快速安装 simpletransformers
simpletransformers 项目地址:https://hub.fastgit.org/ThilinaRajapakse/simpletransformers
simpletransformers 文档地址:
https://simpletransformers.ai/
快速安装方式:
- 使用Conda安装
1)新建虚拟环境
conda create -n st python pandas tqdmconda activate st
2)安装cuda环境
conda install pytorch>=1.6 cudatoolkit=11.0 -c pytorch
3)安装 simpletransformers
pip install simpletransformers
4) 安装 wandb
wandb 用于在web浏览器中追踪和可视化Weights和Biases(wandb)
pip install wandb
目前支持的任务:
| 任务 | 模型 |
|---|---|
| 二元和多类文本分类 | ClassificationModel |
| 对话式人工智能(聊天机器人训练) | ConvAIModel |
| 语言生成 | LanguageGenerationModel |
| 语言模型训练/微调 | LanguageModelingModel |
| 多标签文本分类 | MultiLabelClassificationModel |
| 多模态分类(文本和图像数据结合) | MultiModalClassificationModel |
| 命名实体识别 | NERModel |
| 问答 | QuestionAnsweringModel |
| 回归 | ClassificationModel |
| 句子对分类 | ClassificationModel |
| 文本表示生成 | RepresentationModel |
预训练模型去哪里下载?
有关预训练模型,请参阅Hugging Face 文档。
根据文档中给出的model_type,只要在args中正确设置model_name的字典值就是可以加载预训练模型
【实践01】文本分类
数据集
笔者选用CLUE的作为benchmark数据集
选取数据集:
(1)TNEWS’ 今日头条中文新闻(短文)分类
(2)IFLYTEK’ 长文本分类
中文语言理解测评基准(CLUE)
https://www.cluebenchmarks.com/dataSet_search.html
为更好的服务中文语言理解、任务和产业界,做为通用语言模型测评的补充,通过搜集整理发布中文任务及标准化测评等方式完善基础设施,最终促进中文NLP的发展。
Update: CLUE论文被计算语言学国际会议 COLING2020高分录用
- IFLYTEK’ 长文本分类
下载地址:https://github.com/CLUEbenchmark/CLUE
该数据集共有1.7万多条关于app应用描述的长文本标注数据,包含和日常生活相关的各类应用主题,共119个类别:”打车”:0,”地图导航”:1,”免费WIFI”:2,”租车”:3,….,”女性”:115,”经营”:116,”收款”:117,”其他”:118(分别用0-118表示)。每一条数据有三个属性,从前往后分别是 类别ID,类别名称,文本内容。
数据量:训练集(12,133),验证集(2,599),测试集(2,600)
{"label": "110","label_des": "社区超市","sentence": "朴朴快送超市创立于2016年,专注于打造移动端30分钟即时配送一站式购物平台,商品品类包含水果、蔬菜、肉禽蛋奶、海鲜水产、粮油调味、酒水饮料、休闲食品、日用品、外卖等。朴朴公司希望能以全新的商业模式,更高效快捷的仓储配送模式,致力于成为更快、更好、更多、更省的在线零售平台,带给消费者更好的消费体验,同时推动中国食品安全进程,成为一家让社会尊敬的互联网公司。,朴朴一下,又好又快,1.配送时间提示更加清晰友好2.保障用户隐私的一些优化3.其他提高使用体验的调整4.修复了一些已知bug"}
数据处理
Simple Transformers要求数据必须包含在至少两列的Pandas DataFrames中。 只需为列的文本和标签命名,SimpleTransformers就会处理数据。
第一列包含文本,类型为str。
第二列包含标签,类型为int。
对于多类分类,标签应该是从0开始的整数。
import jsonimport pandas as pddef load_clue_iflytek(path,mode=None):"""适应simpletransformer的加载方式"""data = []with open(path, "r", encoding="utf-8") as fp:if mode == 'train' or mode =='dev':for idx, line in enumerate(fp):line = json.loads(line.strip())label = int(line["label"])text = line['sentence']data.append([text, label])data_df = pd.DataFrame(data, columns=["text", "labels"])return data_dfelif mode == 'test':for idx, line in enumerate(fp):line = json.loads(line.strip())text = line['sentence']data.append([text])data_df = pd.DataFrame(data, columns=["text"])return data_df
模型搭建和训练
先进行参数配置,Simple Transformers具有dict args, 有关每个args的详细说明,可有参考:https://simpletransformers.ai/docs/tips-and-tricks/
1)参数配置
# 配置configimport argparsedef data_config(parser):parser.add_argument("--trainset_path", type=str, default="data/Chinese_Spam_Message/train.json",help="训练集路径")parser.add_argument("--testset_path", type=str, default="data/Chinese_Spam_Message/test.txt",help="测试集路径")parser.add_argument("--reprocess_input_data", type=bool, default=True,help="如果为True,则即使cache_dir中存在输入数据的缓存文件,也将重新处理输入数据")parser.add_argument("--overwrite_output_dir", type=bool, default=True,help="如果为True,则训练后的模型将保存到ouput_dir,并将覆盖同一目录中的现有已保存模型")parser.add_argument("--use_cached_eval_features", type=bool, default=True,help="训练期间的评估使用缓存特征,将此设置为False将导致在每个评估步骤中重新计算特征")parser.add_argument("--output_dir", type=str, default="outputs/",help="存储所有输出,包括模型checkpoints和评估结果")parser.add_argument("--best_model_dir", type=str, default="outputs/best_model/",help="保存评估过程中的最好模型")return parserdef model_config(parser):parser.add_argument("--max_seq_length", type=int, default=64,help="模型支持的最大序列长度")parser.add_argument("--model_type", type=str, default="bert",help="模型类型bert/roberta")# 要加载以前保存的模型而不是默认模型的模型,可以将model_name更改为包含已保存模型的目录的路径。parser.add_argument("--model_name", type=str, default="./outputs/bert",help="选择使用哪个预训练模型")parser.add_argument("--manual_seed", type=int, default=0,help="为了产生可重现的结果,需要设置随机种子")parser.add_argument("--learning_rate", type=int, default=4e-5,help="学习率")return parserdef train_config(parser):parser.add_argument("--num_train_epochs", type=int, default=3,help="模型训练迭代数")parser.add_argument("--wandb_kwargs", type=dict, default={"name": "bert"},help="")parser.add_argument("--n_gpu", type=int, default=1,help="训练时使用的GPU个数")parser.add_argument("--train_batch_size", type=int, default=64)parser.add_argument("--eval_batch_size", type=int, default=32)return parserdef set_args():parser = argparse.ArgumentParser()parser = data_config(parser)parser = model_config(parser)parser = train_config(parser)args,_ = parser.parse_known_args()return args
2)模型搭建和训练
from simpletransformers.classification import ClassificationModelfrom sklearn.metrics import f1_score, accuracy_scoreimport loggingdef f1_multiclass(labels, preds):return f1_score(labels, preds, average='micro')# 创建分类模型model = ClassificationModel(args.model_type, args.model_name, num_labels=num_labels, args=vars(args))# 训练模型,并在训练时评估model.train_model(train,eval_df=dev)# 模型预测result, model_outputs, wrong_predictions = model.eval_model(dev, f1=f1_multiclass)# 模型预测predictions, raw_outputs = model.predict(test["text"][0])print(predictions)print(raw_outputs)
预测结果
为了保证能跑动,maxlen只用了64,也只训练了3轮,F1值的效果并不是很好
{"eval_loss" = 1.8086365330510024,"f1" = 0.5917660638707195,"mcc" = 0.5727319886339782}
完整代码
import jsonimport pandas as pdfrom simpletransformers.classification import ClassificationModelfrom sklearn.metrics import f1_score, accuracy_scoreimport loggingdef load_clue_iflytek(path,mode=None):"""适应simpletransformer的加载方式"""data = []with open(path, "r", encoding="utf-8") as fp:if mode == 'train' or mode =='dev':for idx, line in enumerate(fp):line = json.loads(line.strip())label = int(line["label"])text = line['sentence']data.append([text, label])data_df = pd.DataFrame(data, columns=["text", "labels"])return data_dfelif mode == 'test':for idx, line in enumerate(fp):line = json.loads(line.strip())text = line['sentence']data.append([text])data_df = pd.DataFrame(data, columns=["text"])return data_df# 配置configimport argparsedef data_config(parser):parser.add_argument("--trainset_path", type=str, default="data/Chinese_Spam_Message/train.json",help="训练集路径")parser.add_argument("--testset_path", type=str, default="data/Chinese_Spam_Message/test.txt",help="测试集路径")parser.add_argument("--reprocess_input_data", type=bool, default=True,help="如果为True,则即使cache_dir中存在输入数据的缓存文件,也将重新处理输入数据")parser.add_argument("--overwrite_output_dir", type=bool, default=True,help="如果为True,则训练后的模型将保存到ouput_dir,并将覆盖同一目录中的现有已保存模型")parser.add_argument("--use_cached_eval_features", type=bool, default=True,help="训练期间的评估使用缓存特征,将此设置为False将导致在每个评估步骤中重新计算特征")parser.add_argument("--output_dir", type=str, default="outputs/",help="存储所有输出,包括模型checkpoints和评估结果")parser.add_argument("--best_model_dir", type=str, default="outputs/best_model/",help="保存评估过程中的最好模型")return parserdef model_config(parser):parser.add_argument("--max_seq_length", type=int, default=64,help="模型支持的最大序列长度")parser.add_argument("--model_type", type=str, default="bert",help="模型类型bert/roberta")# 要加载以前保存的模型而不是默认模型的模型,可以将model_name更改为包含已保存模型的目录的路径。parser.add_argument("--model_name", type=str, default="./outputs/bert",help="选择使用哪个预训练模型")parser.add_argument("--manual_seed", type=int, default=0,help="为了产生可重现的结果,需要设置随机种子")parser.add_argument("--learning_rate", type=int, default=4e-5,help="学习率")return parserdef train_config(parser):parser.add_argument("--num_train_epochs", type=int, default=3,help="模型训练迭代数")parser.add_argument("--wandb_kwargs", type=dict, default={"name": "bert"},help="")parser.add_argument("--n_gpu", type=int, default=1,help="训练时使用的GPU个数")parser.add_argument("--train_batch_size", type=int, default=64)parser.add_argument("--eval_batch_size", type=int, default=32)return parserdef set_args():parser = argparse.ArgumentParser()parser = data_config(parser)parser = model_config(parser)parser = train_config(parser)args,_ = parser.parse_known_args()return argsdef f1_multiclass(labels, preds):return f1_score(labels, preds, average='micro')if __name__ == "__main__":args = set_args()logging.basicConfig(level=logging.INFO)transformers_logger = logging.getLogger("transformers")transformers_logger.setLevel(logging.WARNING)# 模型训练train = load_clue_iflytek("./data/iflytek/train.json", mode='train')dev = load_clue_iflytek("./data/iflytek/dev.json", mode='dev')test = load_clue_iflytek("./data/iflytek/test.json", mode='test')num_labels = len(train["labels"].unique())print(train.shape)print(dev.shape)# 创建分类模型model = ClassificationModel(args.model_type, args.model_name, num_labels=num_labels, args=vars(args))# 训练模型,并在训练时评估model.train_model(train,eval_df=dev)# 模型预测result, model_outputs, wrong_predictions = model.eval_model(dev, f1=f1_multiclass)
Simpletransformers上手快,但只偏向于快速应用或者写baseline,需要更改模型结构灵活组合方法还是需要掌握transformer等自由度高的python库
NLP萌新,才疏学浅,有错误或者不完善的地方,请批评指正!!
【实践02】命名实体识别
数据集
笔者选用CLUE的作为benchmark数据集
选取数据集:
(1)CLUE Fine-Grain NER
中文语言理解测评基准(CLUE)
https://www.cluebenchmarks.com/dataSet_search.html
本数据是在清华大学开源的文本分类数据集THUCTC基础上,选出部分数据进行细粒度命名实体标注,原数据来源于Sina News RSS.
训练集:10748, 验证集:1343,标签类别:10个
标签分别为:
- 地址(address)
- 书名(book)
- 公司(company)
- 游戏(game)
- 政府(goverment)
- 电影(movie)
- 姓名(name)
- 组织机构(organization)
- 职位(position)
- 景点(scene)
cluener下载链接:数据下载
任务详情:CLUENER2020
{"text": "浙商银行企业信贷部叶老桂博士则从另一个角度对五道门槛进行了解读。叶老桂认为,对目前国内商业银行而言,","label": {"name": {"叶老桂": [[9, 11]]},"company": {"浙商银行": [[0, 3]]}}}{"text": "生生不息CSOL生化狂潮让你填弹狂扫","label": {"game": {"CSOL": [[4, 7]]}}}
标签定义与规则:
地址(address): 省市区街号,路,街道,村等(如单独出现也标记),注意:地址需要标记完全, 标记到最细。
书名(book): 小说,杂志,习题集,教科书,教辅,地图册,食谱,书店里能买到的一类书籍,包含电子书。
公司(company): 公司,集团,**银行(央行,中国人民银行除外,二者属于政府机构), 如:新东方,包含新华网/中国军网等。
游戏(game): 常见的游戏,注意有一些从小说,电视剧改编的游戏,要分析具体场景到底是不是游戏。
政府(goverment): 包括中央行政机关和地方行政机关两级。 中央行政机关有国务院、国务院组成部门(包括各部、委员会、中国人民银行和审计署)、国务院直属机构(如海关、税务、工商、环保总局等),军队等。
电影(movie): 电影,也包括拍的一些在电影院上映的纪录片,如果是根据书名改编成电影,要根据场景上下文着重区分下是电影名字还是书名。
姓名(name): 一般指人名,也包括小说里面的人物,宋江,武松,郭靖,小说里面的人物绰号:及时雨,花和尚,著名人物的别称,通过这个别称能对应到某个具体人物。
组织机构(organization): 篮球队,足球队,乐团,社团等,另外包含小说里面的帮派如:少林寺,丐帮,铁掌帮,武当,峨眉等。
职位(position): 古时候的职称:巡抚,知州,国师等。现代的总经理,记者,总裁,艺术家,收藏家等。
景点(scene): 常见旅游景点如:长沙公园,深圳动物园,海洋馆,植物园,黄河,长江等。
数据处理
Simple Transformers要求数据必须包含在至少三列的Pandas DataFrames中。
需为列的句子id、文本和标签命名,SimpleTransformers就会处理数据。
第一列包含句子id,类型为int。
第二列包含单词,类型为str。
第二列包含标签,类型为int。
import jsonimport pandas as pddef load_cluener2020_data(path):"""适应simpletransformer的加载方式"""data = []labels_list = []with open(path, "r", encoding="utf-8") as f:for idx, line in enumerate(f):line = json.loads(line.strip())text = line["text"]label_entities = line.get("label", None)words = list(text)labels = ['O'] * len(words)if label_entities:for key, value in label_entities.items():for sub_name, sub_index in value.items():for start_index, end_index in sub_index:assert "".join(words[start_index:end_index+1]) == sub_nameif start_index == end_index:labels[start_index] = "S-" + keyelse:labels[start_index] = "B-" + keylabels[start_index+1:end_index+1] = ["I-"+key] * (len(sub_name) - 1)for word, label in zip(words, labels):data.append([idx, word, label])if label not in labels_list:labels_list.append(label)data_df = pd.DataFrame(data, columns=["sentence_id", "words", "labels"])return data_df, labels_list
处理完后的形式如下:
模型搭建和训练
先进行参数配置,Simple Transformers具有dict args, 有关每个args的详细说明,可有参考:https://simpletransformers.ai/docs/tips-and-tricks/
1)参数配置
# 配置configimport argparsedef data_config(parser):parser.add_argument("--trainset_path", type=str, default="data/CLUENER2020/train.json",help="训练集路径")parser.add_argument("--devset_path", type=str, default="data/CLUENER2020/dev.json",help="验证集路径")parser.add_argument("--testset_path", type=str, default="data/CLUENER2020/test.json",help="测试集路径")parser.add_argument("--reprocess_input_data", type=bool, default=True,help="如果为True,则即使cache_dir中存在输入数据的缓存文件,也将重新处理输入数据")parser.add_argument("--overwrite_output_dir", type=bool, default=True,help="如果为True,则训练后的模型将保存到ouput_dir,并将覆盖同一目录中的现有已保存模型")parser.add_argument("--use_cached_eval_features", type=bool, default=True,help="训练期间的评估使用缓存特征,将此设置为False将导致在每个评估步骤中重新计算特征")parser.add_argument("--output_dir", type=str, default="outputs/",help="存储所有输出,包括模型checkpoints和评估结果")parser.add_argument("--best_model_dir", type=str, default="outputs/best_model/",help="保存评估过程中的最好模型")return parserdef model_config(parser):parser.add_argument("--max_seq_length", type=int, default=200,help="模型支持的最大序列长度")parser.add_argument("--model_type", type=str, default="bert",help="模型类型bert/roberta")parser.add_argument("--model_name", type=str, default="../pretrainmodel/bert",help="选择使用哪个预训练模型")parser.add_argument("--manual_seed", type=int, default=2021,help="为了产生可重现的结果,需要设置随机种子")return parserdef train_config(parser):parser.add_argument("--evaluate_during_training", type=bool, default=True,help="设置为True以在训练模型时执行评估,确保评估数据已传递到训练方法")parser.add_argument("--num_train_epochs", type=int, default=3,help="模型训练迭代数")parser.add_argument("--evaluate_during_training_steps", type=int, default=100,help="在每个指定的step上执行评估,checkpoint和评估结果将被保存")parser.add_argument("--save_eval_checkpoints", type=bool, default=True)parser.add_argument("--save_model_every_epoch", type=bool, default=True,help="每次epoch保存模型")parser.add_argument("--n_gpu", type=int, default=1,help="训练时使用的GPU个数")parser.add_argument("--train_batch_size", type=int, default=16)parser.add_argument("--eval_batch_size", type=int, default=8)return parserdef set_args():parser = argparse.ArgumentParser()parser = data_config(parser)parser = model_config(parser)parser = train_config(parser)args,unknown = parser.parse_known_args()return args
2)模型搭建和训练
import loggingfrom simpletransformers.ner import NERModel# 可从训练集获取labels_list = ["B-company", "I-company", 'O', "B-name", "I-name","B-game", "I-game", "B-organization", "I-organization","B-movie", "I-movie", "B-position", "I-position","B-address", "I-address", "B-government", "I-government","B-scene", "I-scene", "B-book", "I-book","S-company", "S-address", "S-name", "S-position"]# 训练args = set_args()logging.basicConfig(level=logging.INFO)transformers_logger = logging.getLogger("transformers")transformers_logger.setLevel(logging.WARNING)# 读取数据train_df, labels_list = load_cluener2020_data(args.trainset_path)dev_df, _ = load_cluener2020_data(args.devset_path)# 创建命名实体识别模型model = NERModel(args.model_type, args.model_name, labels=labels_list, args=vars(args))model.save_model(model=model.model) # 可以将预训练模型下载到output_dir# 训练模型,并在训练时评估model.train_model(train_df, eval_data=dev_df)
预测结果
训练3轮,最佳F1值0.772964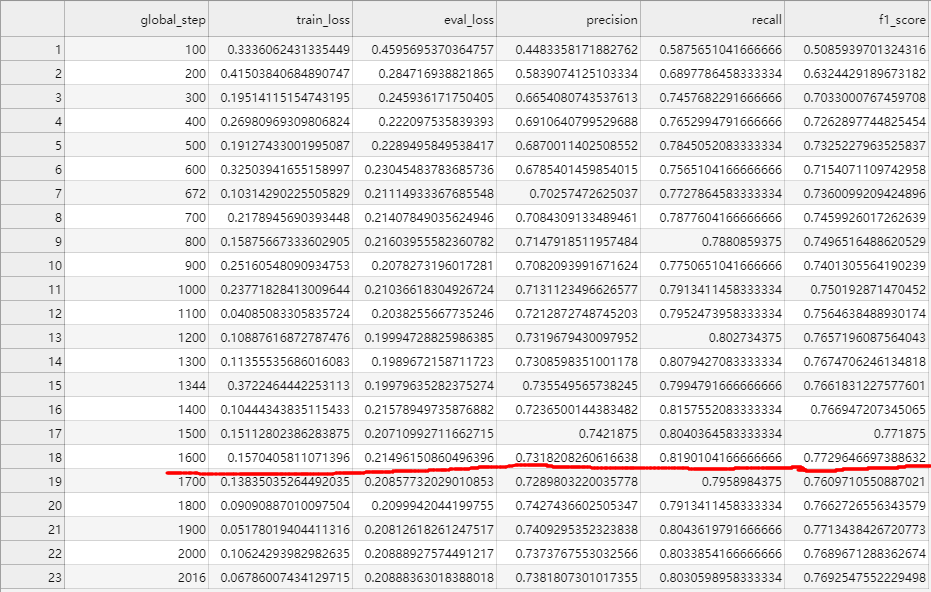
完整代码
import jsonimport argparseimport numpy as npimport pandas as pdimport loggingfrom simpletransformers.ner import NERModeldef data_config(parser):parser.add_argument("--trainset_path", type=str, default="data/CLUENER2020/train.json",help="训练集路径")parser.add_argument("--devset_path", type=str, default="data/CLUENER2020/dev.json",help="验证集路径")parser.add_argument("--testset_path", type=str, default="data/CLUENER2020/test.json",help="测试集路径")parser.add_argument("--reprocess_input_data", type=bool, default=True,help="如果为True,则即使cache_dir中存在输入数据的缓存文件,也将重新处理输入数据")parser.add_argument("--overwrite_output_dir", type=bool, default=True,help="如果为True,则训练后的模型将保存到ouput_dir,并将覆盖同一目录中的现有已保存模型")parser.add_argument("--use_cached_eval_features", type=bool, default=True,help="训练期间的评估使用缓存特征,将此设置为False将导致在每个评估步骤中重新计算特征")parser.add_argument("--output_dir", type=str, default="outputs/",help="存储所有输出,包括模型checkpoints和评估结果")parser.add_argument("--best_model_dir", type=str, default="outputs/best_model/",help="保存评估过程中的最好模型")return parserdef model_config(parser):parser.add_argument("--max_seq_length", type=int, default=200,help="模型支持的最大序列长度")parser.add_argument("--model_type", type=str, default="bert",help="模型类型bert/roberta")parser.add_argument("--model_name", type=str, default="../pretrainmodel/bert",help="选择使用哪个预训练模型")parser.add_argument("--manual_seed", type=int, default=2021,help="为了产生可重现的结果,需要设置随机种子")return parserdef train_config(parser):parser.add_argument("--evaluate_during_training", type=bool, default=True,help="设置为True以在训练模型时执行评估,确保评估数据已传递到训练方法")parser.add_argument("--num_train_epochs", type=int, default=3,help="模型训练迭代数")parser.add_argument("--evaluate_during_training_steps", type=int, default=100,help="在每个指定的step上执行评估,checkpoint和评估结果将被保存")parser.add_argument("--save_eval_checkpoints", type=bool, default=True)parser.add_argument("--save_model_every_epoch", type=bool, default=True,help="每次epoch保存模型")parser.add_argument("--n_gpu", type=int, default=1,help="训练时使用的GPU个数")parser.add_argument("--train_batch_size", type=int, default=16)parser.add_argument("--eval_batch_size", type=int, default=8)return parserdef set_args():parser = argparse.ArgumentParser()parser = data_config(parser)parser = model_config(parser)parser = train_config(parser)args,unknown = parser.parse_known_args()return argsdef load_cluener2020_data(path):"""适应simpletransformer的加载方式"""data = []labels_list = []with open(path, "r", encoding="utf-8") as f:for idx, line in enumerate(f):line = json.loads(line.strip())text = line["text"]label_entities = line.get("label", None)words = list(text)labels = ['O'] * len(words)if label_entities:for key, value in label_entities.items():for sub_name, sub_index in value.items():for start_index, end_index in sub_index:assert "".join(words[start_index:end_index+1]) == sub_nameif start_index == end_index:labels[start_index] = "S-" + keyelse:labels[start_index] = "B-" + keylabels[start_index+1:end_index+1] = ["I-"+key] * (len(sub_name) - 1)for word, label in zip(words, labels):data.append([idx, word, label])if label not in labels_list:labels_list.append(label)data_df = pd.DataFrame(data, columns=["sentence_id", "words", "labels"])return data_df, labels_listdef train_model():# 可从训练集获取labels_list = ["B-company", "I-company", 'O', "B-name", "I-name","B-game", "I-game", "B-organization", "I-organization","B-movie", "I-movie", "B-position", "I-position","B-address", "I-address", "B-government", "I-government","B-scene", "I-scene", "B-book", "I-book","S-company", "S-address", "S-name", "S-position"]# 训练args = set_args()logging.basicConfig(level=logging.INFO)transformers_logger = logging.getLogger("transformers")transformers_logger.setLevel(logging.WARNING)# 读取数据train_df, labels_list = load_cluener2020_data(args.trainset_path)dev_df, _ = load_cluener2020_data(args.devset_path)print(train_df.head(10))print(dev_df.head(10))# 创建命名实体识别模型model = NERModel(args.model_type, args.model_name, labels=labels_list, args=vars(args))model.save_model(model=model.model) # 可以将预训练模型下载到output_dir# 训练模型,并在训练时评估model.train_model(train_df, eval_data=dev_df)if __name__ == '__main__':train_model()
Simpletransformers上手快,但只偏向于快速应用或者写baseline,需要更改模型结构灵活组合方法还是需要掌握transformer等自由度高的python库
NLP萌新,才疏学浅,有错误或者不完善的地方,请批评指正!!

若有收获,就点个赞吧
0 人点赞
