软件杯流程
- (一)报名阶段(2021年3月1日-5月31日)
- (二)辅导阶段(拟定:2021年3月1日-5月31日)
- (三)作品提交及初赛(拟于2021年7月完成作品提交和初赛评审,预计6月中下旬提交作品)
- (四)作品优化 晋级决赛的队伍,可在原作品的基础上进行修改和完善
- (五)总决赛及颁奖典礼 拟定于2021年8月底9月初举办(具体安排另行通知,请留意官网新闻动态)。
作品Demo展示
软件杯比赛要求
| 赛题简介:介绍整个赛题的实现目标、实用价值、涉及技术和整体要求 | 新闻发展越来越快,每天各种各样的新闻令人目不暇接, 对新闻进行科学的分类既能够方便不同的阅读群体根据需求快速选取自身感兴趣的新闻,也能够有效满足对海量的新闻素材提供科学的检索需求。 |
|---|---|
| 赛题业务场景:描述赛题相关的真实企业业务背景。从真实场景中,适当简化或者提炼出适合比赛的赛题场景 | 赛题以新闻数据为赛题数据,整合划分出如下候选分类类别:财经、房产、教育、科技、军事、汽车、体育、游戏、娱乐和其他共十类的新闻文本数据。选手根据新闻标题和内容,进行分类。 输入为新闻的标题和正文内容,输出为新闻的分类。 |
| 基本功能要求 | 1、输出分类的准确率不低于80% 2、提供简单的可视化界面。能够输入单条新闻,输出新闻的分类,或者支持本地上传csv/xlsx文件,批量输入新闻,并输出新闻分类。 |
| 非功能性要求 | 执行效率:单条新闻,程序从输入到输出的执行时间不超过5s |
| 实现条件:开发环境、实验平台、开发语言、数据库、编译器、涉及硬件等实现条件 | 开发软件:不限制 开发语言:Java或Python 服务器操作系统:windows 运行环境:如使用python,需使用python3.6以上版本 |
| 测试数据或平台:提供给参赛者的测试环境和测试数据 | 提供了十类新闻的测试数据,供选手分析使用。鼓励选手可自行通过互联网收集数据集进行训练,并可通过项目、文档、演示视频等形式来呈现收集过程 数据下载:训练数据样本.xlsx |
| 开发所需设备及设备指标需求说明 | 开发设备:市场上常规可见的PC机即可 |
| 文档及其他要求 | 代码规范,可读性强、文档说明清晰 不能使用各种在线api接口服务 |
| 各评分项及大致占比 【主要得分点】 - 准确率占比最大 - 其次是交互性 |
1、代码的规范性以及技术文档的完整性 2、预测结果的f1_score均值 3、代码的执行效率 其中,预测结果的准确率为主要的评审要点,占主要评分占比。 |
| 初赛作品提交要求 | 1、提供源文件、说明使用文档以及算法的实现原理说明,如果使用开源算法,请注明。 2、结果验证:根据后期给定的测试集数据,通过参赛选手的程序进行分类,得出f1_score均值,作为主要参考。 3、演示视频(7分钟内) |
比赛数据集一览
比赛的测试集为10分类的新闻文本数据集
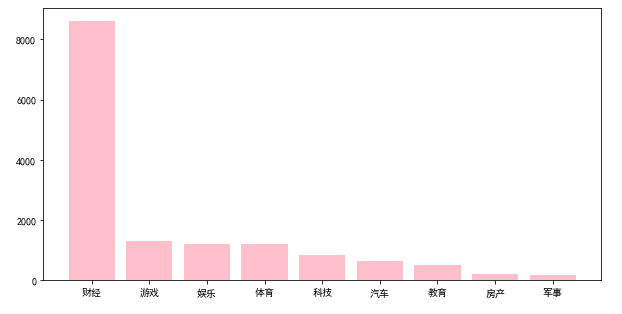
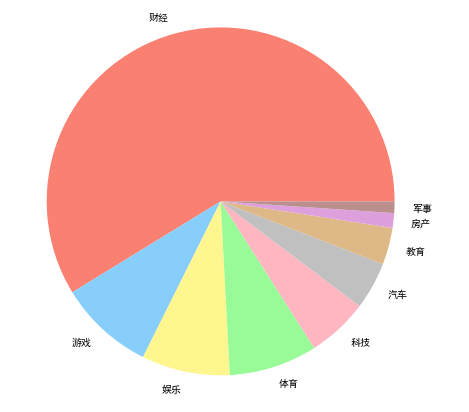
10个类别分别为:财经、房产、教育、科技、军事、汽车、体育、游戏、娱乐、其他,具体数据如下:
- 类别不平衡
- 其他类没有数据集
【解决办法:文本生成、数据增强、找其他数据集补充】
| 类别 | 数目 | 类别 | 数目 |
|---|---|---|---|
| 财经 | 8597 | 汽车 | 647 |
| 房产 | 200 | 体育 | 1200 |
| 教育 | 500 | 游戏 | 1300 |
| 科技 | 830 | 娱乐 | 1200 |
| 军事 | 158 | 其他 | 0 |
文本属性一览
类别分布
- 类别不平衡 - - - 肯定要做数据增强或者补充数据集【新闻文本易获取,那其他数据集做补充数据集更高效】
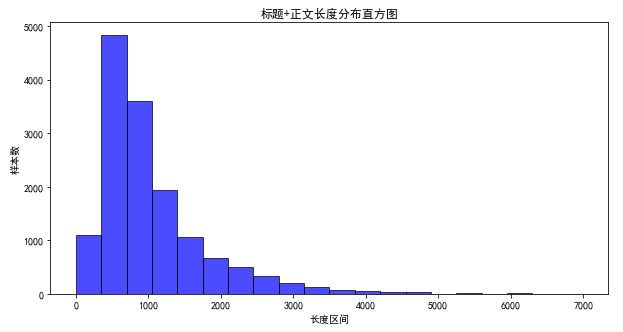
文本长度
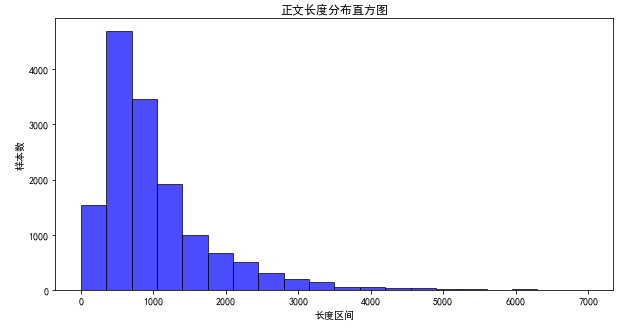
文本长度是max_len的重要依据,一般设置max_len为95%的文本长度的最大值。
- 正文文本长度分布在【0-6500】区间内
- 90%的文本长度小于2051
- 95%的文本长度小于2592
- 99%的文本长度小于4051
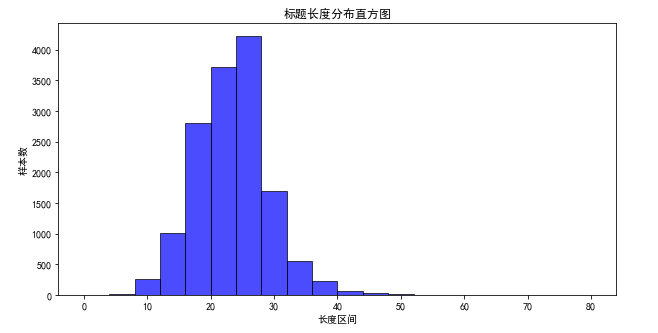
- 标题文本长度分布在【0-60】区间内
- 90%的文本长度小于30
- 95%的文本长度小于32
- 99%的文本长度小于39
- 标题+正文长度分布在【0-6500】区间内
- 90%的文本长度小于2070
- 95%的文本长度小于2614
- 99%的文本长度小于4071
难点分析
- 数据量少
- 标签数据分布不平衡
-
算法方案
Baseline(TextCNN)
评价指标为F1值
- 不进行任何处理,仅将文本分词补长后进行训练看看效果
# 代码已整合...# 未上传数据、词向量和已训练模型太大了,# 先进tx 运行train.py,完成训练后再run.py开启flask映射查看项目# 代码开源到gitee上地址:https://gitee.com/hu_tingkai/term_-project/tree/master/CQUSTKGLAB
实验效果
**
Batch_size均为64,epoch均为10
| Baseline - TextCNN- title | |||||
|---|---|---|---|---|---|
大规模语料库 |
Max_Len | 正确率 | 精确率 | 召回率 | F1值 |
| 30 | 0.836 | 0.847 | 0.831 | 0.839 | |
| 32 | 0.845 | 0.856 | 0.838 | 0.847 | |
| 39 | 0.842 | 0.860 | 0.833 | 0.846 | |
| 45 | 0.836 | 0.851 | 0.827 | 0.839 |
未见过的验证集效果(军事、汽车、科技、房产、教育 5类效果较差)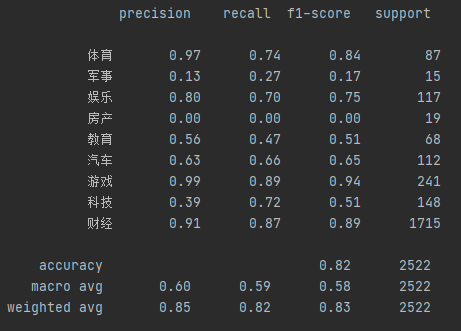
Batch_size均为64,epoch均为5
| Baseline - TextCNN- content | |||||
|---|---|---|---|---|---|
大规模语料库 |
Max_Len | 正确率 | 精确率 | 召回率 | F1值 |
| 2051 | 0.890 | 0.901 | 0.878 | 0.889 | |
| 2592 | 0.888 | 0.906 | 0.874 | 0.890 | |
| 4050 | 0.899 | 0.911 | 0.888 | 0.899 | |
自训练语料库 |
2051 | 0.887 | 0.904 | 0.878 | 0.891 |
| 2592 | 0.882 | 0.897 | 0.873 | 0.885 |
改进想法一
【改进方向】:文本预处理
【改进方法】:将一条长样本截断使其变为 text_length / set_length 条样本
【改进目的】:1.不忽视长文本,提高数据利用率 2.更短padding可以加速训练过程
【效果对比】:
改进想法二
【改进方向】:文本数据集
【改进方法】:使用THUCNews14分类数据集来扩充数据集
【改进目的】:1.平衡类别,填补空缺 2.增加数据量增强模型表现
THUCNews14分类数据一览
| 类别 | 数目 | 类别 | 数目 |
|---|---|---|---|
| 科技 | 162929 | 财经 | 37098 |
| 股票 | 154398 | 家居 | 32586 |
| 体育 | 131604 | 游戏 | 24373 |
| 娱乐 | 92632 | 房产 | 20050 |
| 时政 | 63086 | 时尚 | 13368 |
| 社会 | 50849 | 彩票 | 7588 |
| 教育 | 41936 | 星座 | 3578 |
【效果对比】:
| 数据增强 | TextCNN | TextRNN | TextBiLSTM | |
|---|---|---|---|---|
有噪声 |
1k | 0.85 | 0.83 | 0.81 |
| 3k | 0.85 | 0.83 | 0.81 | |
| 10k | 0.87 | 0.86 | 0.84 | |
| 20k | OOM | OOM | OOM | |
无噪声 |
1k | |||
| 3k | ||||
| 10k | 0.89 |
本地部署
- 简单flask本地部署(类似以下结构)
- 部署前提
- 算法代码能跑通
- 把算法代码里所有相对路径变为绝对路径,自定义包路径也需要修改
- 正确创建项目目录
项目目录结构如下:
__ algorithm # 文本分类算法放在这个文件夹里__ templates # html文件放在这个文件夹里______ index.html # html页面__ run.py # flask启动py文件
index.html
<!DOCTYPE html><html lang="en"><head><meta charset="UTF-8"><title>Title</title></head><body><form action="/login" method="post">{% if title != ''%}<p><textarea name="title" placeholder="请输出标题" rows="2" cols="100">{{title}}</textarea></p>{% else %}<p><textarea name="title" placeholder="请输出标题" rows="2" cols="100"></textarea></p>{% endif %}{% if title != ''%}<p><textarea name="content" placeholder="请输出正文" rows="15" cols="100">{{content}}</textarea></p>{% else %}<p><textarea name="content" placeholder="请输出正文" rows="15" cols="100">{{content}}</textarea></p>{% endif %}<!-- <p><textarea name="title" placeholder="请输出标题" rows="2" cols="100"></textarea></p>--><!-- <p><textarea name="content" placeholder="请输出正文" rows="15" cols="100"></textarea></p>--><p><input type="submit" value="预测"></p></form><p>{% if result != ''%}<p>结果:{{result}}</p><p>耗时:{{time}}</p>{% endif %}</p></body></html>
run.py
from flask import Flask,request,render_templateapp = Flask(__name__)@app.route('/index',methods=['GET', 'POST'])def login():# f = open('templates/login.html',encoding='utf-8').read()if request.method=='GET':return render_template('index.html')elif request.method=='POST':title = request.form.get("title")content = request.form.get("content")result = result_predict(title,content)return render_template('index.html',title=title,content=content,result=result)if __name__ == '__main__':app.run(debug=True)
部署结果测试
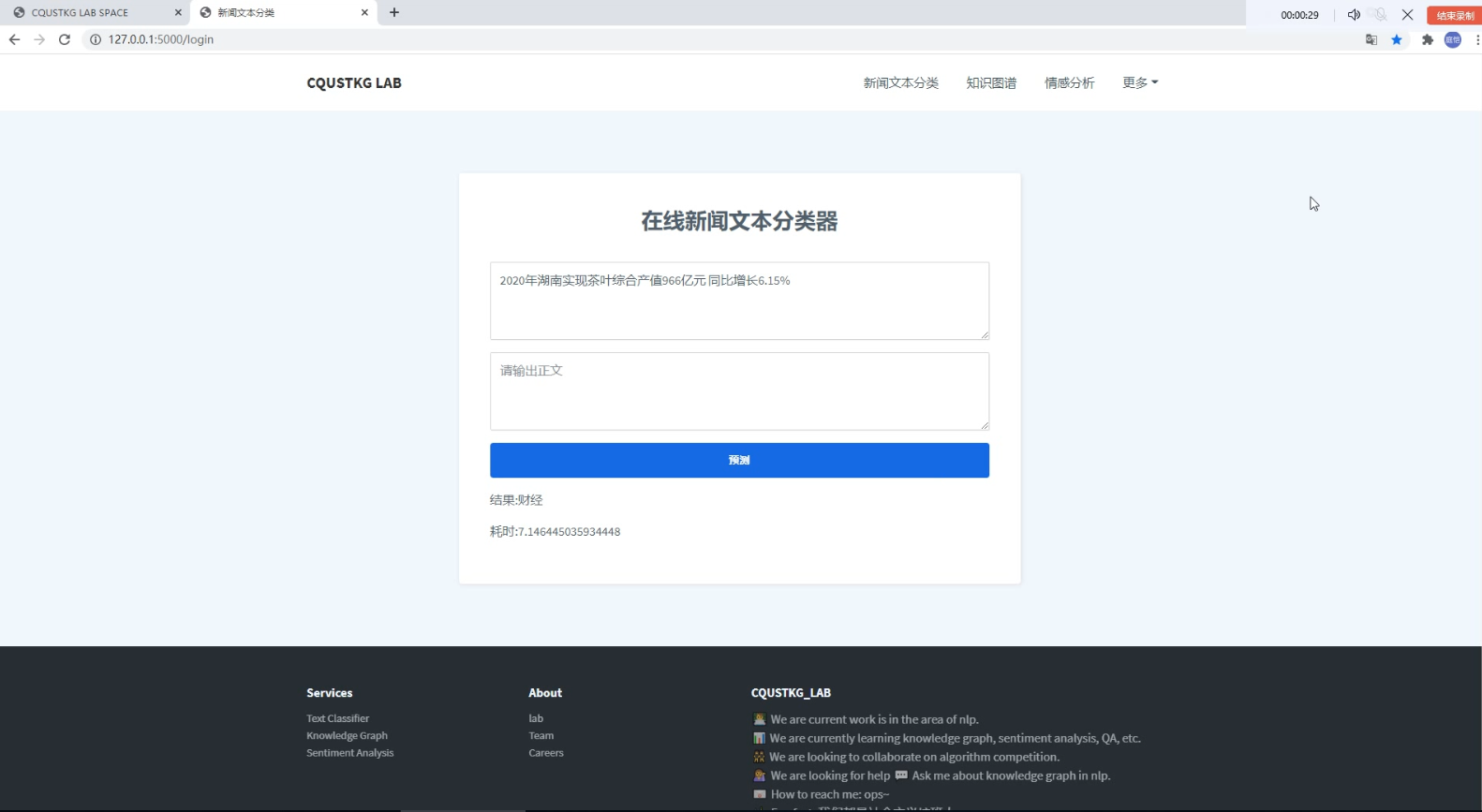
关于flask深度学习模型的部署攻略
https://blog.csdn.net/codingpy/article/details/103607706
新闻门户网站集合
腾讯新闻:https://news.qq.com/网易新闻:https://www.163.com/新浪新闻:https://news.sina.com.cn/搜狐新闻:https://www.sohu.com/百度新闻:https://news.baidu.com/微博官微:https://weibo.com/人民网:http://www.people.com.cn/新华网:http://www.xinhuanet.com/中新网:http://www.chinanews.com/...
提分
CCF 情感分析 复赛第一经验
- bert的token最长只有512,通过不同的阶段其F1值分值也不一样
- 伪标签 对模型提升效果显著
- 模型融合(一般都是投票,好而不同提高泛化)
- 提取bert各层(这个有难度)

万金油提分法 伪标签的构造
利用标签名的语义近似度来分类
伊利诺伊大学香槟分校韩家炜老师课题组
EMNLP2020 Text Classification Using Label Names Only: A Language Model Self-Training Approach
论文下载:https://arxiv.org/pdf/2010.07245.pdf
代码开源:https://github.com/yumeng5/LOTClass

若有收获,就点个赞吧
0 人点赞
