主要内容:使用selenium和bs4对中文突发事件新闻进行定时自动爬取
代码主体:EventExtractor、ChinaEmergencyNewsExtractor、save_results、contentExtractor
EventExtractor
使用该类控制爬虫获取网页信息和处理网页信息
1.__init__(self)中配置一些默认参数:
options.add_experimental_option("prefs", {"profile.managed_default_content_settings.images": 2}):关闭浏览器的图片,提高网页响应效率chrome_options.add_argument('--headless'):隐藏弹出的浏览器webdriver.Chrome():这里使用Google浏览器驱动url:爬取主页urlhtml:存放爬取的html数据save_dir:保存爬取文件目录
# 爬取器class EventExtractor():def __init__(self):options = webdriver.ChromeOptions()options.add_experimental_option("prefs", {"profile.managed_default_content_settings.images": 2})chrome_options = Options()chrome_options.add_argument('--headless')self.browser = webdriver.Chrome("chromedriver.exe", options=options,chrome_options=chrome_options)self.url = 'http://www.12379.cn/html/gzaq/fmytplz/index.shtml'self.html = Noneself.save_dir = './chinaEmergency/chinaEEP.xlsx'# 登录def login(self):self.browser.get(self.url)WebDriverWait(self.browser, 1000).until(EC.presence_of_element_located((By.CLASS_NAME, 'main')))# 获取当前网页资源def get_html(self):self.html = self.browser.page_source# 跳转下一页def next_page(self,verbose=False):try:submit_page = self.browser.find_element(by=By.XPATH,value=r"//*[@class='next']") # find_element_by_xpath(r"//*[@class='next']")submit_page.click()WebDriverWait(self.browser, 1000).until(EC.presence_of_element_located((By.CLASS_NAME, 'main')))curr_page = self.browser.find_element(by=By.XPATH,value=r"//*[@class='avter']")if verbose and curr_page != 0:print(int(curr_page) - 1)except:print("页面挑战异常结束")# 网页处理函数def ProcessHTML(self, verbose=False, withDuplicates=True):"""html:html格式的输入verbose:控制爬取可视化打印的标志位,0表示不显示,1表示html打印,2表示详细打印,默认为1函数输入:html函数输出:具有新闻信息的pandas表格"""duplicates_flag = Falseif not os.path.exists(self.save_dir):names = ['title', 'content', 'public_time', 'urls']history = pd.DataFrame([], columns=names)history.to_excel(self.save_dir, index=False)print("首次运行 爬取时间:{}".format(time.strftime('%Y.%m.%d', time.localtime(time.time()))))else:history = pd.read_excel(self.save_dir)history_key = history["public_time"].sort_values(ascending=False).values[0]print("历史爬取节点:{} 爬取时间:{}".format(history_key,time.strftime('%Y.%m.%d',time.localtime(time.time()))))soup = BeautifulSoup(self.html)tbody = soup.find("div", attrs={"class": "list_content"})for idx, tr in enumerate(tbody.find_all("li")):# 设置随机睡眠,防止封IPif random.randint(1, 2) == 2:time.sleep(random.randint(3, 6))a = tr.find("a")title = a.texthref = "http://www.12379.cn" + a["href"]content = contentExtractor(href)public_time = tr.find("span").textresults = [title, content, public_time, href]if verbose:print([public_time, title, content, href])# 查重if withDuplicates and public_time in history["public_time"].values and title in history["title"].values:duplicates_flag = Trueprint("监测到重复爬取,已停止后续爬取行为")breakelse:save_results(results)# 查重return duplicates_flag# 关闭driverdef close(self):self.browser.close()
2.
login(self):访问网址,until中是等待延时,只有检测到有
3.get_html(self):获取当前页面html数据
4.next_page:页面跳转
5.ProcessHTML(self, verbose=False, withDuplicates=True):数据处理首次运行会创建一个新的excel文件,已有历史文件会根据最近发布日期进行去重爬取,当检测到标题和时间都存在则停止爬取。
- 对每一条信息的爬取设置了sleep时间,以免对服务器造成负担
- 其他信息爬取比较简单不详细讲解了
对于正文内容的抽取,另外启动一个selenium进行爬取(注意一些链接已经失效,404会直接返回正文为”无”),代码如下:
# 正文抽取函数def contentExtractor(url):"""函数输入:url函数输出:输出当前url下的新闻正文内容,若没有新闻内容则输出"无""""# 先检测是否404user_agent = {'User-Agent': 'Mozilla/5.0.html (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.html.2171.71 Safari/537.36'}r = requests.get(url, headers=user_agent, allow_redirects=False)if r.status_code == 404:return "无"else:# 没有404,则抽取网页正文内容chrome_options = Options()chrome_options.add_argument('--headless')driver = webdriver.Chrome("chromedriver.exe", chrome_options=chrome_options)driver.get(url)WebDriverWait(driver, 1000).until(EC.presence_of_element_located((By.CLASS_NAME, 'content_text')))respond = driver.page_sourcedriver.quit()soup = BeautifulSoup(respond)text = soup.find("div", attrs={"class": "content_text"}).textreturn text
如果没有检测到重复则会调用
save_results(results)写入当前数据,代码如下:def save_results(results):results_path = './chinaEmergency/chinaEEP.xlsx'names = ['title', 'content', 'public_time', 'urls']results = {k: v for k, v in zip(names, results)}if not os.path.exists(results_path):df1 = pd.DataFrame([], columns=names)df1.to_excel(results_path, index=False)else:df1 = pd.read_excel(results_path)new = pd.DataFrame(results, index=[1])df1 = df1.append(new, ignore_index=True)df1.sort_values(by="public_time", ascending=True, inplace=True)df1.reset_index(drop=True, inplace=True)df1.to_excel(results_path, index=False)
ChinaEmergencyNewsExtractor
通过该函数完成翻页爬虫
Event = EventExtractor()创建之前写好的爬取器Event.login()登录爬取网站
通过for循环遍历输入的页码,页码可自有输入Event.get_html()获取当前页面HTML数据Event.ProcessHTML(verbose=True)处理HTML数据并保存到指定Excel文件中,返回一个是否重复爬取的布尔值。重复则停止翻页,不重复则使用Event.next_page()翻页。Event.close()关闭selenium浏览器# 可控制的事件抽取器def ChinaEmergencyNewsExtractor(page_nums=3,verbose=1):Event = EventExtractor()Event.login()for i in range(0, page_nums):Event.get_html()page_break = Event.ProcessHTML(verbose=True)if page_break:breakEvent.next_page()# 关闭driver,防止后台进程残留Event.close()
自动爬取和主函数
自动爬取采用的非常简单的
定时爬取策略,采用retry库可以快速完成定时任务,主体代码如下:# 定时抽取@retry(tries=30,delay=60*60*24)def retry_data():ChinaEmergencyNewsExtractor(page_nums=3, verbose=1)raise
使用
raise触发异常,让retry库重启函数
tries:表示重启次数,这里设置了30次
delay:表示延迟重启的时间,以秒为单位,代码中60*60*24就是延迟一天
即每个24小时爬取一次网页内容,共计爬取30次,完成一个月的数据自动获取
主函数:
# 主函数if __name__ == '__main__':retry_data()
效果展示
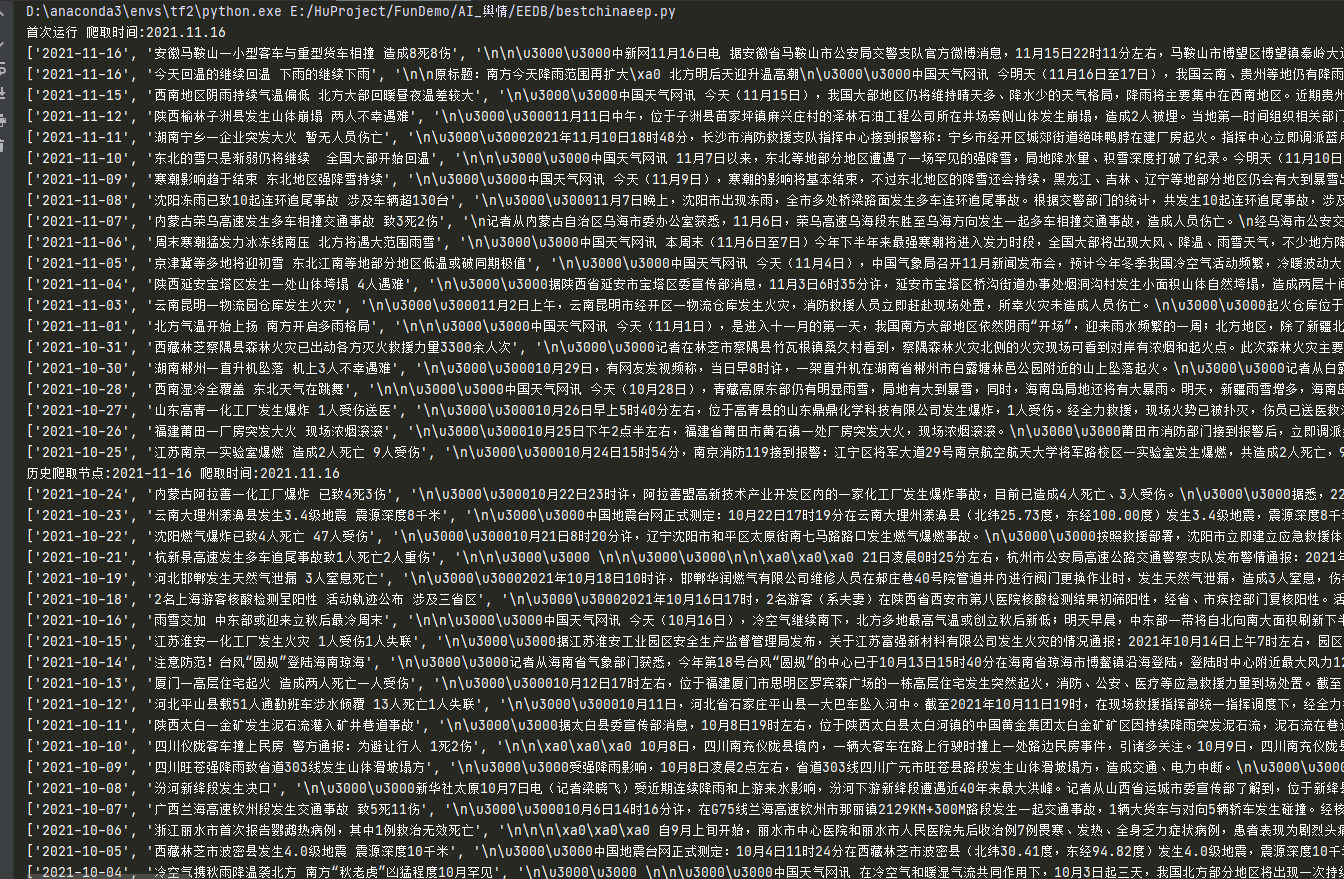
图1 挂机爬取界面
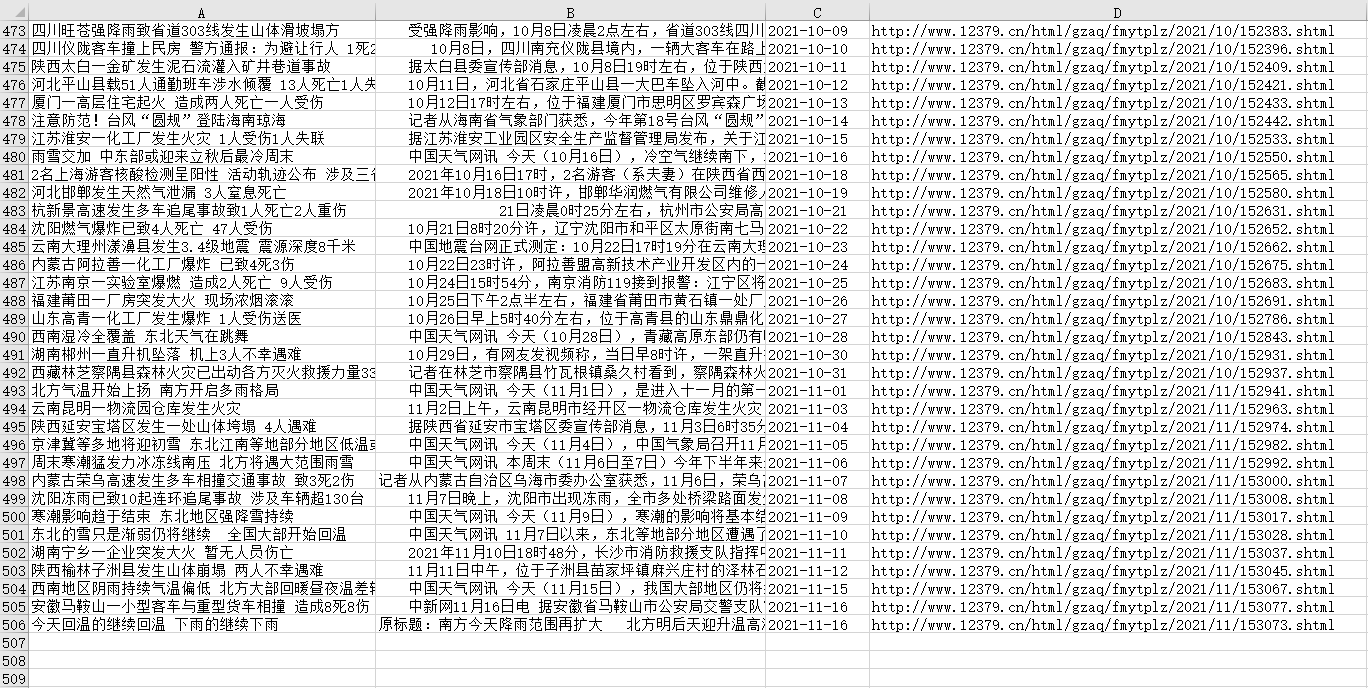
图2 爬取文件
至此突发事件舆情新闻的自动爬取实例展示完成,数据挖掘与分析萌新,才疏学浅,有错误或者不完善的地方,请批评指正!!

若有收获,就点个赞吧
0 人点赞
