在是由于反馈回路导致模型只学习预测与先前建议相似的建议。相比之下,当由于社会、历史或其他环境偏差而存在系统偏差时,就会导致数据不平衡。这种偏差在数据中是隐含的,因此推荐系统通常不知道它们。
建立公平推荐系统的方法很多。Alex等人[2]引入了一种成对推荐公平性度量来评估推荐系统中算法的公平性,并提出了一种新的正则化器来鼓励在模型训练过程中改进该度量。Sahin等人[9]提出了补充措施来量化与受保护属性相关的偏差,并提出了一种计算公平感知结果重新排序的算法。具体地说,他们的算法寻求在一个或多个受保护属性方面实现排名靠前的结果的期望分布。Jurek等人[14]提出量化推荐系统的后处理模块引起的用户不公平或歧视,其初衷是提高推荐的多样性。
然而,这些算法主要是为传统的推荐系统设计的,不能直接用于GNN-KADR系统,因为它们没有考虑知识图引入的任何信息或偏差。因此,建立一个公平的GNN-KADR系统是一个很有前途但尚未开发的领域,预计会有更多的研究。
6.5 Cross-Domain Recommendation 跨领域推荐
除了挖掘单个知识图外,还需要使用来自多个来源的数据来计算建议。例如,一个客户可能同时是多个社交网络的用户,例如Facebook和LinkedIn。每一个社交网络都收集关于这个客户的数据,并将它们嵌入到自己的知识图表中。因此,利用所有这些知识图中的信息来提高推荐性能是合理的。
然而,目前的研究还存在两个显著的差距。第一个差距是现有的研究缺乏有效整合来自多个知识图形源的信息的探索[12]。他们中的大多数试图通过连接相关实体(即节点)来在两个不同的知识图之间建立关联,如Wang等人[34]。这些方法忽略了由相同类型的节点或边的集合表示的组知识,这些知识对于对齐多个知识图至关重要。
其次,大多数现有的工作提供基于传统技术的跨域推荐,如协同过滤(CF)。其他一些研究使用谱聚类算法从不同领域的图中聚集知识,但是强烈假设所有的图都应该同时可用[8]。在利用全球导航网络进行跨域建议方面,所做的努力有限。我们相信这是一个很有前途的研究领域,因为GNNs比谱聚类算法性能更好[13]。
7 Conclusion
本文对GNN-KADR(GNN-based Knowledge Aware Deep Recommender)进行了全面的综述,并针根据现存soft方法中的聚合器(Aggregator )和更新器(Updater)进行分类:
- 聚类器(Aggregators)
- 非关系感知聚合器(raltion-unaware aggregators)
- 关系感知子图聚合器(raltion-aware subgraph aggregators)
- 关系感知专用聚合器(raltion-aware attentive aggregators)
- 校正器(Updater)
- 仅上下文校正器 (content-only updater)
- 单交互校正器(single-interaction updater)
- 多交互校正器(multi-interaction updater)
其次,还重点描述了这些框架如何缓解推荐系统的冷启动问题和可扩展性问题。
同时,还整合GNN-KADRR相关的数据集、开源代码和基准数据集。
最后,对该领域的发展方向给出建议。

若有收获,就点个赞吧
0 人点赞
