本节内容概述
文本表示
自然语言处理中最基础、最本质的问题,即文本如何在计算机内表示,才能达到易于处理和计算的目的。
三大类自然语言处理任务
语言模型、基础任务以及应用任务。其中,基础任务包括中文分词、词性标注、句法分析和语义分析等,应用任务包括信息抽取、情感分析、问答系统、机器翻译和对话系统等。
三大问题及其解决思路
上述任务可以归纳为文本分类、结构预测、序列到系列三大类问题,同事介绍解决三大类问题的解决思路。
自然语言任务的评价方法
包括针对确定答案的准确率、F值;针对非确定答案的BLEU值;以及针对开放答案的人工评价等。
2.1 文本表示
要利用计算机对自然语言进行处理,首要解决语言再计算机内部的存储和设计问题
- 基于规则的方法:要判断一个句子的情感极性,规则行事可能为:如果句子出现“喜欢”、“漂亮”等褒义词则为褒义,反之出现贬义词则为贬义。
- 优点:简单
- 缺点:依赖专家经验,耗费大量人力物力财力,规则的表达能力有限对复杂语言无能为力,规则之间村咋子矛盾和冲突
- 基于机器学习的方法:最本质的思想是将文本表示为向量,其中每一维代表一个特征,决策时只需要对这些特征的相应值进行加权求和,以情感极性识别为例子:令向量x的每一维表示某个词在该文本中出现的次数,如x1表示“我”出现的次数,x2表示“喜欢”出现的次数,x3表示“电影”出现的次数,x4表示“讨厌”出现的次数等,如果某个词在该句中没有出现,则相应的维数被设置为0。可见,输入向量x的大小恰好为整个词表(所有不相同的词)的大小。然后就可以根据每个词对判断情感极性的重要性进行加权,如“喜欢”(x2)对应的权重ω2可能比较大,而“讨厌”(x4)对应的权重ω4可能比较小(可以为负数),对于情感极性影响比较小的词,如“我”“电影”等,对应的权重可能会趋近于0。
- 这种文本表示方法是独热表示和词袋表示两种技术的组合
- 除了应用于极性识别外,文本向量表示还可以用于计算两个文本之间的相似度,采用余弦函数等度量函数表示两个向量之间的相似度,并用于信息检索等任务。
2.1.1 词的独热表示
所谓词的独热表示,即使用一个词表大小的向量表示一个词(假设词表为 ,则其大小为
,则其大小为 ),然后将词表中的第
),然后将词表中的第 个词
个词 表示为向量:
表示为向量:
在该向量中,词表中第i个词在第i维上被设置为1,其余维均为0。这种表示被称为词的独热表示或独热编码(One-hotEncoding)。
- 独热编码的缺点:不同词完全使用不同的向量进行表示,即使语义上相似的词在计算机中度量相似度却会为0;数据稀疏(Data Sparsity)问题会导致语言现象未被充分学习到。
- 为了缓解数据稀疏问题,传统的做法是除了词自身,再提取更多和词相关的泛化特征,如词性、词义、词聚类等。以语义特征为例,引入WordNet等语义词典,可以获知“美丽”和“漂亮”是同义词。
- 可以说传统机器学习方法在解决自然语言处理问题时,大部分精力用在挖掘有效特征上。
2.1.2 词的分布式表示
独热词表示稀疏,引入特征设计费事费力,是否有一种自动提取特征并设置相应的特征值呢?
1.分布式语义假设
人们在阅读过程中遇到从未见过的词时,通常会根据上下文来推断其含义以及相关属性。基于这种思想:John Rupert Firth 在1957年提出分布式语义假设
词的含义可由其上下文的分布进行表示。
分布式语义假设仅提供了一种语义建模的思想,具体到表现形式和上下文的选择,以及如何利用上下文的分布特征,都是待解决的问题
作者举了一个简单的例子:表中的每一行代表一个词的向量。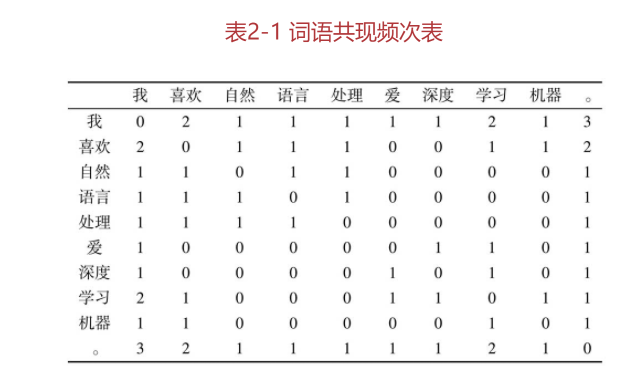
除了词,上下文的选择有很多中方式,而选择不同的上下文得到的词向量表示性质会有所不同。
- 可以固定窗口内的词作为上下文:词表示更多地反应词的局部性质
- 可以使用所在文档本身作为上下文:更多地反应词代表的主题信息
直接使用与上下文的共现频次作为词的向量表示,至少存在以下三个问题:
- 高频词误导计算结果。“。”与其他词的共现频次很高,导致实际上可能没有关系的两个词由于都和这些词共现过,从而产生了较高的相似度。
- 共现频次无法反映词之间的高阶关系。例如,假设词“A”与“B”共现过,“B”与“C”共现过,“C”与“D”共现过,通过共现频次,只能获知“A”与“C”都与“B”共现过,它们之间存在一定的关系,而“A”与“D”这种高阶的关系则无法知晓。
- 仍然存在稀疏性的问题。向量中仍有大量的值为0。
2.点互信息
如何解决高频词误导计算结果的问题。
最简单的想法:如果一个词与很多词共现,则降低其权重;反之,如果一个词只与个别词共现,则提高其权重。
信息论中的点互信息(Pointwise Mutual Information,PMI)恰好符合这一点。
对于词 和上下文,其PMI为:
式中: :w与c的共现概率
:w与c的共现概率 :w出现的概率
:w出现的概率 :c出现的概率
:c出现的概率
当某个词与上下文之间共现次数较低时,可能会得到负的PMI值。考虑到这种情况下的PMI不太稳定(具有较大的方差),在实际应用中通常采用PPMI (Positive PMI)的形式,即:
PMI代码实现:
# 待补充import numpy as npdef PMI(M,positive=True):passM = np.array([[],[]])M_PMI = PMI(M)np.set_printoptions(precision=2)print(M_PMI)
除了PMI,还有其他方法也可以达到类似的目的,如信息检索中常用的TF-IDF方法等。
3.奇异值分解
如何解决共现频次无法反映词之间高阶关系的问题。
相关的技术有很多,其中奇异值分解(Singular Value Decomposition,SVD)是一种常见的做法。
通过截断奇异值分解所得到的矩阵U中的每一行,则为相应词的d维向量表示,该向量一般具有连续、低维和稠密的性质。由于U的各列相互正交,因此可以认为词表示的每一维表达了该词的一种独立的“潜在语义”,所以这种方法也被称作潜在语义分析(Latent Semantic Analysis,LSA)。
代码:
在Python的numpy.linalg库中内置了SVD函数,只需要输入贡献矩阵,然后调用相应的函数即可
U,s,Vh = np.linalg.svd(M_PMI)
在信息检索等领域,也经常通过词与其出现的文档构成“词—文档”共现矩阵,此时也可以通过以上介绍的奇异值分解技术进行降维,并在低维空间(潜在语义空间)内计算词语或者文档之间的相似度,该技术也称潜在语义索引(Latent SemanticIndexing,LSI)。
缺点:在基于传统机器学习的方法中,词的分布式表示取得了不错的效果,但是其仍然存在一些问题
- 共现矩阵规模较大时,奇异值分解的运行速度非常慢
- 如果想在原来语料库的基础上增加更多的数据,则需要重新运行奇异值分解算法,代价非常高
- 分布式表示只能用于表示比较短的单元,如词或短语等,如果待表示的单元比较长,如段落、句子等,由于与其共现的上下文会非常少,则无法获得有效的分布式表示
- 分布式表示一旦训练完成,则无法修改
为了解决这些问题,引入了一种新的词表示方法—-词嵌入表示
2.1.3 词嵌入表示
与词的分布式表示类似,词嵌入表示(WordEmbedding)也使用一个连续、低维、稠密的向量来表示词,经常直接简称为词向量,但与分布式表示不同之处在于其赋值方式。
词嵌入与词的分布式表示的区别
词的分布式表示:向量值是通过对语料库进行统计得到的,然后再经过点互信息、奇异值分解等变换,一旦确定则无法修改。
WordEmbedding:向量值是随着目标任务的优化过程自动调整的,也就是说,可以将词向量中的向量值看作模型的参数。
缺点:如果目标任务的训练数据比较少,学习合适的词向量难度会比较大。
因此,利用自然语言文本中所蕴含的自监督学习信号(即词与上下文的共现信息),先来预训练词向量,往往会获得更好的结果。
2.1.4文本的词袋表示
如何通过词的表示构成更长文本的表示呢?
在此介绍一种最简单的文本表示方法——词袋(Bag-Of-Words,BOW)表示。
所谓词袋表示,就是假设文本中的词语是没有顺序的集合,将文本中的全部词所对应的向量表示(既可以是独热表示,也可以是分布式表示或词向量)相加,即构成了文本的向量表示。
优点:非常简单、直观
缺点:没有考虑词的顺序信息;无法融入上下文信息;随着词表的增大,会引入更严重的数据稀疏问题。
深度学习技术的引入为解决这一问题提供了更好的方案。
2.2 自然语言处理任务
2.2.1语言模型
语言模型(Language Model,LM)(也称统计语言模型)是描述自然语言概率分布的模型,是一个基础和重要的自然语言处理任务。
语言模型能做什么?
- 可以计算一个词序列或一句话的概率,
- 可以在给定上文的条件下对接下来可能出现的词进行概率分布的估计。
- 可以进行预训练,语言模型是一项天然的预训练任务
1.N元语言模型(N-gram Language Model)
【N元语言模型概念待补充】
2.平滑
虽然马尔可夫假设(下一个词出现的概率只依赖于它前面n−1个词)降低了句子概率为0的可能性,但是当n比较大或者测试句子中含有未登录词(Out-Of-Vocabulary,OOV)时,仍然会出现“零概率”问题。为了避免该问题,需要使用平滑(Smoothing)技术调整概率估计的结果。
1).折扣法(Discounting)平滑的基本思想是“损有余而补不足”,即从频繁出现的N-gram中匀出一部分概率并分配给低频次(含零频次)的N-gram,从而使得整体概率分布趋于均匀。
2).加1平滑(Add-one Discounting)是一种典型的折扣法,也被称为拉普拉斯平滑(LaplaceSmoothing),它假设所有N-gram的频次比实际出现的频次多一次。
关于平滑的相关资料:…
3.语言模型性能评价
如何衡量一个语言模型的好坏呢?
一种方法是将其应用于具体的外部任务(如机器翻译),并根据该任务上指标的高低对语言模型进行评价。这种方法也被称为“外部任务评价”,是最接近实际应用需求的一种评价方法,但计算代价较高,实现难度较大。
目前最为常用的是基于困惑度(Perplexity,PPL)的“内部评价”方式。
【困惑度概念待补充】
2.2.2基础任务
基础任务往往是语言学家根据内省的方式定义的,输出的结果往往作为整个系统的一个环节或者下游任务的额外语言学特征,而并非面向普罗大众。
1.中文分词
词(Word)是最小的能独立使用的音义结合体,是能够独立运用并能够表达语义或语用内容的最基本单元。
注意:
- 以英语为代表的印欧语系(Indo-European lan-guages)中,词之间通常用分隔符(空格等)区分。
- 以汉语为代表的汉藏语系(Sino-Tibetan languages),以及以阿拉伯语为代表的闪-含语系(Semito-Hamiticlanguages)中,却不包含明显的词之间的分隔符,为了进行后续的自然语言处理,通常需要首先对不含分隔符的语言进行分词(Word Segmentation)操作。
最简单的分词算法正向最大匹配(Forward Maximum Matching,FMM)
代码展示:
待补充
正向最大匹配分词算法存在的明显缺点是倾向于切分出较长的词,这容易导致错误的切分结果。
切分歧义问题
同一个句子可能存在多种分词结果,一旦分词错误,则会影响对句子的语义理解。
未登录词问题
有一些词并没有收录在词典中,如新词、命名实体、领域相关词和拼写错误词等。
一个好的分词系统必须能够较好地处理未登录词问题。相比于切分歧义问题,在真实应用环境中,由未登录词问题引起的分词错误比例更高。
2.2.3应用任务
自然语言处理应用任务可以直接或间接地以产品的形式为终端用户提供服务,是自然语言处理研究应用落地的主要技术。例如信息抽取、情感分析、问答系统、机器翻译和对话系统等。
1.信息抽取
2.情感分析
3.问答系统
4.机器翻译
5.对话系统
2.3基本问题
2.3.1文本分类问题
2.3.2结构预测问题
2.3.3序列到序列问题
2.4 评价指标
习题

若有收获,就点个赞吧
0 人点赞
