Hugging face是美国纽约的一家聊天机器人服务商,专注于NLP技术,其开源社区提供大量开源的预训练模型,尤其是在github上开源的预训练模型库transformers,目前star已经破50w。
官网链接在此:https://huggingface.co/
本文将使用pipelines提供的QuestionAnsweringPipelineAPI,通过问答的方式抽取句子中的信息,虽然抽取效果一般但代码量少抽取速度快,具体效果如下:
图1 MRC_Roberta模型抽取效果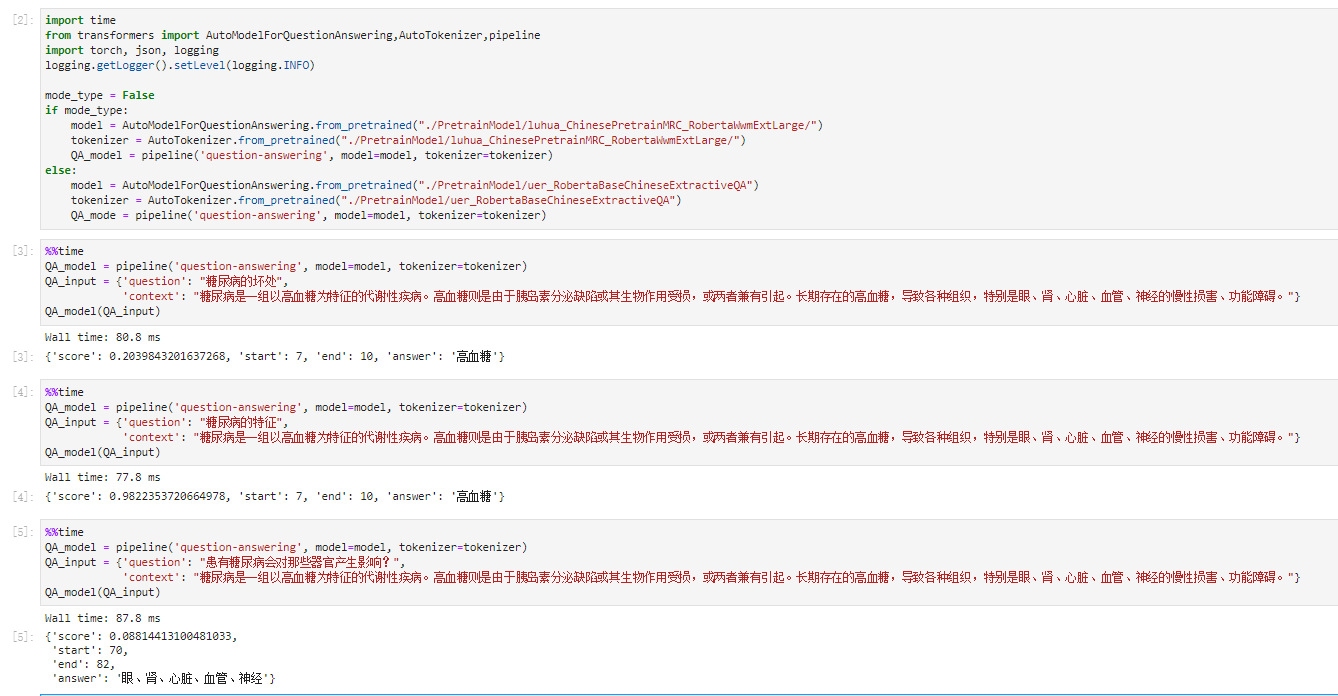
图2 QA_Roberta模型抽取效果
Pipelines
本文要简单介绍一下Hugging face的pipelines功能。pipelines是使用模型进行推理的一种很好且简单的方法。这些pipelines方法是一个封装了大量复杂代码的提供专用于多项任务的简单API,其中包括情感分析、命名实体识别、问答、文本生成、掩码语言模型、特征提取。
- AudioClassificationPipeline
- AutomaticSpeechRecognitionPipeline
- ConversationalPipeline
- FeatureExtractionPipeline
- FillMaskPipeline
- ImageClassificationPipeline
- ImageSegmentationPipeline
- ObjectDetectionPipeline
- QuestionAnsweringPipeline
- SummarizationPipeline
- TableQuestionAnsweringPipeline
- TextClassificationPipeline
- TextGenerationPipeline
- Text2TextGenerationPipeline
- TokenClassificationPipeline
- TranslationPipeline
- ZeroShotClassificationPipeline
Piepline官网文档在此:官方文档
使用示例请参阅 任务摘要。
实现流程
1.前往hugging face下载中文Bert、中文QA或者中文MRC模型,存放到指定目录下:
MRC_Roberta模型:https://huggingface.co/luhua/chinese_pretrain_mrc_roberta_wwm_ext_large
QA_Roberta模型:https://huggingface.co/uer/roberta-base-chinese-extractive-qa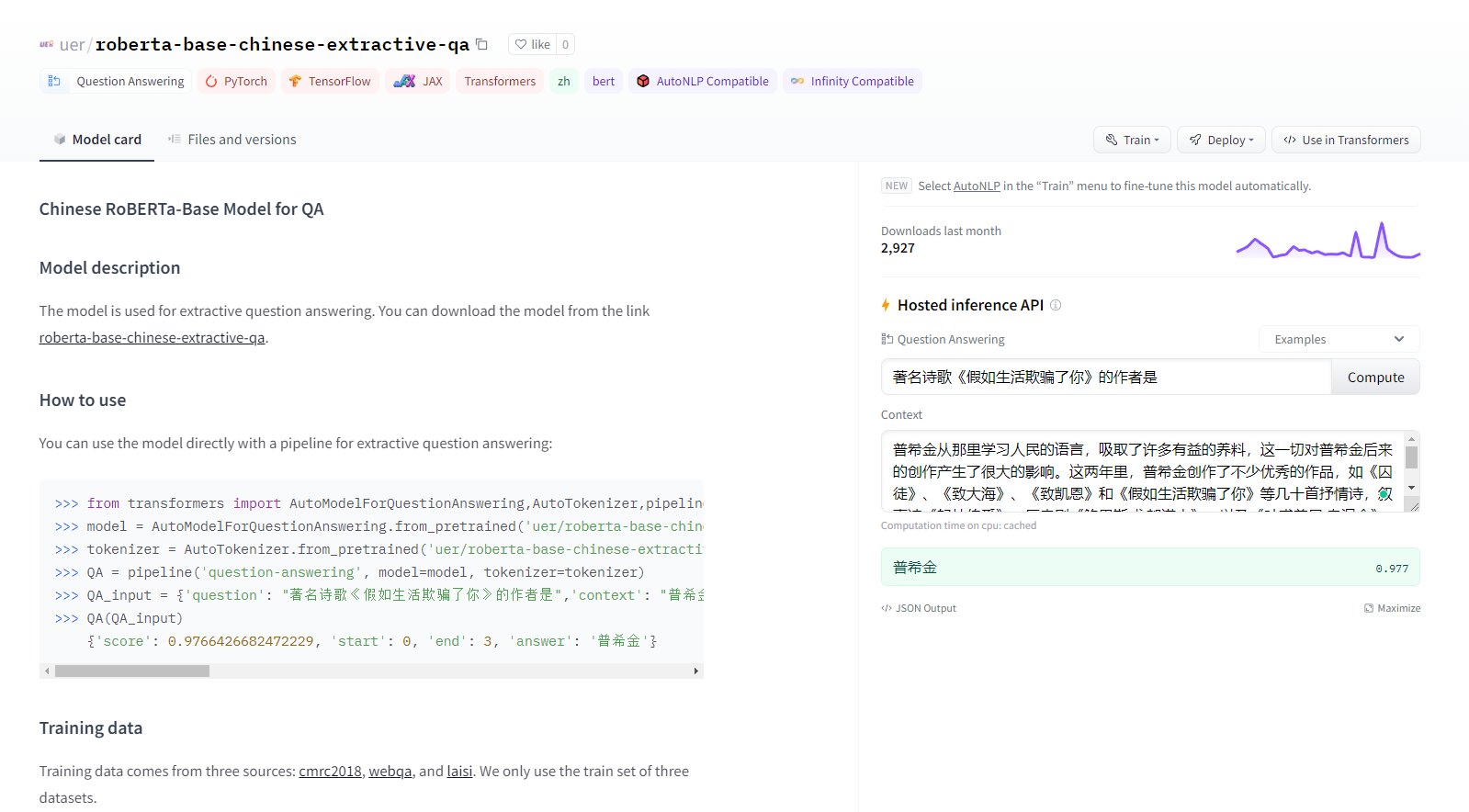
2.加载Tokenizer和model,具体使用哪种Tokenizer和model可以查询文档,本文使用的是 AutoModelForQuestionAnswering和AutoTokenizer
import timefrom transformers import AutoModelForQuestionAnswering,AutoTokenizer,pipelineimport torch, json, logginglogging.getLogger().setLevel(logging.INFO)model = AutoModelForQuestionAnswering.from_pretrained("./PretrainModel/luhua_ChinesePretrainMRC_RobertaWwmExtLarge/")tokenizer = AutoTokenizer.from_pretrained("./PretrainModel/luhua_ChinesePretrainMRC_RobertaWwmExtLarge/")QA_model = pipeline('question-answering', model=model, tokenizer=tokenizer)
3.创建pipline,按照格式输入问句和正文取得结果
%%timeQA_model2 = pipeline('question-answering', model=model, tokenizer=tokenizer)QA_input = {'question': "糖尿病的坏处",'context': "糖尿病是一组以高血糖为特征的代谢性疾病。高血糖则是由于胰岛素分泌缺陷或其生物作用受损,或两者兼有引起。长期存在的高血糖,导致各种组织,特别是眼、肾、心脏、血管、神经的慢性损害、功能障碍。"}QA_model(QA_input)"""Wall time: 305 ms{'score': 2.974448580062017e-05, 'start': 83, 'end': 92, 'answer': '慢性损害、功能障碍'}"""
只返回一个答案不过瘾呀,能不能返回多个?
- 只需要配置参数即可
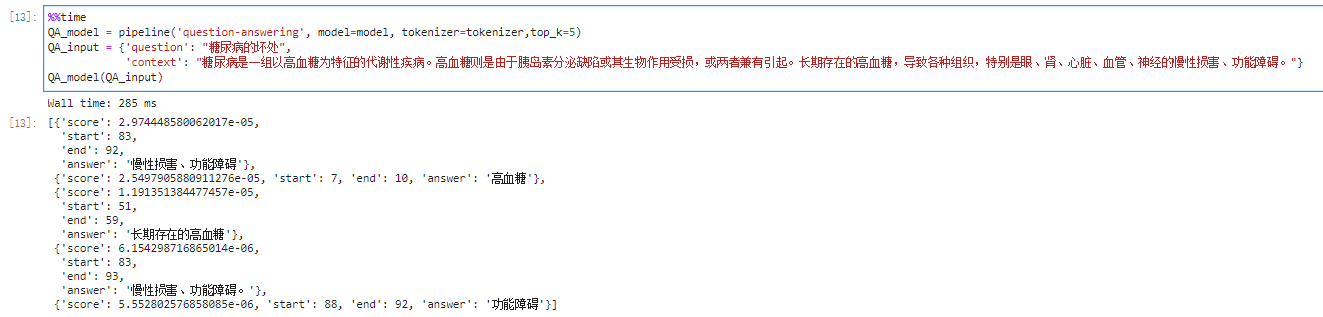
参数解读
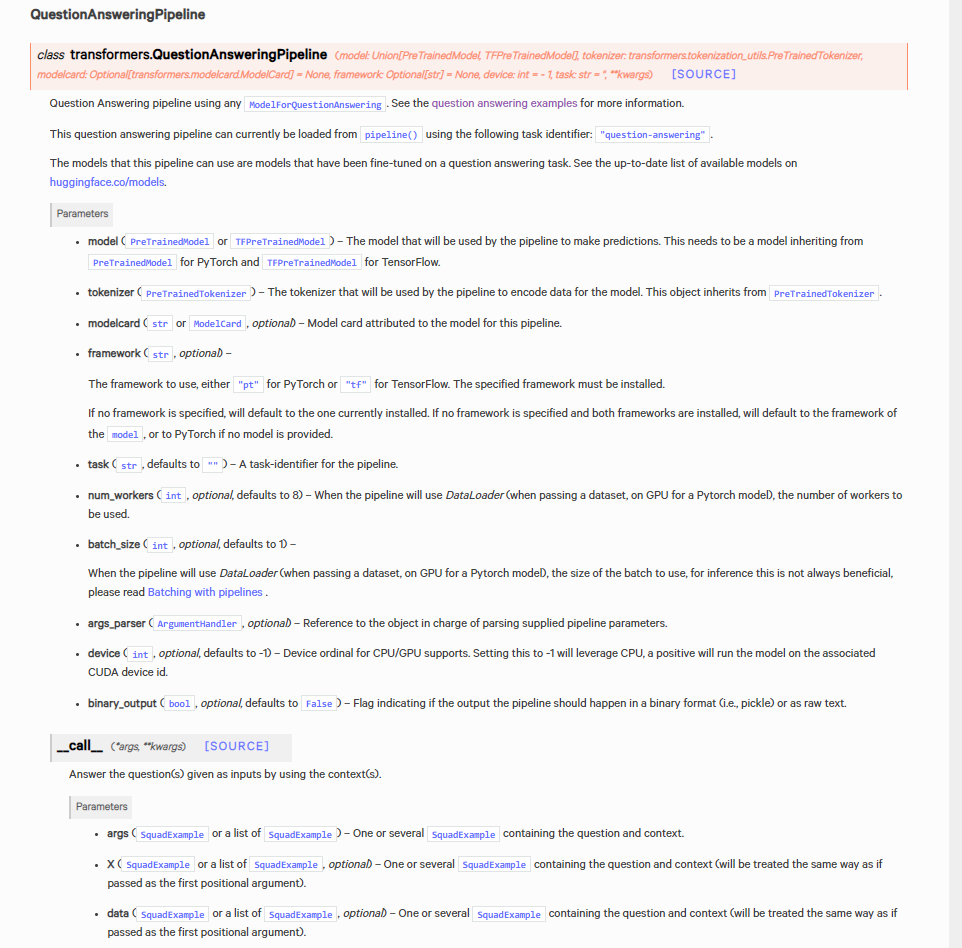
pipeline("question-answering")会跳转到QuestionAnsweringPipeline这个class,最后会返回一个字典或者一个字典list,我们主要看call这个方法里的参数,
- top_k:返回答案的数量,默认为1;如果正文中没有足够数量的答案返回,会返回少于topk个答案
- doc_stride:控制重叠块大小,默认为128
- max_answer_len:预测答案的最大长度,默认为15
- max_seq_len:分词后合并句子(正文+问题)的总长度,默认为384
- max_question_len:分词后问题的最大长度,默认为64
- handle_impossible_answer:是够接受不可能作为答案,默认为False

若有收获,就点个赞吧
0 人点赞
