![[5]快速使用hugging预训练模型进行NLP任务 - 图2](/uploads/projects/armor-novr7@work/c1599d59be18562fc78ddd2e015bfb29.svg) Huggingface 简介
Huggingface 简介
Hugging face 是一个专注于 NLP 的公司,拥有一个开源的预训练模型库 Transformers ,里面囊括了非常多的模型例如BERT GPT 等。
使用文档
官方文档地址如下:https://huggingface.co/transformers/
其他使用文档补充:transformers-使用教程
文本分类实战:从零开始文本分类 - - - 博客园大佬
模型库
官网的模型库的地址如下:https://huggingface.co/models
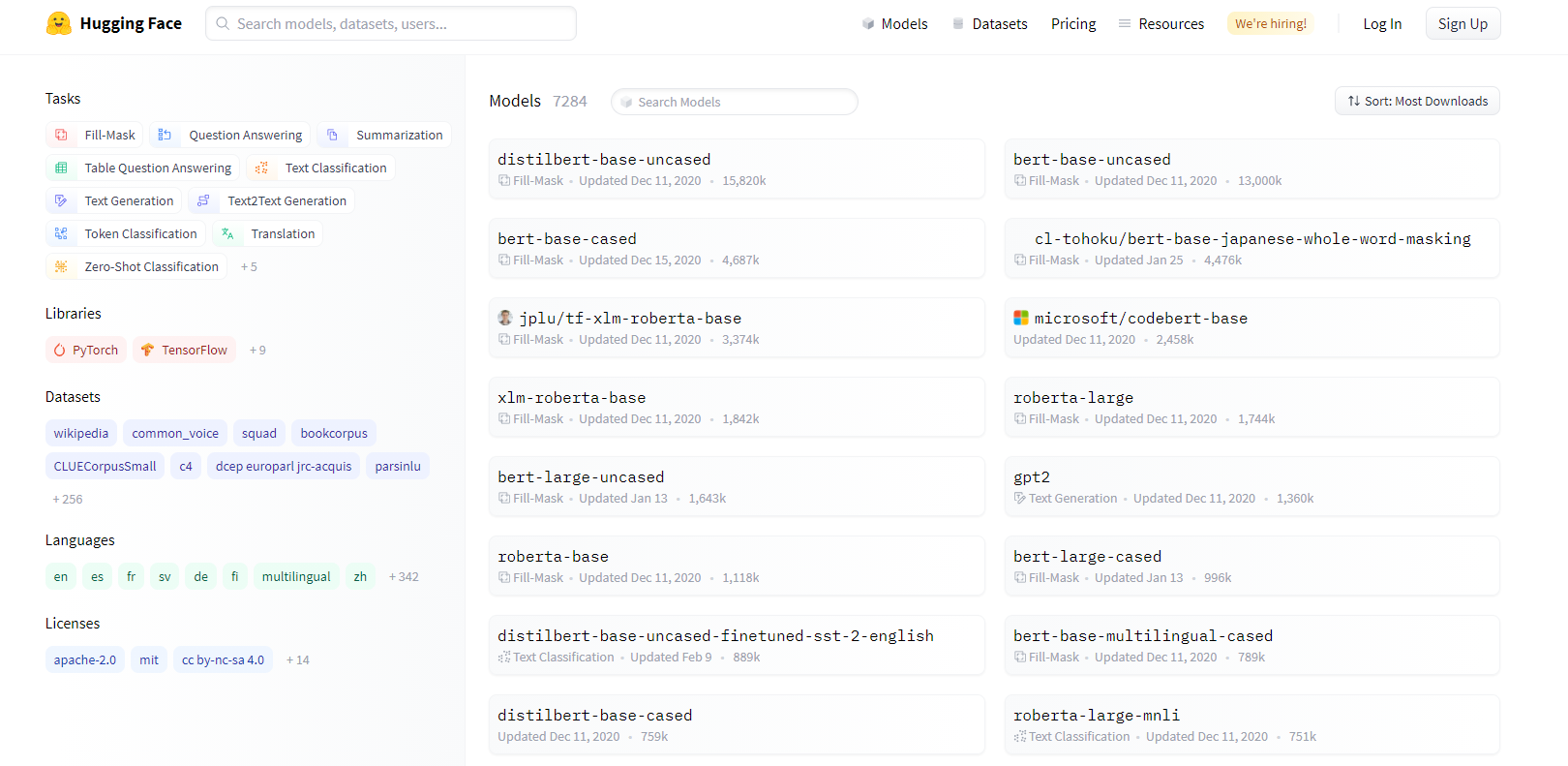
使用模型须知
第一步当然是pip啦
pip install transformers
第二部导包,使用transformers 最主要的是tokenizer和model
AutoTokenizer和AutoModel会自动进行model_name的是被,也可以直接调用制定模型的函数如BertTokenizer等- 使用
AutoTokenizer.from_pretrained读取预训练模型文件夹 ```python from transformers import AutoTokenizer,AutoModel
text = “请查看bert的分词结果” tokenizer = AutoTokenizer.from_pretrained(‘chinese-bert-base’) print(tokenizer.encode_plus(text))
提示:运行代码时,会自动检索并下载所需预训练文件,文件的默认路径在 C盘 `~/user/.cache/transformer` 中<br />如果遇到网速慢的时候可以去官网直接下载文件,如下图所示,右键另存为下载:<br />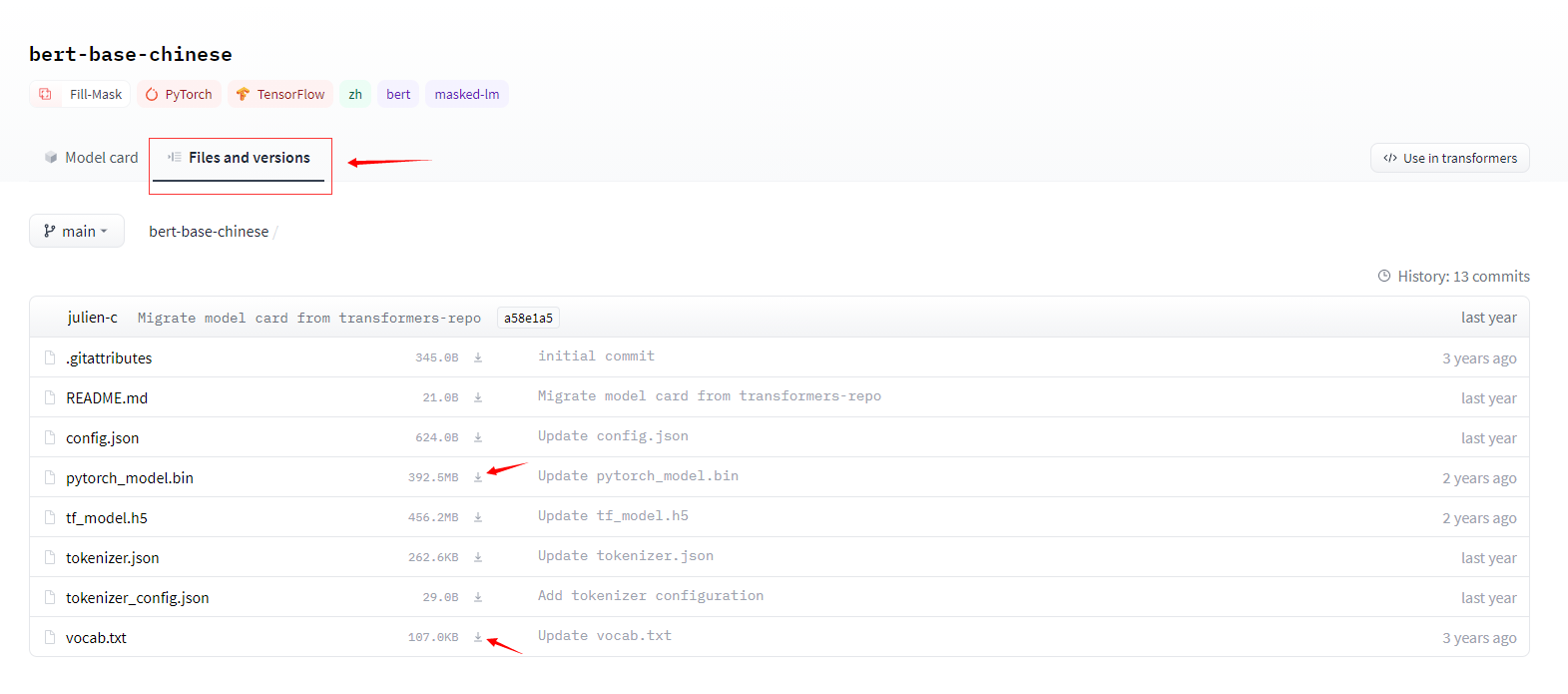也可以自定义预训练文件夹路径,如下所示:```pythontext = "请查看bert的分词结果"tokenizer = AutoTokenizer.from_pretrained(r'D:\HuProject\python_code\BERT_TEXT_EX\bert-base-chinese')print(tokenizer.encode_plus(text))
快速使用预训练模型
使用与训练模型大致可以分为四步:读取数据,制作分词,提取模型,训练模型
1.读取数据
2.制作分词
3.提取模型
4.训练模型

若有收获,就点个赞吧
0 人点赞
