optuna是一个为机器学习,深度学习特别设计的自动超参数优化框架,具有脚本语言特性的用户API。因此,optuna的代码具有高度的模块特性,并且用户可以根据自己的希望动态构造超参数的搜索空间。另外,optuna也是kaggle比赛中十分热门的调参神器,在优秀方案中频繁出现。告别暴力的GridSearch调参。
项目地址:https://github.com/optuna/optuna
框架特点
- 小巧轻量,通用且与平台无关
- python形式的超参数空间搜索
- 高效的优化算法
- 写法简单,可以并行
- 快速可视化
安装
Optuna 支持 Python 3.6 即以上版本
pip 安装 Optuna
conda 安装 Optunapip install optuna
conda install -c conda-forge optuna
示例
通常,基于树的模型的超参数可以分为 3步进行调参:
1.树结构调整
max_depth:树深度,如果不控制树的深度容易过拟合,一般设置为3-8。
num_leaves:叶子结点个数,树模型为二叉树所以numleaves最大不应该超过_2^(maxdepth)。
min_data_in_leaf:最小叶子节点数量,如果设置为50,那么数量到达50则树停止生长,所以这个值的大小和过拟合有关,其大小也和num_leaves有关,一般数据集体量越大设置的越大。
2.准确性调整
learning_rate:学习率
n_estimators:树的数量
这两个参数是经常调整的参数,一般需要去寻找n_estimators和learning_rate的最佳组合。
max_bin:这个参数也可以来提高准确率,但也存在过拟合风险。
3.过拟合调整
lambda_l1:L1正则
lambda_l2:L2正则
正则对过拟合有影响,比较难调,一般搜索范围设置在(0,100)。
min_gain_to_split:分裂的最小增益,当计算增益不高时就不会继续分裂。
bagging_fraction:训练每棵树的训练样本百分比,让每棵树好而不同。
feature_fraction:每棵树时要采样的特征百分比,让每颗子树特征具有差异化,抵抗过拟合。
optuna将优化程序极简为三个简单步骤:目标函数(objective),单次试验(trial),和研究(study).
目标函数
import numpy as npimport pandas as pdfrom sklearn.metrics import accuracy_score,f1_scorefrom sklearn.model_selection import StratifiedKFoldimport lightgbm as lgbmdef objective(trial, data, target):X_train, X_test, y_train, y_test=train_test_split(data, target, train_size=0.3)# 数据集划分# 参数网格param_grid = {"n_estimators": trial.suggest_categorical("n_estimators", [10000]),"learning_rate": trial.suggest_float("learning_rate", 0.01, 0.3),"num_leaves": trial.suggest_int("num_leaves", 20, 3000, step=20),"max_depth": trial.suggest_int("max_depth", 3, 12),"min_data_in_leaf": trial.suggest_int("min_data_in_leaf", 200, 10000, step=100),"lambda_l1": trial.suggest_int("lambda_l1", 0, 100, step=5),"lambda_l2": trial.suggest_int("lambda_l2", 0, 100, step=5),"min_gain_to_split": trial.suggest_float("min_gain_to_split", 0, 15),"bagging_fraction": trial.suggest_float("bagging_fraction", 0.2, 0.95, step=0.1),"bagging_freq": trial.suggest_categorical("bagging_freq", [1]),"feature_fraction": trial.suggest_float("feature_fraction", 0.2, 0.95, step=0.1),"random_state": 2021,}model = lgbm.LGBMClassifier(objective="gbdt", **param_grid)model.fit(X_train,y_train,eval_set=[(X_test, y_test)],eval_metric="multi_logloss",early_stopping_rounds=100,verbose=False)pred_lgb = model.predict(X_test)scores = f1_score(y_true=y_test, y_pred=pred_lgb,average='macro')return scores
单词试验 和 研究:
n_trials=50train = pd.read_csv("train.csv")X,y = train.drop(["id","label"],axis=1),train["label"]study = optuna.create_study(direction="maximize", study_name="LGBM Classifier") # minimizestudy.optimize(func, n_trials=n_trials)
打印最佳参数:
print(f"\tBest value (f1): {study.best_value:.5f}")print(f"\tBest params:")for key, value in study.best_params.items():print(f"\t\t{key}: {value}")
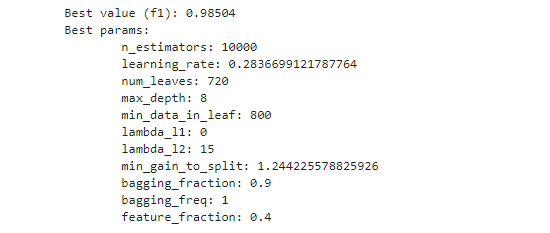
可视化
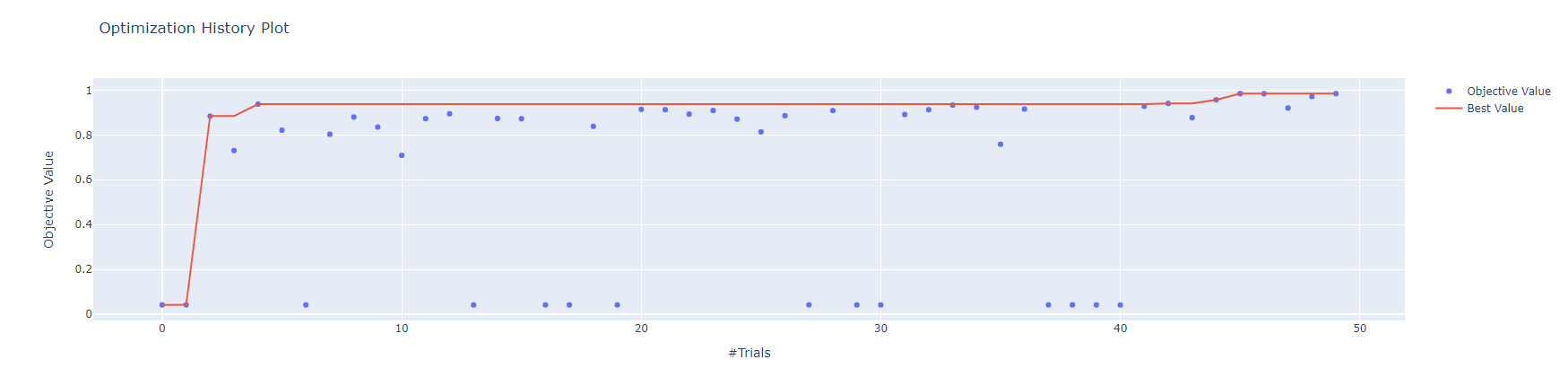
optuna.visualization.plot_optimization_history(study)
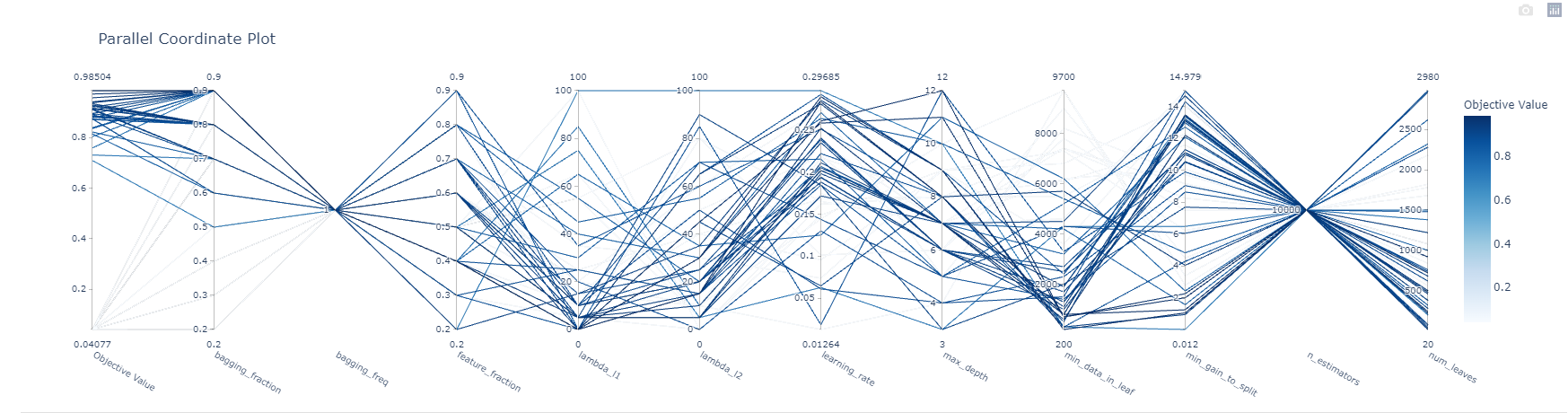
optuna.visualization.plot_parallel_coordinate(study)
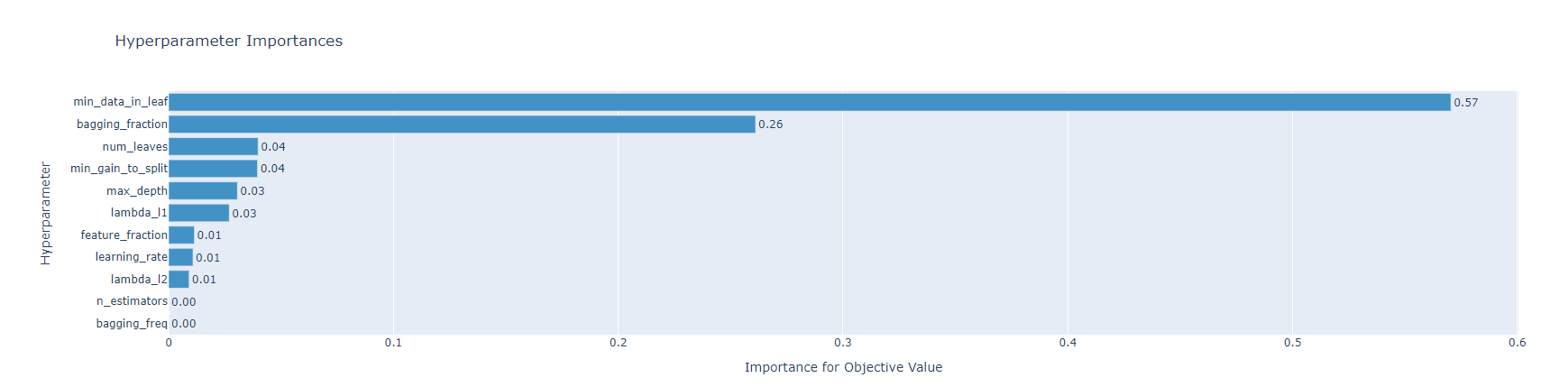
optuna.visualization.plot_param_importances(study)

若有收获,就点个赞吧
0 人点赞
