第二章 前深度学习时代 - 推荐系统的进化之路
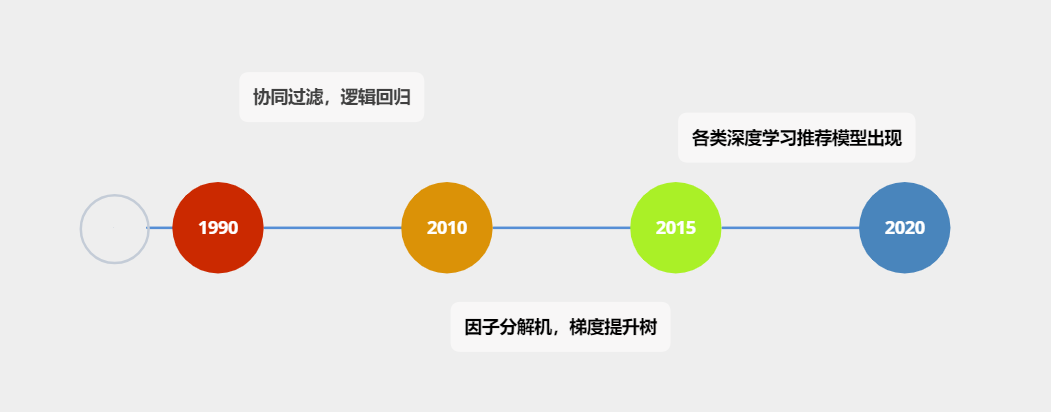
图1 推荐系统模型演化时间轴
推荐系统的发展及其迅速,从2020年之前千篇一律的协同过滤(Collaboration Filtering,CF),逻辑回归(Logistic Regression,LR),进化到因子分解机(Factorization Machine ,FM),梯度提升树(Gradient Boosting Decision Tree,GBDT),再到2015年之后深度学习推荐系统模型的百花齐放,各种模型架构层出不穷。推荐系统的主流模型经历了从单一模型到组合模型,从经典框架到深度学习的发展过程。
诚然,深度学习推荐模型已经成为主流,但在学习它之前,回顾前深度学习时代的老前辈们仍然是非常重要的。
即使在深度学习空前流行的今天。协同过滤,逻辑回归,因子分解机等传统推荐模型仍然凭借其可解释性强,硬件环境要求低,易于快速训练和部署等不可替代的优势,拥有大量适用的应用场景。模型无优劣贵贱之分,熟悉每种模型的优缺点,能够灵活应用和改进不同的算法模型是优秀工程师应该具备的素质。
传统推荐系统模型是深度学习推荐模型的基础。构成神经网络的神经元和是传统逻辑回归的另一种表现形式。基于因子分解支持的神经网络(FNN),深度因子分解机(DeepFM),神经网络因子分解机(NFM)等深度学习模型更是与传统FM模型有千丝万缕的联系。此外在传统推荐系统的梯度下降等训练方法更是沿用至深度学习时代。
1. 推荐系统模型的演化关系图
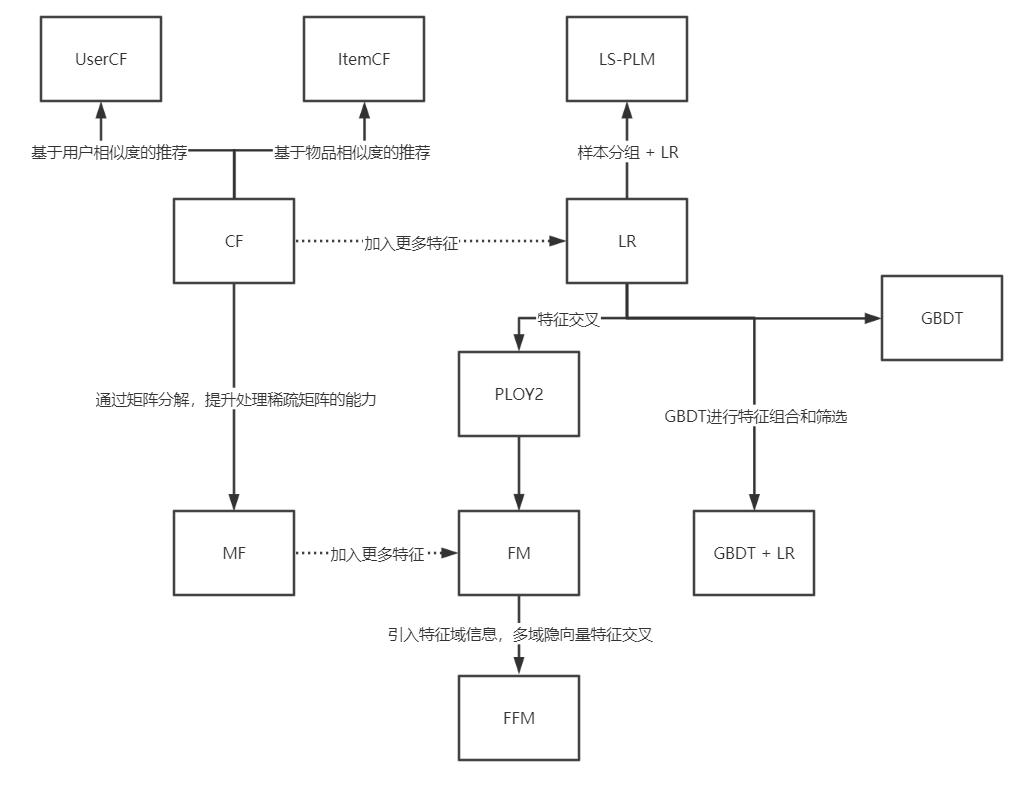
图2 推荐系统模型的演化关系图
1.协同过滤算法族
协同过滤式曾经首选模型之一,从物品相似度和用户相似度角度出发,协同过滤衍生出物品协同过滤(ItemCF)和用户协同过滤(UserCF)两种算法。为了使协同过滤能够更好的处理稀疏共现矩阵的问题,增强模型的泛化能力,从协同过滤衍生出矩阵分解模型(MF)并发展处矩阵分解的各分支模型。
2.逻辑回归模型族
与协同过滤仅利用用户和物品之间的显式或隐式反馈信息相比,逻辑回归能够利用和融合更多用户,物品和上下文特征。从LR模型衍生出的模型同样“枝繁叶茂”,包括增强了非线性能力的大规模分片线性模型(LS-PLM),由逻辑回归发展出来的FM模型,以及多种不同模型配合使用后的组合模型,等。
3.因子分解机模型族
因子分解机在传统的逻辑回归的基础上,加入了二阶部分,使模型具备了进行特征组合的能力。更进一步,在FM的基础上发展出的感知因子分解机(FFM)通过加入特征域的概念,进一步增强了因子分解机的特征交叉能力。
4.组合模型
为了融合多个模型的优点,将不同模型组合使用时构建推荐模型常用的方法。Facebook提出GBDT+LR组合模型是在业界影响力比较大的组合方式。此外,组合模型还体现出特征工程模型化的思想,也成为了深度学习推荐模型的引子和核心思想之一。
2. 协同过滤 - 经典的推荐算法
2003年 Amazon发表论文 Amazon.com Recommendations: Item-to-item collaborative filtering,这不仅让Amazon的推荐系统广为人知,也让协同过滤称为今后很长时间的研究热点和业界主流模型。
1. 什么是协同过滤?
协同过滤利用的是集体的智慧,顾名思义就是协同大家的反馈,评价和意见一起对海量的信息进行过滤,从中筛选出目标用户可能感兴趣的信息的推荐过程。
插入 例子 . . .
2. 用户相似度
在协同过滤的过程中,用户相似度计算是算法中最关键的一步。若共现矩阵的行向量代表用户向量,则计算用户i和用户j的相似度问题,就是计算用户向量i和用户向量j之间的相似度,两个向量之间常用的相似度计算方法如下几种:
1.余弦相似度:余弦相似度,衡量了用户i和用户j之间的向量夹角大小。显然,夹角越小,证明预先相似度越大,两个用户越相似。

2.皮尔逊相关系数:相比余弦相似度,皮尔逊相关系数通过使用用户平均分对各独立评分进行修正,减小了用户评分偏置的影响。

3.基于皮尔逊系数的思路,引入物品平均分的方式,减少物品评分偏置对结果的影响。

在相似度计算过程中,在理论上,任何合理的“向量相似度定义方式”都可以作为相似度用户计算的标准。
传统协同过滤的改进工作就是通过改进相似度定义来改进协同过滤的缺点。
3. 最终结果的排序
在获得TopN相似用户之后,利用TopN用户生成最终推荐结果的过程如下,假设“目标用户与其相似用户的喜好是相似的”,课根据相似用户已有的评价目标用户的偏好进行预测。
这里最常用的方式是利用用户相似度和相似用户的评价的加权平均获得目标用户的评价预测。

 是用户u和用户s的相似度,
是用户u和用户s的相似度, 是用户s对物品p的评分。
是用户s对物品p的评分。
在获得用户u对不同物品的评价预测后,最终的推荐列表根据预测得分进行排序即可得到。至此协同过滤的全部推荐过程完成。
缺点:
- 用户数往往远大于物品数,UserCF需要维护用户相似度矩阵以便快速找出TopN相似用户。用户相似度矩阵存储成本极高,随着业务发展,用户数增长会导致用户相似度矩阵的空间复杂度以n 的速度快速增长。
- 用户的历史数据向量往往往往非常稀疏。
4. ItemCF
由于UserCF的两大缺点,无论是Amazon,Netfilx都没有选取UserCF算法,而采用了ItemCF算法实现其最初的系统。
具体来讲,ItemCF是基于物品相似度进行推荐的协同过滤算法,通过计算共现矩阵中物品列向量的相似度得到物品之间的相似矩阵,再找到用户的历史正反馈物品的相似品进行进一步排序和推荐,ItemCF的具体步骤如下
. . . . . .待补充 5步法
最终相似度公式

其中,H是目标用户的正反馈物品合集 , 是物品p与物品h的物品相似度,
是物品p与物品h的物品相似度, 是用户u对物品h的已有评分。
是用户u对物品h的已有评分。
5. UserCF 和 ItemCF 的应用场景
| UserCF | ItemCF |
|---|---|
| 兴趣变化导向 | 兴趣稳定导向 |
| 更强的社交特性 | 视频推荐,商品推荐 |
| 非常适合新闻推荐场景 | 风格类型相似的稳定推荐场景 |
6. 协同过滤的下一步发展
协同过滤的优点:
- 非常直观,可解释性强
协同过滤的优点:
- 不具备较强的泛化能力
- 另一个缺点就是,仅利用用户和物品的交互信息,无法有效引入用户年龄,性别,商品分类,描述等一系列用户特征,商品特征,上下文特征。
什么是泛化能力?泛化能力不强会带来什么问题?
协同过滤无法将两个物品相似这一信息推广到其他物品的相似性计算上。这就导致一个非常严重的问题 —— 热门的物品具有很强的头部效应,容易与大量物品产生相似性,而尾部的物品由于特征向量稀疏,很少与其他物品产生相似性,导致很少被推荐。
为了解决这一问题,同时增加模型的泛化能力,矩阵分解技术被提出来。
该方法在基于协同过滤的共现矩阵的基础上,使用更稠密的隐向量表示用户和物品,挖掘用户和物品的隐含兴趣和隐含特征,在一定程度上弥补了协同过滤模型处理稀疏矩阵能力不足的问题。
如何引入用户特征,商品特征,上下文特征?
为了可以在推荐模型中引入这些特征向量,推荐系统逐渐发展成为以逻辑回归为核心的,能够综合不同类型特征的机器学习模型的道路上。
3. 矩阵分解算法 - 协同过滤的进化
2006年,Netfile 举办的推荐算法竞赛 Netfile Prize Challenge中,以矩阵分解为主的推荐算法大放异彩,拉开了矩阵分解在业界流行的序幕。
1. 矩阵分解的原理
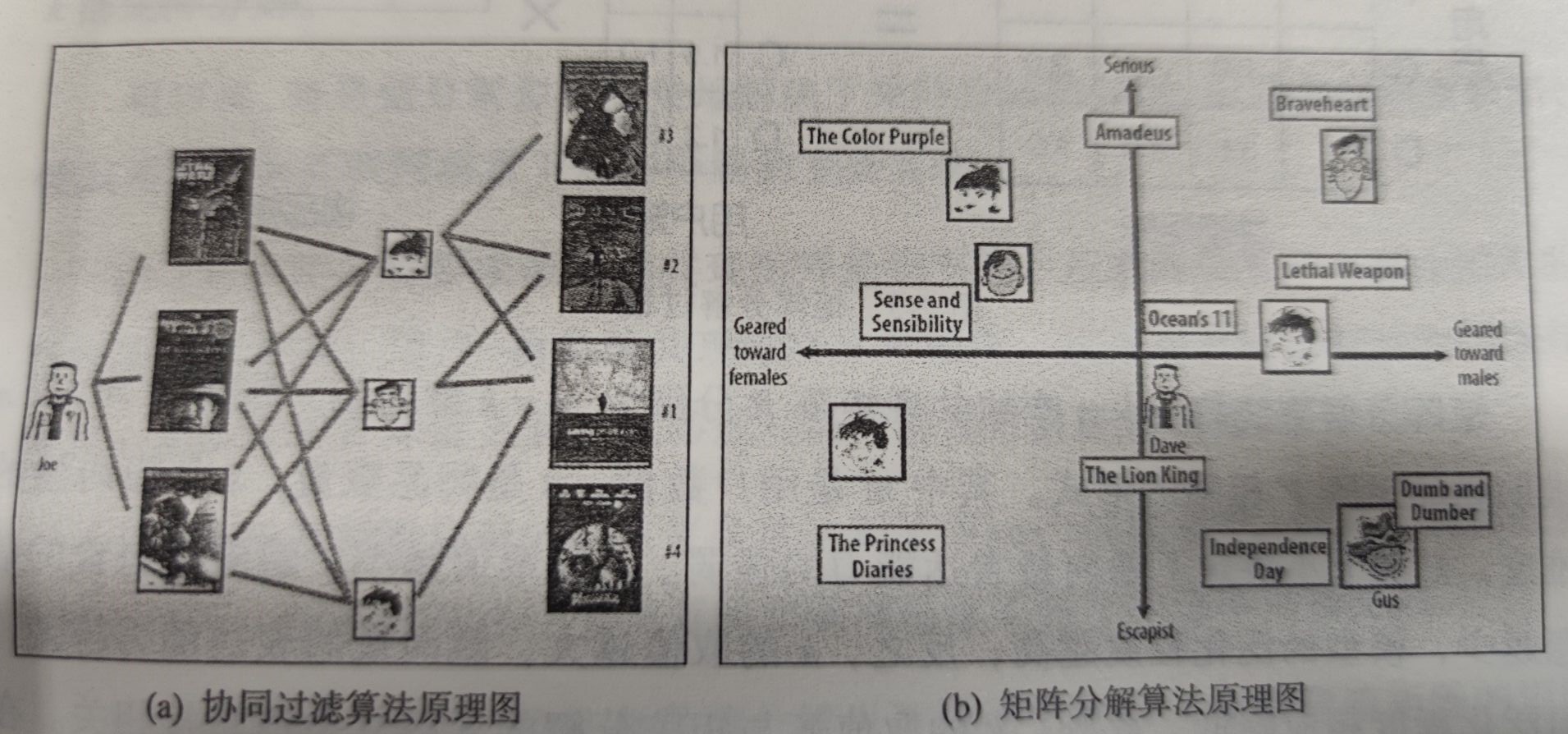
a.协同过滤原理图 b.矩阵分解原理图
矩阵分解算法期望为每一个用户和视频生成一个隐向量,将用户和视频定位到隐向量的表示空间上,距离相近的用户和视频表明兴趣特点接近,在推荐过程中,就应该把距离相近的视频推荐给目标用户。
用隐向量表达用户和物品,还要保证相似的用户及用户可能喜欢的物品的距离相近。
那么如何得到这样的隐向量呢?
在“矩阵分解”的算法框架下,用户和物品的隐向量是通过分解协同过滤生成的共现矩阵得到,这也是矩阵分解名字的由来。
上图是矩阵分解的过程。
矩阵分解算法将m x n维的共现矩阵R分解为m x k维的用户矩阵U和k x n维的物品矩阵V相乘的形式。其中m是用户数量,n是物品数量,k是隐向量的维度。
k的大小决定了隐向量表达能力的强弱。k的取值越小,隐向量包含的信息越少,模型的泛化程度越高;反之,k的取值越大,隐向量的表达能力越强,但其泛化程度相应降低。
此外,k的取值还与矩阵分解复杂度直接相关。在具体的应用中,k的取值要经过多次试验找到一个推荐效果和工程开销的平衡点。
基于用户矩阵U和物品矩阵V,用户u对物品i的预估评分如:

 是用户u在用户矩阵U中对应的行向量,
是用户u在用户矩阵U中对应的行向量, 物品i在物品矩阵V中对应的列向量。
物品i在物品矩阵V中对应的列向量。
2. 矩阵分解的求解过程
对矩阵分解主要有三种方法:
- 特征值分解(Eigen Decomposition)
- 奇异值分解(Singular Value Decomposition)
- 梯度下降(Grandient Descent)
其中,特征值分解只能作用于方阵,显然不适合用于分解用户-物品矩阵。
奇异值分解的具体描述:假设矩阵M是一个m x n的矩阵,则一定存在一个分解  ,其中U是m x m 是正交矩阵,V是n x n的正交矩阵,
,其中U是m x m 是正交矩阵,V是n x n的正交矩阵, 是m x n的对角阵。
是m x n的对角阵。
取对角阵 中较大的k个元素作为隐含特征,删除 的其他维度及U和V中对应的维度,矩阵M被分解为
至此完成了隐向量维度为k的矩阵分解。
奇异值矩阵完美解决了矩阵分解问题,但仍然存在两点缺陷,使其不宜作为互联网场景下的矩阵分解的主要方法。
- 奇异值矩阵要求原始的矩阵必须是稠密的。互联网场景下大部分用户历史行为非常稀疏。
- 传统奇异值分解的计算复杂度达到了O(mn )的级别。对互联网海量的数据而言是不可接受的。
由于上述两个原因,传统奇异值分解也不适合解决大规模稀疏矩阵的矩阵分解问题,因此,梯度下降法成了进行矩阵分解的主要方法,下面具体介绍:

上述公式是矩阵分解的目标函数,该目标函数是让原始评分与用户向量和物品向量之积 的差尽量小,这样才能最大限度地保存贡献矩阵的原始信息。
的差尽量小,这样才能最大限度地保存贡献矩阵的原始信息。

其中K是所有用户评分样本的集合。为了减少过拟合现象加入正则化项的目标函数。
确定了目标函数后,就可以进行标准的梯度下降,更新隐向量。
3. 消除用户和物品打分的偏差
由于不同用户的打分体系不同(有的用户喜欢好评,有的用户觉得3分就是低分,而有的用户觉得1分才是低分),不同物品的衡量标准也有所区别(电子产品和日用品评分差异大)。
为了消除用户和物品打分的偏差(Bias),常用的做法是在矩阵分解时加入用户和物品的偏差向量。

对应的目标函数也需要改变:

同理,求导更新参数。加入用户和物品的的打分偏差之后,矩阵分解得到的隐向量更能反映不同用户对不同物品的“真实”态度差异,也更容易捕捉评价数据中有价值的信息,从而避免推荐结果的有偏见。
4. 矩阵分解的优点和局限性
| 优点 | 局限性 |
|---|---|
| 泛化能力强。一定程度上解决了数据稀疏问题 | 无法加入用户,物品,上下文特征 |
| 空间复杂度低。由n^2 级别降低到(m+n)*k级别 | |
| 更好的扩展性和灵活性。最终输出时隐向量,与embedding的思想不谋而合,非常方便和其他特征进行组合拼接,也便于和深度学习网络无缝衔接。 |
4. 逻辑回归 - 融合多种特征的推荐模型
1. 基于逻辑回归模型的推荐流程
2. 逻辑回归模型的数学形式
3. 逻辑回归模型的训练方法
4.逻辑回归模型的优势
在深度学习模型流行之前,逻辑回归模型曾在相当长一段时间是推荐系统和计算广告界的主要选择之一。
除了在形式上适合于融合不同的特征,形成教“全面”的推荐结果,其流行还有三方面的原因:
- 数学含义上的支撑
- 可解释性强
- 工程化的需要
5. 从FM到FFM - 自动特征交叉的解决方案
6. GBDT + LR - 特征工程模型化的开端
7. LS-PLM - 阿里巴巴曾经的主流推荐模型
8. 总结
参考文献
[1] 《深度学习推荐系统》王喆

若有收获,就点个赞吧
0 人点赞
