
时间:2014 KDD
单位:Stony Brook University Department of Computer Scienceny 石溪大学
文献来源:https://arxiv.org/pdf/2004.00387.pdf
Deep Learning on Knowledge Graph for Recommend.pdf
Bryan Perozzi :https://github.com/phanein/
Bryan Perozzi 老师目前就职于Google ,研究方向是图表示,是数据科学和数据挖掘的大牛。
Abstract
- 简介Deepwlak
- 得到Blog-Catalog、Flickr、YouTube等多个多标签网络分类任务的潜层表示,优于现有的基准模型。
- F1高10%
- 在仅获得60%数据的情况下,胜过所有基线模型(样本稀疏时,性能很优越)
- 应用场景:网络分类和异常检测
Introduction
文章简介部分介绍了网络嵌入是什么,以社交网络为例,网络嵌入就是将网络中的点用一个低维的向量表示,并且这些向量要能反映原有网络的某些特性,比如,如果在原网络中两个点的结构类似,那么这两个点表示成的向量也应该类似。
本文提出了一种网络嵌入的方法叫DeepWalk,它的输入是一张图或者网络,输出为网络中顶点的向量表示。DeepWalk通过截断随机游走(truncated random walk)学习出一个网络的社会表示(social representation),在网络标注顶点很少的情况也能得到比较好的效果。并且该方法还具有可扩展的优点,能够适应网络的变化。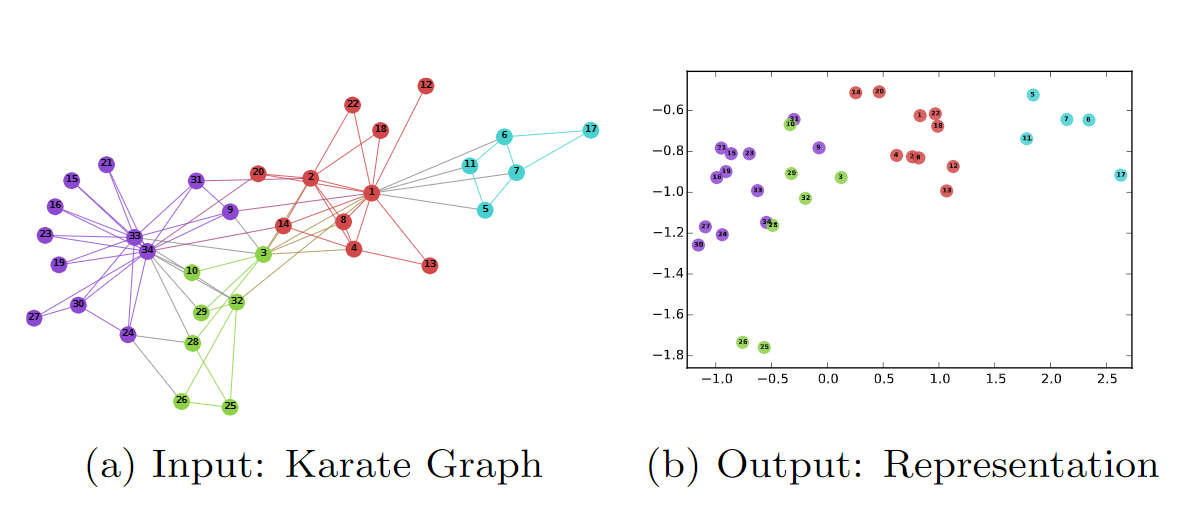
Problem Definition
图结构的定义:G =(V,E)V是网络结点:成员 ,E为边:成员和成员的关系
如果在图G的基础上再加上顶点的向量表示和顶点所属的标注(网络节点分类问题中,网络中的每个顶点都有一个类别,所属的类别即为该顶点的标注)就构成了一个标注图(labeled graph),一个部分标记的社交网络:GL = (V,E,X,Y)。顶点的表示X是一个|V|×s维的矩阵,|V|表示顶点的数量,s是代表每个顶点的向量的维数(一般比较小),所以X即为将每个顶点的向量结合在一起形成的矩阵。Y则是每个顶点的标注构成的矩阵。
Learning social representations
文中提到,在学习一个网络表示的时候需要注意的几个性质:
- 适应性(Adaptability):网络表示必须能适应网络的变化。网络是一个动态的图,不断地会有新的节点和边添加进来,网络表示需要适应网络的正常演化。
- 社区感知(Community aware):属于同一个社区的节点有着类似的表示,网络中往往会出现一些特征相似的点构成的团状结构,这些节点表示成向量后必须相似。
- 低维(Low dimensional):代表每个顶点的向量维数不能过高,过高会有过拟合的风险,对网络中有缺失数据的情况处理能力较差。
- 连续性(Continuous):低维的向量应该是连续的。
网络嵌入,可能会让人联想到NLP中的word2vec,也就是词嵌入(word embedding)。前者是将网络中的节点用向量表示,后者是将单词用向量表示。因为大多数机器学习的方法的输入往往都是一个向量,算法也都基于对向量的处理,从而将不能直接处理的东西转化成向量表示,这样就能利用机器学习的方法对其分析,这是一种很自然的思想。
本文处理网络节点的表示(node representation)就是利用了词嵌入(词向量)的的思想。词嵌入的基本处理元素是单词,对应网络网络节点的表示的处理元素是网络节点;词嵌入是对构成一个句子中单词序列进行分析,那么网络节点的表示中节点构成的序列就是随机游走。
所谓随机游走(random walk),就是在网络上不断重复地随机选择游走路径,最终形成一条贯穿网络的路径。从某个特定的端点开始,游走的每一步都从与当前节点相连的边中随机选择一条,沿着选定的边移动到下一个顶点,不断重复这个过程。下图所示蓝色部分即为一条随机游走。截断随机游走就是长度固定的随机游走。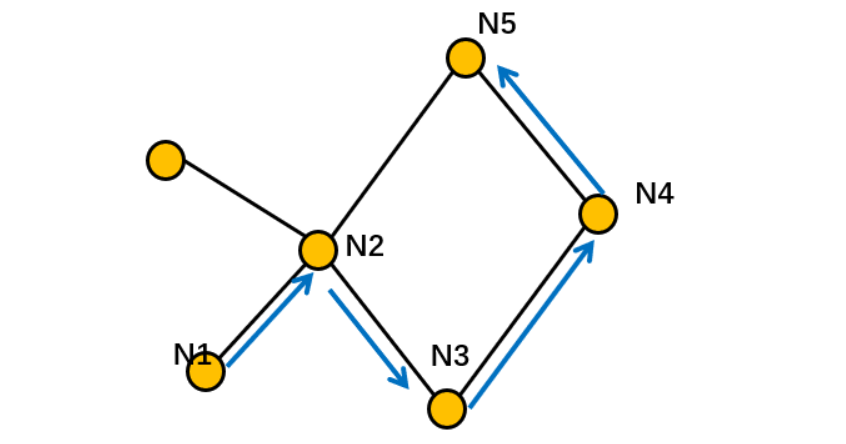
使用随机游走有两个好处:
并行化:随机游走是局部的,对于一个大的网络来说,可以同时在不同的顶点开始进行一定长度的随机游走,多个随机游走同时进行,可以减少采样的时间。
适应性:可以适应网络局部的变化。网络的演化通常是局部的点和边的变化,这样的变化只会对部分随机游走路径产生影响,因此在网络的演化过程中不需要每一次都重新计算整个网络的随机游走。
文中提到网络中随机游走的分布规律与NLP中句子序列在语料库中出现的规律有着类似的幂律分布特征。那么既然网络的特性与自然语言处理中的特性十分类似,那么就可以将NLP中词向量的模型用在网络表示中,这也是本文的思路和工作。
左图为采用随机游走的图顶点的幂律分布(2a),右图为NLP中以维基百科为语料的单词的幂律分布。

Algorithm
整个DeepWalk算法包含两部分,一部分是随机游走的生成,另一部分是参数的更新。算法的流程如下:
其中第2步是构建Hierarchical Softmax,第3步对每个节点做γ次随机游走,第4步打乱网络中的节点,第5步以每个节点为根节点生成长度为t的随机游走,第7步根据生成的随机游走使用skip-gram模型利用梯度的方法对参数进行更新。参数更新的细节如下:
实验效果
Dataset
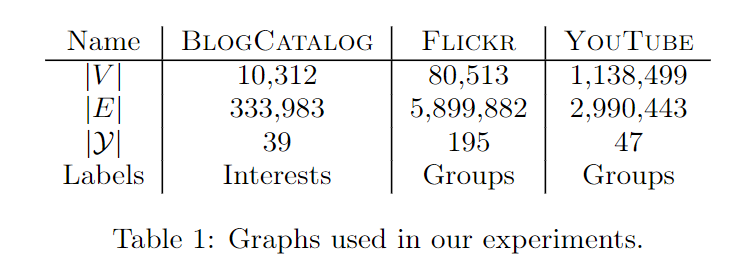
- BlogCatalog 是由博客作者提供的社交关系网络。 标签代表作者提供的主题类别。
- Flickr 是照片共享网站的用户之间的联系网络。 标签代表用户的兴趣组,例如“黑白照片”。
- YouTube 是流行视频共享网站的用户之间的社交网络。 此处的标签代表喜欢常规视频类型(例如动漫,摔跤比赛)的观众组
EXPERIMENTS
实验中经过多标签分类义务来评价算法的功能。从数据集中随机抽样标记节点的一部分(TR),并将其用作训练数据。 其他的节点被用作测试。 我们反复这个过程10次,并报告Macro-F1和Micro-F1的平均功能。对于一切的模型,运用由LibLinear完成的one-vs-rest逻辑回归扩展来前往最能够的标签。
DeepWalk中的参数设置为:γ=80,w=10,d =128。在SpectralClustering,Modularity,EdgeCluster中,将维度设置为500。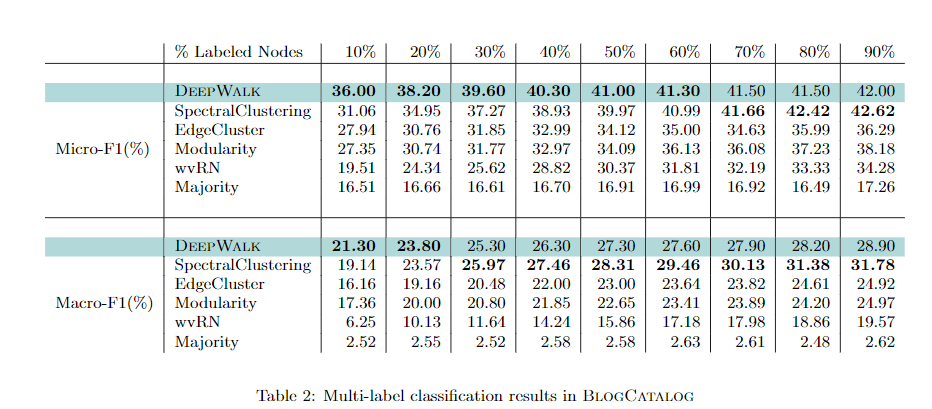
1、DeepWalk的功能一直优于EdgeCluster,Modularity和wvRN。DeepWalk在只要20%的节点被标记时的功能,比这些方法在90%的数据时被标记的状况下执行得更好。
2、SpectralClustering的功能更具竞争力,但是当Macro-F1(TR≤20%)和Micro-F1(TR≤60%)上的标记数据稀疏时,DeepWalk照旧表现优秀。
经过以上两点可以看出,算法的优势在于,只要小部分图表被标记时,具有弱小的功能。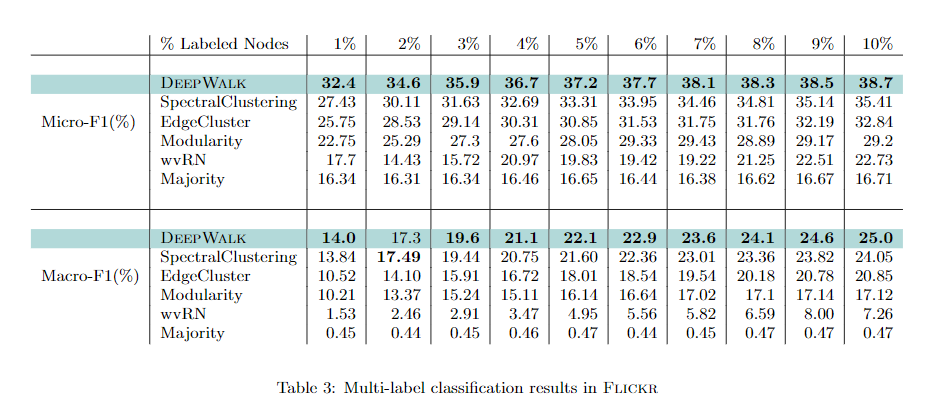
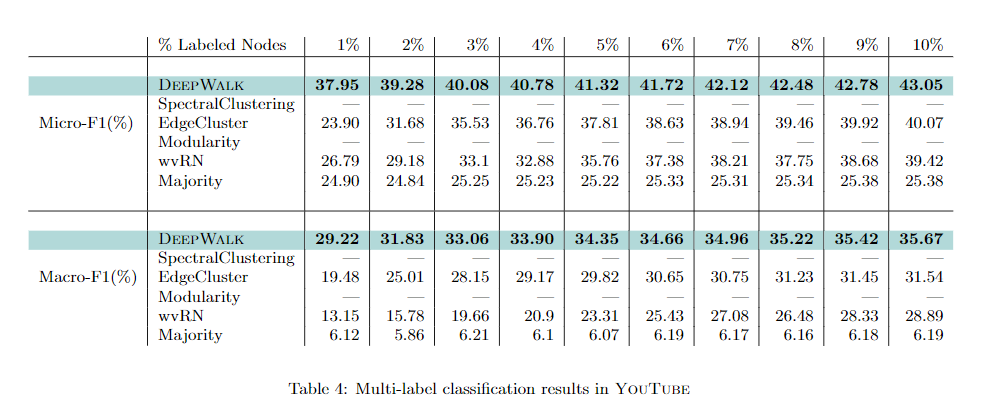
YouTube网络规模大,更接近理想世界网络。SpectralClustering和Modularity不能用于这种规模的网络。在实验中,训练比率(TR)从1%变化到10%,粗体数字表示每列中最高的功能。
结果分析:
从实验中可以看出,DeepWalk分明优于其他算法:DeepWalk可以扩展到大图,并且在这样一个稀疏标记的环境中执行得非常好。
总结
deepwalk可以说给网络学习方向打开了一个新思路,有很多优点:
- 支持数据稀疏场景
- 支持大规模场景(并行化)
但是仍然存在许多不足:
- 游走是完全随机的,但其实是不符合真实的社交网络的;
- 未考虑有向图、带权图
这篇论文是network embedding的开山之作,它将NLP中词向量的思想借鉴过来做网络的节点表示,提供了一种新的思路,后续有好几篇论文的模型使用的也是这种思路,都是利用随机游走的特征构建概率模型,用词向量中Negative Sampling(负采样)的思想解决相应问题。

若有收获,就点个赞吧
0 人点赞
