“Talk is cheap. Show me the code.”
- — Linux 之父 Linus Torvalds
最近开始看王喆大大的《深度学习推荐系统》一书,想借此入门推荐系统。书中有很多关于推荐系统的基础性介绍,内容由浅入深,相当平易近人。这系列博客将主要针对书中的内容进行梳理,如王喆老师所说构建属于自己的关于推荐系统的知识图谱,以备日后查阅。
图1 《深度学习推荐系统》
第一章 互联网的增长引擎——推荐系统
我们已经身处被推荐系统影响的时代。例子比比皆是,网购,新闻,阅读,学习充电,听歌,以及看短视频消遣。
推荐系统如引擎一般推动互联网快速增长。为什么推荐系统是互联网的增长引擎?互联网的核心需求是“增长”。增长与利润直接挂钩,而互联网的发展离不开增长这一标准。
1.为什么推荐系统是互联网的增长引擎
1.1 推荐系统要解决的根本问题是什么?
推荐系统要解决的问题用一句话总结就是,在“信息过载”的情况下,用户如何高效获取感兴趣的信息。当然这是在用户角度上的阐述。
在公司角度:推荐系统解决产品能够最大限度地吸引用户,留存用户,增加用户黏性,提高用户转化率的问题,从而达到公司商业目标连续增长的目的。
因此推荐系统不仅是用户高效获取感兴趣内容的”引擎”,也是互联网公司达成商业目标的”引擎”
1.2 推荐系统和YouTube的观看时长增长
YouTube作为全球最大的视频分享平台,其优化用户体验最直接的就是用户观看时长,YouTube的主要收入源于广告。广告曝光率和用户观看时长成正比,因此公司营收和优化用户体现在”观看时长”上达成一致。正因如此,YouTube的推荐系统主要优化目标就是观看时长,而非传统推荐系统强调的”点击率”。
在论文Deep Neural Networks for YouTube Recommendations中非常明确将观看时长作为优化目标的建模方法。
1.3 推荐系统与电商网站的收入增长
最著名的电商推荐系统无疑是天猫的”千人面推荐系统”,天猫的推荐系统真正实现了首页所有元素的个性化推荐。其背后一切是由以提高转化,点击率为核心的推荐算法驱动的。2019年天猫双十一的成交额为2684亿元,假设推荐系统能提高平台整体转化率1%,那么在2684亿的基础上将增加26.84亿的可观利润!这就是推荐引擎的魅力。
2.推荐系统的架构
- 在明确互联网的核心需求是增长,以及推荐系统的重要性
- 从推荐系统的根本问题出发,我们可以清楚地知道,推荐系统要处理的其实是处理“人”和“信息”之间的关系问题。也就是基于“人”和“信息”,构建出一个找寻感兴趣信息的方法。
信息大致可以分为三类:
- 用户信息:与人有关信息,包括历史行为,人口属性,关系网格。
- 物品信息:购物网站的商品,视频网站的视频,新闻网站的新闻。
- 场景信息:在具体的推荐场景中,用户对的最终选择一般会受时间,地点,用户状态等一系列环境信息的影响。这些信息被称为场景信息或者上下文信息
2.1 推荐系统的逻辑框架
清楚了这些信息的定义,推荐系统要处理的问题就可以被形式化地定义为:对于某个用户U(User),在特定场景C(Context)下,针对海量的“物品”信息构建一个函数 ,预测用户对特定候选物品I(Item)的喜好程度,再根据喜好程度对所有候选物品进行排序,生成推荐列表的问题。
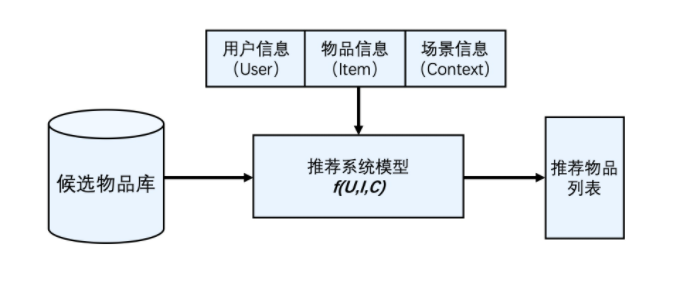
图2 推荐系统逻辑架构示意图
逻辑框架简单,但我们正是在这种基础上对各模块进行细化和扩展,才有了推荐系统的整个技术体系。
推荐系统如是,互联网亦是如此。
2.2 推荐系统的技术框架
在实际的场景中,工程师需要解决的由两类问题:
- 数据和信息相关的问题:用户信息,物品信息,场景信息分别是什么?如何存储,更新,处理?
- 数据离线批处理
- 实时流处理
- 推荐系统算法和模型相关的问题:如何训练?如何预测?如何达成更好的推荐效果?
- 训练(Training)
- 评估(Evaluation)
- 部署(Deployment)
- 线上推断(Online Inference)
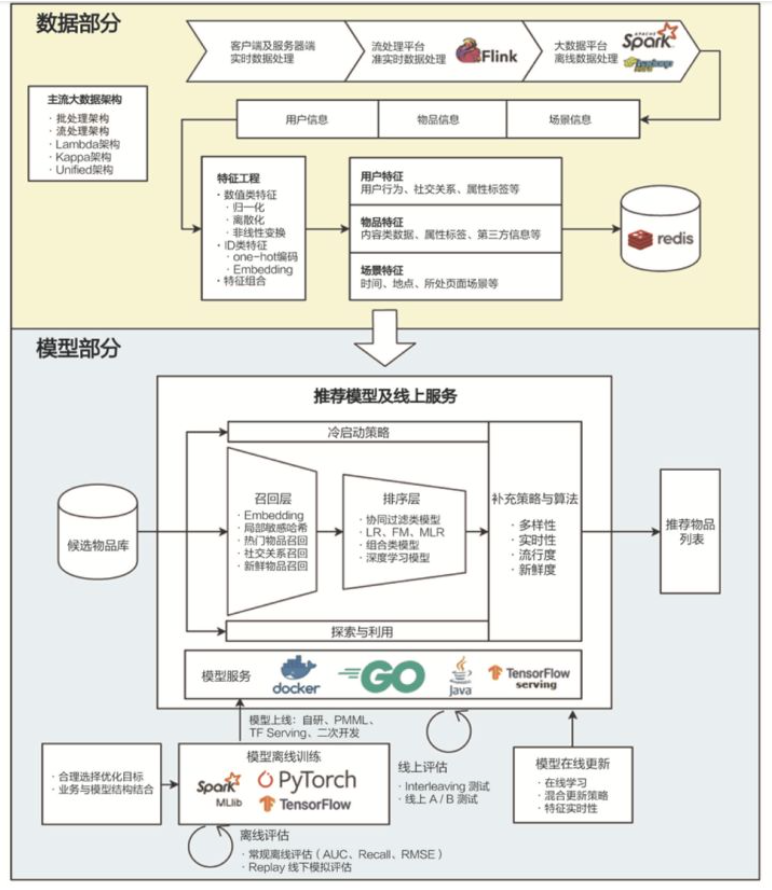
图3 推荐系统的技术框架示意图
2.3 推荐系统的数据部分
源头活水,水量大,水流快
推荐系统的“数据部分”主要负责的是“用户”“物品”“场景”信息的收集与处理。根据处理数据量和处理实时性的不同,我们会用到三种不同的数据处理方式,按照实时性的强弱排序的话,它们依次是客户端与服务器端实时数据处理、流处理平台准实时数据处理、大数据平台离线数据处理。在实时性由强到弱递减的同时,三种平台的海量数据处理能力则由弱到强。
因此,一个成熟推荐系统的数据流系统会将三者取长补短,配合使用。
(例:使用Spark进行离线数据处理,使用Flink进行准实时数据处理等等)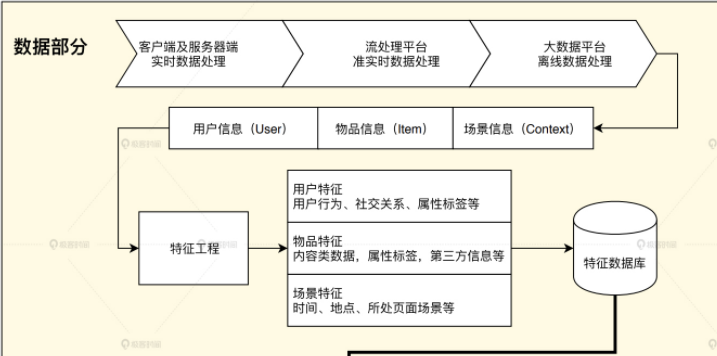
图4 推荐系统的数据部分示意图
大数据计算平台通过对推荐系统日志,物品和用户的元数据等信息的处理,获得了推荐模型的训练数据、特征数据、统计数据等。那这些数据都有什么用呢?具体说来,大数据平台加工后的数据出口主要有 3 个:
- 生成推荐系统模型所需的样本数据,用于算法模型的训练和评估。
- 生成推荐系统模型服务(Model Serving)所需的“用户特征”,“物品特征”和一部分“场景特征”,用于推荐系统的线上推断。
- 生成系统监控、商业智能(Business Intelligence,BI)系统所需的统计型数据。
可以说,推荐系统的数据部分是整个推荐系统的“水源”,我们只有保证“水源”的持续、纯净,才能不断地“滋养”推荐系统,使其高效地运转并准确地输出。在深度学习时代,深度学习模型对于“水源”的要求更高了,首先是水量要大,只有这样才能保证我们训练出的深度学习模型能够尽快收敛;其次是“水流”要快,让数据能够尽快地流到模型更新训练的模块,这样才能够让模型实时的抓住用户兴趣变化的趋势,这就推动了大数据引擎 Spark,以及流计算平台 Flink 的发展和应用。
2.4 推荐系统的模型部分
研究核心,业界和学界的研究重心
推荐系统的“模型部分”是推荐系统的主体。模型的结构一般由“召回层”、“排序层”以及“补充策略与算法层”组成。
“召回层”:一般由高效的召回规则、算法或简单的模型组成,这让推荐系统能快速从海量的候选集中召回用户可能感兴趣的物品。
“排序层”:利用排序模型对初筛的候选集进行精排序。
“补充策略与算法层”:也被称为“再排序层”,是在返回给用户推荐列表之前,为兼顾结果的“多样性”“流行度”“新鲜度”等指标,结合一些补充的策略和算法对推荐列表进行一定的调整,最终形成用户可见的推荐列表。
从推荐系统模型接收到所有候选物品集,到最后产生推荐列表,这一过程一般叫做“模型服务过程”。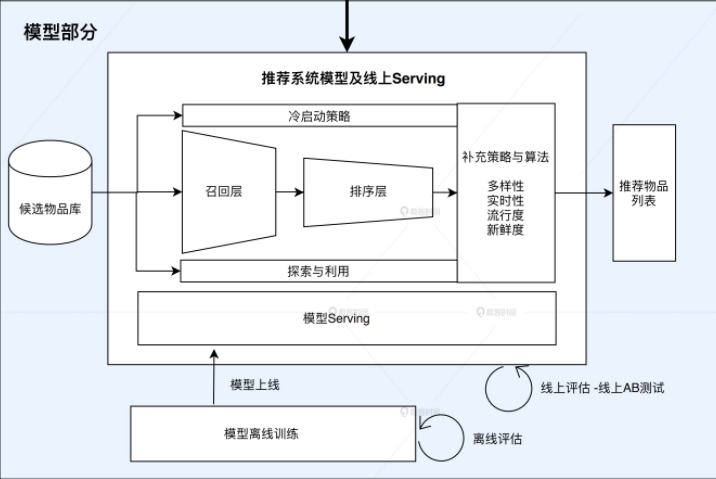
图5 推荐系统的模型部分示意图
模型的训练方法根据环境的不同,可以分为“离线训练”和“在线更新”两部分。
其中,离线训练的特点是可以利用全量样本和特征,使模型逼近全局最优点,
而在线更新则可以准实时地“消化”新的数据样本,更快地反应新的数据变化趋势,满足模型实时性的需求。
除此之外,为了评估推荐系统模型的效果,以及模型的迭代优化,推荐系统的模型部分还包括“离线评估”和“线上 A/B 测试”等多种评估模块,用来得出线下和线上评估指标,指导下一步的模型迭代优化。
2.5 深度学习对推荐系统的革命性贡献
深度学习对推荐系统的革命性贡献在于推荐模型部分的改进。
- 对数据模式的拟合能力和对特征组合的挖掘能力更强。
- 模型结构灵活,根据不同推荐系统调整模型,使之与特定业务数据“完美”契合。
深度学习对于推荐系统的革命集中在模型部分,那具体都有什么呢?我把最典型的深度学习应用总结成了 3 点:
- 深度学习中 Embedding 技术在召回层的应用。作为深度学习中非常核心的 Embedding 技术,将它应用在推荐系统的召回层中,做相关物品的快速召回,已经是业界非常主流的解决方案了。
- 不同结构的深度学习模型在排序层的应用。排序层(也称精排层)是影响推荐效果的重中之重,也是深度学习模型大展拳脚的领域。深度学习模型的灵活性高,表达能力强的特点,这让它非常适合于大数据量下的精确排序。深度学习排序模型毫无疑问是业界和学界都在不断加大投入,快速迭代的部分。
- 增强学习在模型更新、工程模型一体化方向上的应用。增强学习可以说是与深度学习密切相关的另一机器学习领域,它在推荐系统中的应用,让推荐系统可以在实时性层面更上一层楼。
但同时也带来新的问题:如何尽可能做到训练海量数据和实时提取海量特征?
参考文献
[1] 《深度学习推荐系统》王喆
[2] Paul Covington;Jay Adams;Emre Sargin.Deep Neural Networks for YouTube Recommendations[C].ACM.2016.

若有收获,就点个赞吧
0 人点赞
