Welcome to my knowledge base!
我是Armor,这里是《Armor的自然语言处理实战》博客,课程图、文、代码形式展示。本博客主要用于教学和搭建一个可复用的基于深度学习框架pytorch的文本分类实践代码(非BERT模型)以及完成模型训练后如何基于flask简单地部署到web应用中,做成自己的小项目。教程将按照模型构建的流程分为7个阶段:
| 教程模块 | 内容 |
|---|---|
| 01.概述 | 概念介绍、主要内容概览 |
| 02.Config.py | 学习配置参数准备 |
| 03.DataSet.py | 学习使用Torchtext |
| 04.Model | 学习模型创建 |
| 05.train_fine_tune.py | 学习使用torch |
| 06.Classify | 学习预测 |
| 07.app.py | 学习部署 |
新增内容:
开源地址:https://github.com/Armorhtk/Text_Classification_Based_Torch_and_Simple_Deployment
开源地址下的内容有细微增改
新增内容:
修改了少量代码内容,适配词向量加载,在Config里修改是否要用词向量,用那种词向量即可
词向量使用腾讯实验室的800w语料的腾讯词向量的少量vocab【只截取了部分10000-small、50000-small、500000-large三种w2v】
【加载词向量版】项目源码:链接:https://pan.baidu.com/s/1f4U-tsz4oJODxsk9kq_t9g?pwd=2021 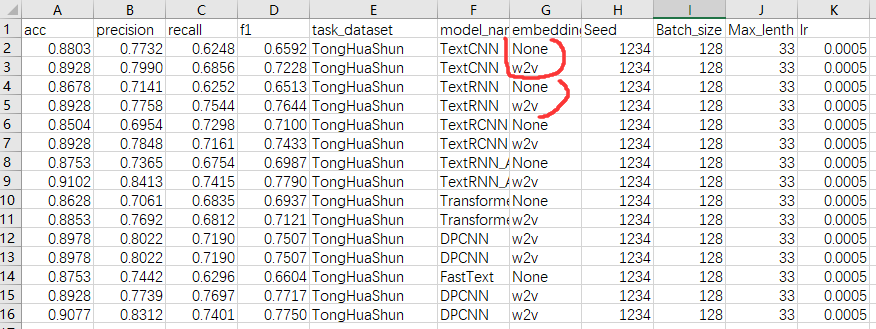
使用预训练词向量后,F1值有明显增长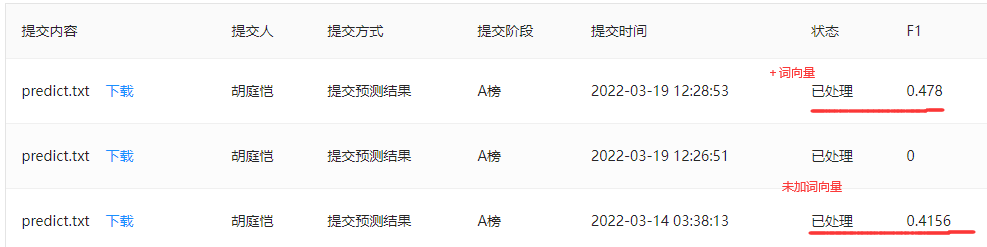
1 概述
1.1 torch版本问题
在开始教程前,先明检查一下torch版本的问题,如果已安装torch、torchtext并且gpu可以正常调用,则可以跳过本小节
一般在代码运行时,容易出现一下两种错误:
- 安装pytorch或torchtext时,无法找到对应版本
cuda可以找到,但是无法转为.cuda()
以上两种或类似错误,一般由两个原因可供分析:
cuda版本不合适,重新安装cuda和cudnn
- pytorch和torchtext版本没对应上
1)先查看自己cuda版本
打开conda命令窗口或者cmd,输入nvcc --version
锁定最后一行,cuda为11.0版本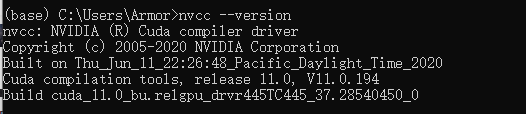
2)根据cuda查询对应的torch、torchtext版本
建议安装1.7.0及以上版本,以前的版本或多或少有bug,下图是python、pytorch、torchvison(torchtext版本和其一致)和cuda的版本对应关系:
笔者的python环境为3.7版本,cuda是11.0,我安装的是torch1.8.0,torchtext0.9.0。
3)下载和安装,不建议pip安装速度慢易出错,直接去网站下载whl文件,安装快不报错
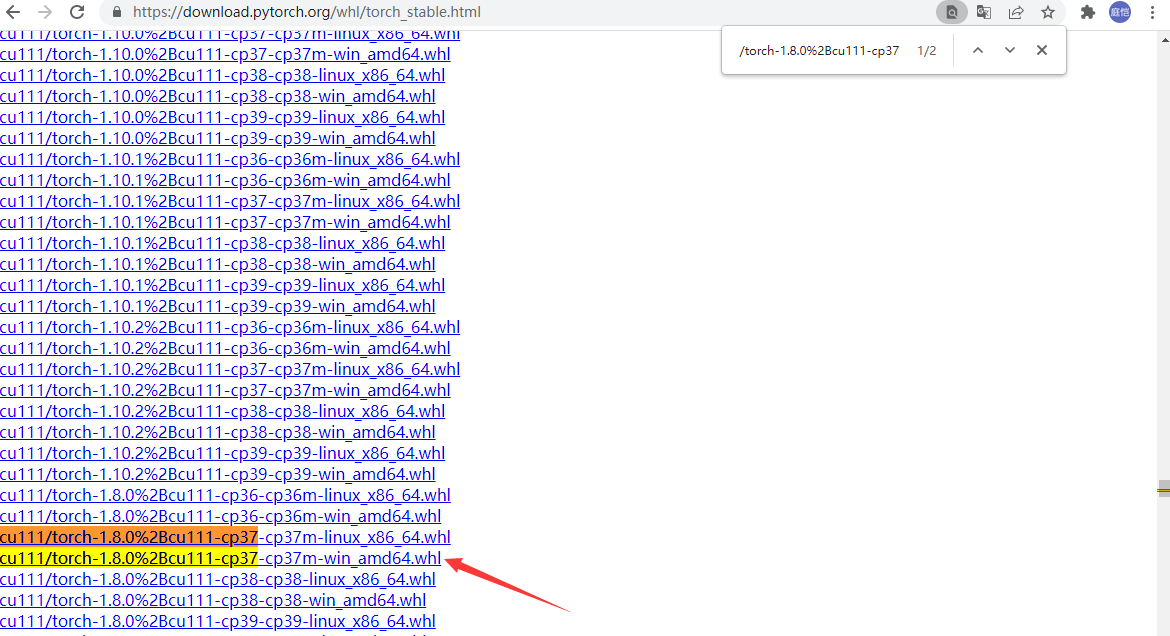
下载地址 https://download.pytorch.org/whl/torch_stable.html
直接使用ctrl+F去检索对应版本和关键词,例如cu111/torch-1.8.0,出现多个结果,cpxx表示python环境,后面则是操作系统,这里选cp37和win_amd64版本,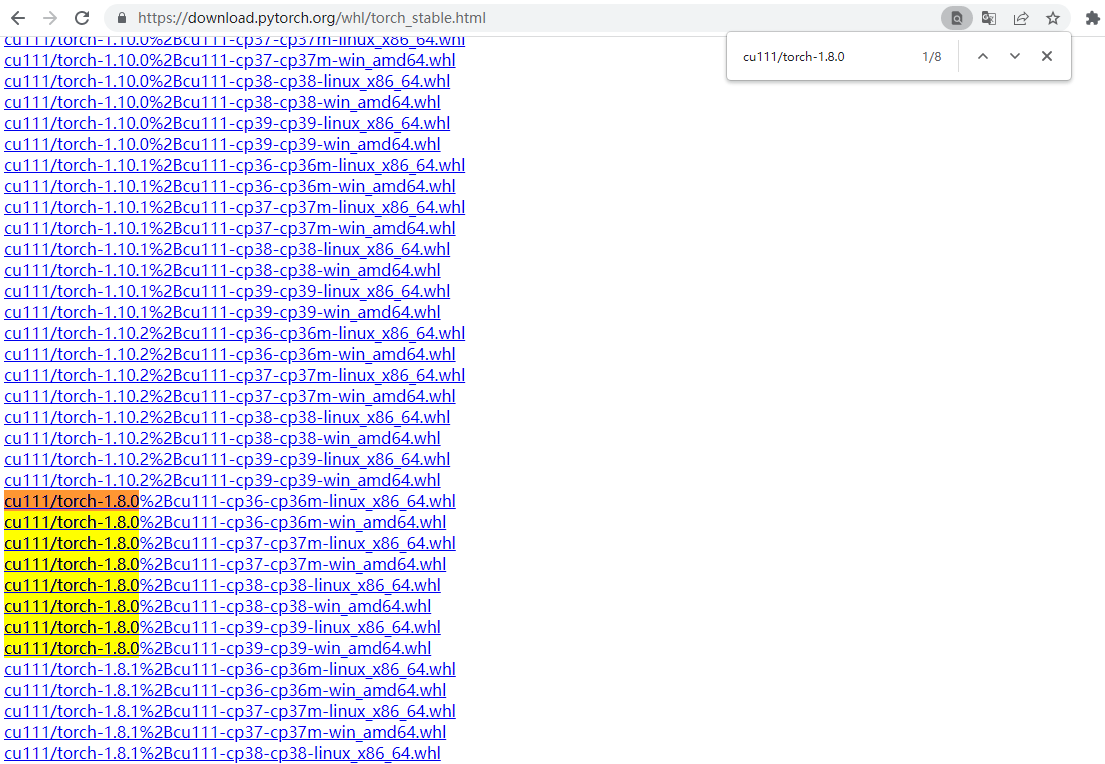
下载完成后直接,pip安装whl文件即可
pip insatll 你的下载路径\xxx.whl
1.2 先学部署就是玩
1) 搭建Web界面
配置完环境估计已经学累了,学习是痛苦的事情,不如先点无脑copy体会一下学完之后的部署效果,激发一下学习动力!!!
完成深度学习的文本分类模型训练后,保存训练好的最佳模型部署到web上供他人使用,先下载templates.zip,里面提供一个简陋的前端响应界面,前端界面和功能可以自行优化,我们只有一个需求就是针对用户输入的文本,返回该文本的模型预测类别和类别概率分布。templates.zip链接:https://pan.baidu.com/s/1Tr8m0BdLw2zDtnuvH95F-Q?pwd=2021
具体步骤:
1.定位到当前项目根目录下,解压templates.zip得到templates文件夹,文件夹中包含index.html(首页)、css、images
2.当前项目根目录下,创建app.py,输入如下内容:
import randomfrom flask import Flask, render_template, requestapp=Flask(__name__,template_folder='templates',static_folder="templates",static_url_path='')# 模型预测函数def model_predict(text):# 该函数一般写在别的py文件中,这里只是一个演示示例,方便展示response = {}rand1 = random.random()response["dog"] = round(rand1,4)response["cat"] = round(1-rand1,4)results = {value:key for key,value in response.items()}result = results[max(results.keys())]return response,result# 前端表单数据获取和响应@app.route('/predict',methods=['GET','POST'])def predict():isHead = Falseif request.method == 'POST':sent1 = request.form.get('sentence1')sent2 = request.form.get('sentence2')text = sent1 + sent2# 通过预测函数得到响应,result是预测的标签,response是软标签logitsresponse,result = model_predict(text)return render_template('index.html',isHead=isHead,sent1=sent1,sent2=sent2,response=response,result=result)# 首页加载@app.route('/',methods=['GET','POST'])def index():isHead = Truereturn render_template('index.html',isHead=isHead)# 主函数if __name__ == '__main__':app.run()
2) 本地部署和内网穿透
1.运行启动文件,可在本地运行
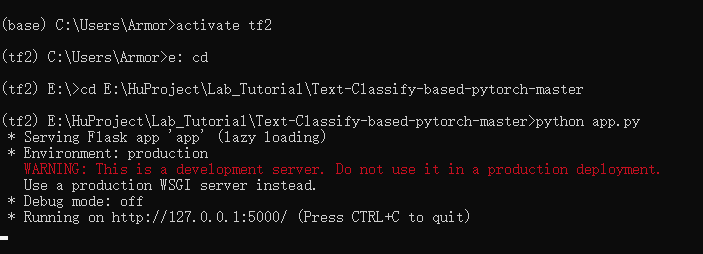
第一种:直接用pycharm启动,已知挂机
第二种:使用cmd命令,首先切换python环境为当前分类模型的环境,然后进入当前项目路径,最后在项目路径下运行如下代码(例子中以app.py作为启动名称),如图所示:
python app.py
2.使用Ngrok进行辅助内网穿透,让他人可访问
使用Ngrok仅为辅助方案,有云服务器最好可以自行部署
步骤1:打开Ngrok官网 https://dashboard.ngrok.com/
步骤2:按照Download提示下载ngrok,windows版本下载比较简单
步骤3:下载完毕按照官网三个小步骤进行安装和启动
第三步的“ngrok http 50”中的50表示穿透端口号,需要和flask设置的端口号一致,需要修改,上面flask使用的是默认5000作为端口号,部署是则为“ngrok http 5000”。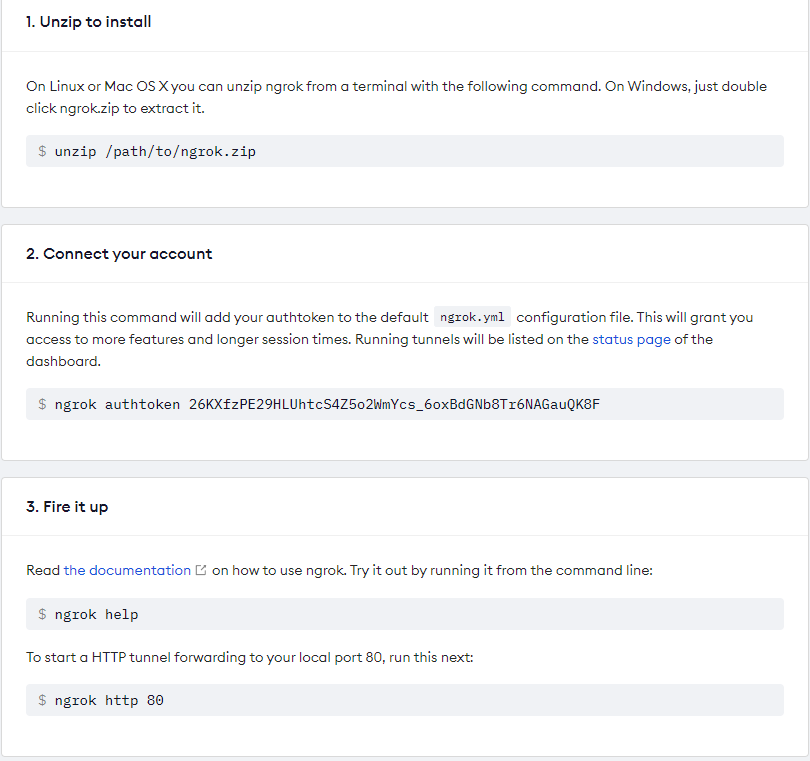
启动后,界面变更如下: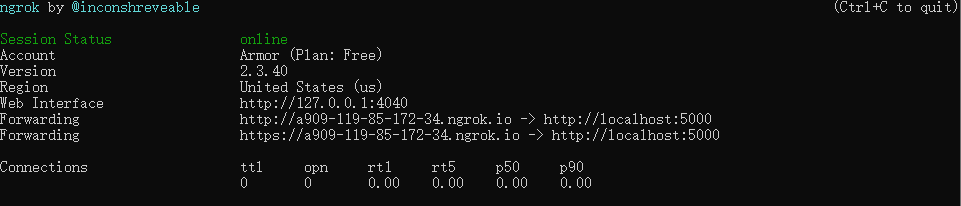
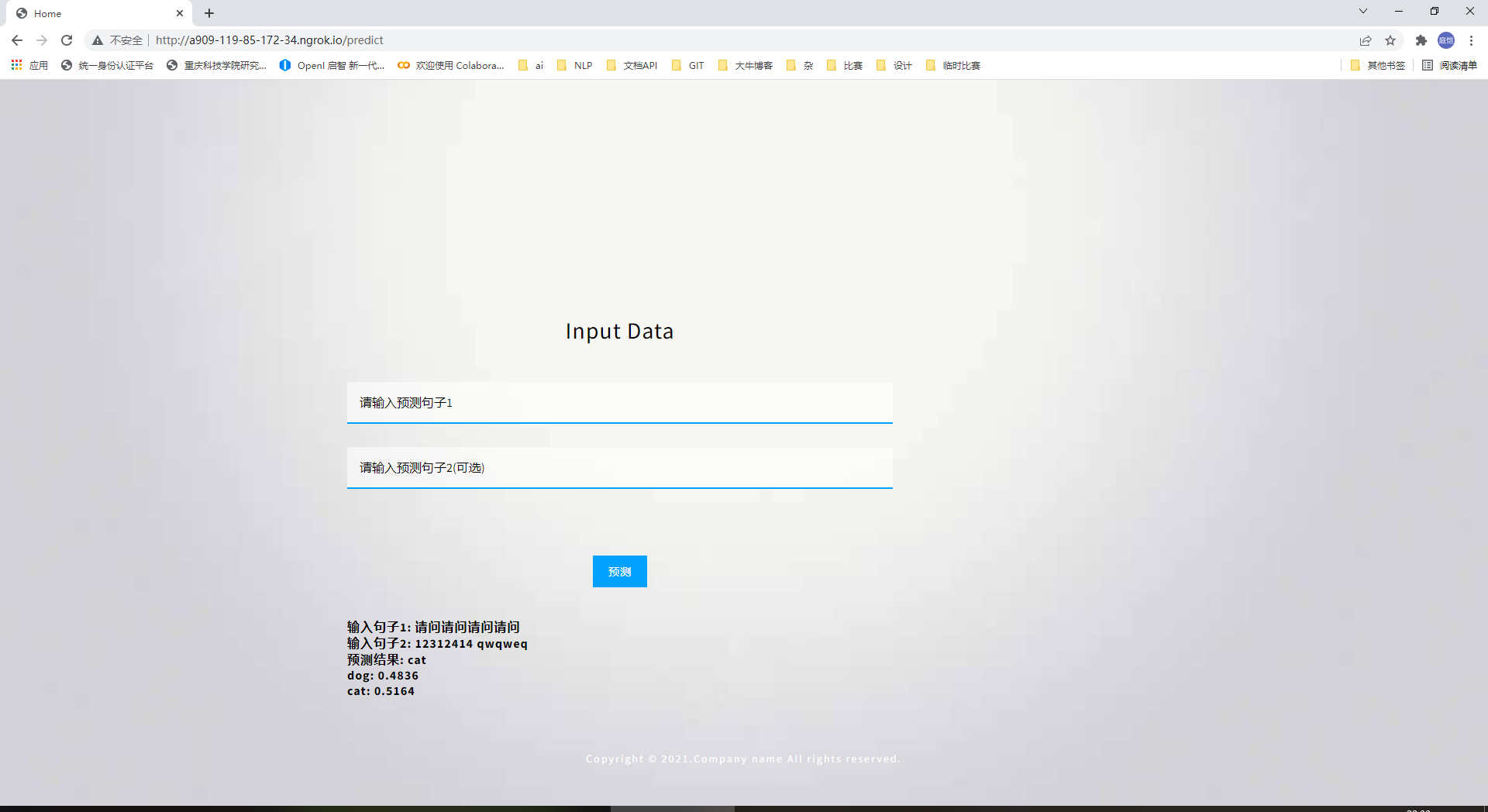
访问给的http或https可以让他人访问web页面:
http://a909-119-85-172-34.ngrok.iohttps://a909-119-85-172-34.ngrok.io
1.3 文本分类应用实现需要几步?
文本分类应用实现需要几步?
答:4步,读数据(Dataset) - 创建模型(model) - 训练模型(Train_fine_tune) - 预测数据(Classify)
如何实现框架的高复用
1.创建一个配置文件(Config)将所有的可变参数都写入这个文件中,后续改动只需要改动Config文件中的参数即可
2.功能不能写死,多用可变参数创造可变动的代码形式 or 多针对一些情况写一些工具函数Utils
3.设置好随机种子,写好文件读写和模型保存模块,方便复现同一种结果
2 Config 配置文件
为了提高代码的复用性,通常会创建一个Config配置文件,将经常要修改的数据参数、模型参数、训练参数、验证参数以变量的形式存取其中。
注意:不必在一开始就想到所有可以设置的变量,在构建工程的过程中Config里的内容会不断更新。
下图是一张配置文件示例: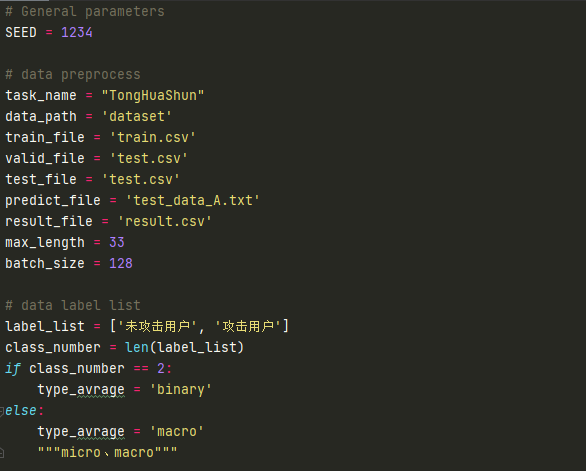
其中task_name表示数据集名字,若下次需要训练其他数据集时,只需要更改task_name变量的内容即可。其中还有很多文件夹的名字,例如train_file、test_file、valid_file将训练集、测试机、验证集可以提高代码的复用性,此时没新拿到一个数据集只需要写一个数据处理函数,将数据处理为上述三种名称即可run代码训练,不用从头开始构建代码。
配置文件本身没有什么知识点,但在工程体系中极为重要,是后续所有文件都会import的内容。
点击展开,Config完整代码:
# General parametersSEED = 1234# data preprocesstask_name = "TongHuaShun"data_path = 'dataset'train_file = 'train.csv'valid_file = 'test.csv'test_file = 'test.csv'predict_file = 'test_data_A.txt'result_file = 'result.csv'max_length = 33batch_size = 128# data label listlabel_list = ['未攻击用户', '攻击用户']class_number = len(label_list)if class_number == 2:type_avrage = 'binary'else:type_avrage = 'macro'"""micro、macro"""# train detailsepochs = 500learning_rate = 5e-4best_metric = "f1" # 可选acc、p、r、f1early_stopping_nums = 10# model listsmodel_name = "TextRNN"
3 Dataset 数据集
本节介绍使用torchtext构造符合torch格式的TabularDataset。
3.1 数据集长啥样
由于数据集形式各异,设计一种数据处理的通用方法非常困难。但不管是何种数据集经过处理之后均会变为
| text | label |
|---|---|
| 涨停出了,今天肯定封不上板了 | 未攻击用户 |
| 忽悠,继续忽悠 | 攻击用户 |
| …… | …… |
在开始加载数据集之前,可以在本项目下创建一个数据集目录,再在该数据集目录下创建不同任务的数据集文件夹,生成train.csv、valid.csv、test.csv格式的训练、验证、测试数据集。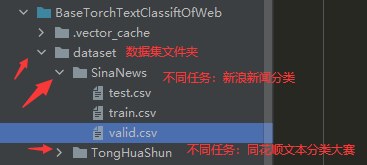
3.2 随机种子
随机种子对复现相同的结果有机器重要的作用,pytorch中添加如下代码:
import torchimport randomimport numpy as npfrom Config import *torch.manual_seed(SEED)torch.manual_seed(SEED)torch.cuda.manual_seed_all(SEED)np.random.seed(SEED)random.seed(SEED)torch.backends.cudnn.deterministic = True
3.3 分词和torchtext
1)jieba
使用结巴进行分词,先用正则仅保留所有中文字符,然后使用结巴lcut的分词,返回分词序列。
import jiebaimport redef x_tokenize(x):str = re.sub('[^\u4e00-\u9fa5]', "", x)return jieba.lcut(str)print(x_tokenize("A股涨停出了,今天肯定封不上板了 "))
结果如下:['股', '涨停', '出', '了', '今天', '肯定', '封不上', '板', '了']
补充:
分享一篇文章NLP分词PK大赏:开源分词组件对比及一骑红尘的jieba分词源码剖析
里面对开源分词软件进行了分析,经过评估发现jieba的性能最低,F值只有0.82左右,但结巴分词的优点是速度一骑红尘。感兴趣的小伙伴可以研究一下。
哈工大的LTP使用方法也开看我写的另一个帖子:
[3]使用pyltp进行分句、分词、词性标注、命名实体识别
2)torchtext
Torchtext的详解内容可以看这一篇知乎torchtext包含以下组件:
Field :主要包含以下数据预处理的配置信息,比如指定分词方法,是否转成小写,起始字符,结束字符,补全字符以及词典等等
Dataset :继承自pytorch的Dataset,用于加载数据,提供了TabularDataset可以指点路径,格式,Field信息就可以方便的完成数据加载。同时torchtext还提供预先构建的常用数据集的Dataset对象,可以直接加载使用,splits方法可以同时加载训练集,验证集和测试集。
Iterator : 主要是数据输出的模型的迭代器,可以支持batch定制
3)Field对象创建
简单理解,创建一个Field对象就是创建一个关于包含数据预处理信息的class对象。
代码流程:
- 针对
分别创建两个Field对象。
text作为文本内容,需要分词以列表的形式返回、需要设置截断长度、以及保存词典信息。
label作为标签内容,不需要分词以序列方式返回、也不需要截断以及保存词典信息。
- 定义两个简单的get函数以获取
TEXT、LABEL,方便后续从Config中调用。
以下是Field对象包含的参数:
sequential: 是否把数据表示成序列,如果是False, 不能使用分词 默认值: True.
fix_length: 修改每条数据的长度为该值,不够的用pad_token补全. 默认值: None.
tokenize: 分词函数. 默认值: str.split. 必须传入一个函数呦.
use_vocab: 是否使用词典对象. 如果是False 数据的类型必须已经是数值类型. 默认值: True.
pad_token: 用于补全的字符. 默认值: “
unk_token: 不存在词典里的字符. 默认值: “
import osfrom torchtext.legacy import data# 对文本内容和标签创建两个Field对象TEXT = data.Field(sequential=True,tokenize=x_tokenize,fix_length=max_length,use_vocab=True)LABEL = data.Field(sequential=False,use_vocab=False)def getTEXT():return TEXTdef getLabel():return LABEL
4)TabularDataset 数据集构造torchtext的Dataset是继承自pytorch的Dataset,提供了一个可以下载压缩数据并解压的方法(支持.zip, .gz, .tgz);splits方法可以同时读取训练集,验证集,测试集,TabularDataset可以很方便的读取CSV, TSV, or JSON格式的文件。
代码流程:
- 从
TabularDataset.splits中创建并分割出训练集、验证集以及测试集 - 加载完数据后可以,建立
TEXT的字典,建立词典时可以使用预训练的词向量(本文未使用词向量)
以下是TabularDataset.splits包含的参数:
path: 数据集文件夹的公共前缀
train: 训练集文件名
validation: 验证集文件名
test: 测试集文件名
format: 文件格式
skip_header: 是否跳过表头
csv_reader_params:数据集以何种符号进行划分
fields:传入的fields必须与列的顺序相同。对于不使用的列,在fields的位置传入一个None
# 创建TabularDataset并分割数据集train, dev, test = data.TabularDataset.splits(path=os.path.join(data_path,task_name),train=train_file,validation=valid_file,test=test_file,format='csv',skip_header=True,csv_reader_params={'delimiter':','},fields=[("text",TEXT),('label',LABEL)])# 构建字典TEXT.build_vocab(train)
4)iterator 数据迭代器Iterator是torchtext到模型的输出,它提供了我们对数据的一般处理方式,比如打乱,排序,等等,可以动态修改batch大小,这里也有splits方法 可以同时输出训练集,验证集,测试集。
代码中使用的是BucketIterator,相比Iterator它会将长度相近的数据放在一个batch中
BucketIterator为了使padding最少,会在batch之前先对整个dataset上的cases进行sort(按一定规则),将相近长度的case放在一起,这样一个batch中的cases长度相当,使得padding的个数最小。同时,为了每次能生成稍微不同的batch,在sort之前加入了noise进行长度的干扰。
代码流程:
- 从
BucketIterator.splits函数中分别创建训练集迭代器、验证集迭代器以及测试集迭代器 - 定义一个简单的get函数以获取迭代数据集,方便后续调用。
以下是BucketIterator.splits包含的参数:
dataset:加载的数据集
batch_size:batch的大小
shuffle:是否打乱数据
sort:是对全体数据按照升序顺序进行排序,而sort_within_batch仅仅对一个batch内部的数据进行排序。
sort_within_batch:参数设置为True时,按照sort_key按降序对每个小批次内的数据进行降序排序。
repeat:是否在不同的epochs中重复迭代 ,默认是False
train_iter, val_iter, test_iter = data.BucketIterator.splits(dataset = (train,dev,test),batch_size = batch_size,shuffle=True,sort=False,sort_within_batch=False,repeat=False)def getIter():return train_iter, val_iter, test_iter
3.4 完整代码
点击展开,完整代码如下
import osimport reimport jiebaimport torchimport randomimport numpy as npfrom torchtext.legacy import datafrom Config import *torch.manual_seed(SEED)torch.manual_seed(SEED)torch.cuda.manual_seed_all(SEED)np.random.seed(SEED)random.seed(SEED)torch.backends.cudnn.deterministic = Truedef x_tokenize(x):str = re.sub('[^\u4e00-\u9fa5]', "", x)return jieba.lcut(str)TEXT = data.Field(sequential=True,tokenize=x_tokenize,fix_length=max_length,use_vocab=True)LABEL = data.Field(sequential=False,use_vocab=False)train, dev, test = data.TabularDataset.splits(path=os.path.join(data_path,task_name),train=train_file,validation=valid_file,test=test_file,format='csv',skip_header=True,csv_reader_params={'delimiter':','},fields=[("text",TEXT),('label',LABEL)])TEXT.build_vocab(train)train_iter, val_iter, test_iter = data.BucketIterator.splits(datasets = (train,dev,test),batch_size = batch_size,shuffle=True,sort=False,sort_within_batch=False,repeat=False)def getTEXT():return TEXTdef getLabel():return LABELdef getIter():return train_iter, val_iter, test_iter
4 Model 创建模型
前BERT时代,文本分类的模型创建并不难,基本百度torch+对应模型的名字都可以找到代码,不做赘述。
模型也可以创建一个模型文件夹存放起来,在模型文件夹中在创建对应模型的.py文件。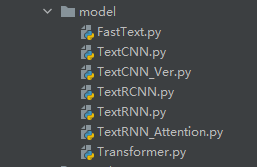
4.1 TextCNN
import torchfrom Config import SEED,class_numbertorch.manual_seed(SEED)torch.backends.cudnn.deterministic = Trueimport DataSetimport torch.nn as nnimport torch.nn.functional as Fclass TextCNN(nn.Module):def __init__(self):super(TextCNN, self).__init__()Vocab = len(DataSet.getTEXT().vocab) ## 已知词的数量Dim = 256 ##每个词向量长度Cla = class_number ##类别数Ci = 1 ##输入的channel数Knum = 256 ## 每种卷积核的数量Ks = [2,3,4] ## 卷积核list,形如[2,3,4]self.embed = nn.Embedding(Vocab, Dim) ## 词向量,这里直接随机# 指定嵌入矩阵的初始权重self.convs = nn.ModuleList([nn.Conv2d(Ci, Knum, (K, Dim)) for K in Ks]) ## 卷积层self.dropout = nn.Dropout(0.5)self.fc = nn.Linear(len(Ks) * Knum, Cla) ##全连接层def forward(self, x):# [batch len, text size]x = self.embed(x)# [batch len, text size, emb dim]x = x.unsqueeze(1)# [batch len, Ci, text size, emb dim]x = [F.relu(conv(x)).squeeze(3) for conv in self.convs]# len(Ks)*[batch size, Knum, text len]x = [F.max_pool1d(line, line.size(2)).squeeze(2) for line in x]# len(Ks)*[batch size, Knum]x = torch.cat(x, 1)# [batch size, Knum*len(Ks)]x = self.dropout(x)# [batch size, Knum*len(Ks)]logit = self.fc(x)# [batch size, Cla]return logit
4.2 TextRNN
import torchfrom Config import SEED,class_numbertorch.manual_seed(SEED)torch.backends.cudnn.deterministic = Trueimport DataSetimport torch.nn as nnclass TextRNN(nn.Module):def __init__(self):super(TextRNN, self).__init__()Vocab = len(DataSet.getTEXT().vocab) ## 已知词的数量Dim = 256 ##每个词向量长度dropout = 0.2hidden_size = 256 #隐藏层数量num_classes = class_number ##类别数num_layers = 2 ##双层LSTMself.embedding = nn.Embedding(Vocab, Dim) ## 词向量,这里直接随机self.lstm = nn.LSTM(Dim, hidden_size, num_layers,bidirectional=True, batch_first=True, dropout=dropout)self.fc = nn.Linear(hidden_size * 2, num_classes)def forward(self, x):# [batch len, text size]x = self.embedding(x)# [batch size, text size, embedding]output, (hidden, cell) = self.lstm(x)# output = [batch size, text size, num_directions * hidden_size]output = self.fc(output[:, -1, :]) # 句子最后时刻的 hidden state# output = [batch size, num_classes]return output
4.3 TextRCNN
import torchimport torch.nn as nnimport torch.nn.functional as Fimport DataSetfrom Config import SEED,class_number,max_lengthtorch.manual_seed(SEED)torch.backends.cudnn.deterministic = Trueclass TextRCNN(nn.Module):def __init__(self,vocab_size = len(DataSet.getTEXT().vocab), # 词典的大小(总共有多少个词语/字)n_class = class_number, # 分类的类型embed_dim=256, # embedding的维度rnn_hidden=256,dropout=0.2):super(TextRCNN, self).__init__()self.rnn_hidden = rnn_hiddenself.embed_dim = embed_dimself.embedding = nn.Embedding(num_embeddings=vocab_size,embedding_dim=embed_dim,)self.maxpool = nn.MaxPool1d(max_length)self.lstm = nn.LSTM(embed_dim, rnn_hidden, 2,bidirectional=True, batch_first=True, dropout=dropout)self.fc = nn.Linear(in_features=embed_dim+2*rnn_hidden,out_features=n_class)def forward(self, x):#[batch, text_len]x = self.embedding(x)# [batch, text_len, embed_dim]# output, h_n = self.gru(x)output, _ = self.lstm(x)x = torch.cat([x, output], dim=2)# [batch, text_len, 2*rnn_hidden+embed_dim]x = F.relu(x)x = x.permute(0, 2, 1)x = self.maxpool(x).squeeze()# x = F.max_pool2d(x, (x.shape[1], 1))# [batch, 1, 2*rnn_hidden+embed_dim]# x = x.reshape(-1,2 * self.rnn_hidden+self.embed_dim)# [batch, 2*rnn_hidden+embed_dim]x = self.fc(x) # [batch, n_class]# x = torch.sigmoid(x)return x
4.4 TextRNN_Attention
import torchfrom Config import SEED,class_numbertorch.manual_seed(SEED)torch.backends.cudnn.deterministic = Trueimport DataSetimport torch.nn as nnimport torch.nn.functional as Fclass TextRNN_Attention(nn.Module):def __init__(self):super(TextRNN_Attention, self).__init__()Vocab = len(DataSet.getTEXT().vocab) ## 已知词的数量Dim = 256 ##每个词向量长度dropout = 0.2hidden_size = 256 #隐藏层数量num_classes = class_number ##类别数num_layers = 2 ##双层LSTMself.embedding = nn.Embedding(Vocab, Dim) ## 词向量,这里直接随机self.lstm = nn.LSTM(Dim, hidden_size, num_layers,bidirectional=True, batch_first=True, dropout=dropout)self.tanh1 = nn.Tanh()self.w = nn.Parameter(torch.zeros(hidden_size * 2))self.tanh2 = nn.Tanh()self.fc = nn.Linear(hidden_size * 2, num_classes)def forward(self, x):# [batch len, text size]x = self.embedding(x)# [batch size, text size, embedding]output, (hidden, cell) = self.lstm(x)# output = [batch size, text size, num_directions * hidden_size]M = self.tanh1(output)# [batch size, text size, num_directions * hidden_size]alpha = F.softmax(torch.matmul(M, self.w), dim=1).unsqueeze(-1)# [batch size, text size, 1]out = output * alpha# [batch size, text size, num_directions * hidden_size]out = torch.sum(out, 1)# [batch size, num_directions * hidden_size]out = F.relu(out)# [batch size, num_directions * hidden_size]out = self.fc(out)# [batch size, num_classes]return out
4.5 Transformer
import torchimport torch.nn as nnimport torch.nn.functional as Fimport numpy as npimport copyimport DataSetfrom Config import SEED,class_number,max_lengthtorch.manual_seed(SEED)torch.backends.cudnn.deterministic = Trueclass Transformer(nn.Module):def __init__(self,vocab_size = len(DataSet.getTEXT().vocab), # 词典的大小seq_len = max_length,n_class = class_number, # 分类的类型device = torch.device('cuda' if torch.cuda.is_available() else 'cpu'),embed_dim=256, # embedding的维度dim_model=256,dropout=0.2,num_head=8,hidden=512,num_encoder=4,):super(Transformer, self).__init__()self.embedding = nn.Embedding(vocab_size, embed_dim)self.postion_embedding = Positional_Encoding(embed_dim, seq_len, dropout, device)self.encoder = Encoder(dim_model, num_head, hidden, dropout)self.encoders = nn.ModuleList([copy.deepcopy(self.encoder)for _ in range(num_encoder)])self.fc1 = nn.Linear(seq_len * dim_model, n_class)def forward(self, x):out = self.embedding(x)out = self.postion_embedding(out)for encoder in self.encoders:out = encoder(out)out = out.view(out.size(0), -1)out = self.fc1(out)return outclass Encoder(nn.Module):def __init__(self, dim_model, num_head, hidden, dropout):super(Encoder, self).__init__()self.attention = Multi_Head_Attention(dim_model, num_head, dropout)self.feed_forward = Position_wise_Feed_Forward(dim_model, hidden, dropout)def forward(self, x):out = self.attention(x)out = self.feed_forward(out)return outclass Positional_Encoding(nn.Module):def __init__(self, embed, pad_size, dropout, device):super(Positional_Encoding, self).__init__()self.device = deviceself.pe = torch.tensor([[pos / (10000.0 ** (i // 2 * 2.0 / embed)) for i in range(embed)] for pos in range(pad_size)])self.pe[:, 0::2] = np.sin(self.pe[:, 0::2])self.pe[:, 1::2] = np.cos(self.pe[:, 1::2])self.dropout = nn.Dropout(dropout)def forward(self, x):out = x + nn.Parameter(self.pe, requires_grad=False).to(self.device)out = self.dropout(out)return outclass Scaled_Dot_Product_Attention(nn.Module):'''Scaled Dot-Product Attention '''def __init__(self):super(Scaled_Dot_Product_Attention, self).__init__()def forward(self, Q, K, V, scale=None):'''Args:Q: [batch_size, len_Q, dim_Q]K: [batch_size, len_K, dim_K]V: [batch_size, len_V, dim_V]scale: 缩放因子 论文为根号dim_KReturn:self-attention后的张量,以及attention张量'''attention = torch.matmul(Q, K.permute(0, 2, 1))if scale:attention = attention * scale# if mask: # TODO change this# attention = attention.masked_fill_(mask == 0, -1e9)attention = F.softmax(attention, dim=-1)context = torch.matmul(attention, V)return contextclass Multi_Head_Attention(nn.Module):def __init__(self, dim_model, num_head, dropout=0.0):super(Multi_Head_Attention, self).__init__()self.num_head = num_headassert dim_model % num_head == 0self.dim_head = dim_model // self.num_headself.fc_Q = nn.Linear(dim_model, num_head * self.dim_head)self.fc_K = nn.Linear(dim_model, num_head * self.dim_head)self.fc_V = nn.Linear(dim_model, num_head * self.dim_head)self.attention = Scaled_Dot_Product_Attention()self.fc = nn.Linear(num_head * self.dim_head, dim_model)self.dropout = nn.Dropout(dropout)self.layer_norm = nn.LayerNorm(dim_model)def forward(self, x):batch_size = x.size(0)Q = self.fc_Q(x)K = self.fc_K(x)V = self.fc_V(x)Q = Q.view(batch_size * self.num_head, -1, self.dim_head)K = K.view(batch_size * self.num_head, -1, self.dim_head)V = V.view(batch_size * self.num_head, -1, self.dim_head)# if mask: # TODO# mask = mask.repeat(self.num_head, 1, 1) # TODO change thisscale = K.size(-1) ** -0.5 # 缩放因子context = self.attention(Q, K, V, scale)context = context.view(batch_size, -1, self.dim_head * self.num_head)out = self.fc(context)out = self.dropout(out)out = out + x # 残差连接out = self.layer_norm(out)return outclass Position_wise_Feed_Forward(nn.Module):def __init__(self, dim_model, hidden, dropout=0.0):super(Position_wise_Feed_Forward, self).__init__()self.fc1 = nn.Linear(dim_model, hidden)self.fc2 = nn.Linear(hidden, dim_model)self.dropout = nn.Dropout(dropout)self.layer_norm = nn.LayerNorm(dim_model)def forward(self, x):out = self.fc1(x)out = F.relu(out)out = self.fc2(out)out = self.dropout(out)out = out + x # 残差连接out = self.layer_norm(out)return out
4.6 FastText
import torchfrom Config import SEED,class_numbertorch.manual_seed(SEED)torch.backends.cudnn.deterministic = Trueimport DataSetimport torch.nn as nnclass FastText(nn.Module):def __init__(self):super(FastText, self).__init__()Vocab = len(DataSet.getTEXT().vocab) ## 已知词的数量Dim = 256 ##每个词向量长度Cla = class_number ##类别数hidden_size = 128self.embed = nn.Embedding(Vocab, Dim) ## 词向量,这里直接随机self.fc = nn.Sequential( #序列函数nn.Linear(Dim, hidden_size), #这里的意思是先经过一个线性转换层nn.BatchNorm1d(hidden_size), #再进入一个BatchNorm1dnn.ReLU(inplace=True), #再经过Relu激活函数nn.Linear(hidden_size ,Cla)#最后再经过一个线性变换)def forward(self, x):# [batch len, text size]x = self.embed(x)x = torch.mean(x,dim=1)# [batch size, Dim]logit = self.fc(x)# [batch size, Cla]return logit
4.7 DPCNN
import torchfrom Config import SEED,class_numbertorch.manual_seed(SEED)torch.backends.cudnn.deterministic = Trueimport DataSetimport torch.nn as nnimport torch.nn.functional as Fclass DPCNN(nn.Module):def __init__(self):super(DPCNN, self).__init__()Vocab = len(DataSet.getTEXT().vocab) ## 已知词的数量embed_dim = 256 ##每个词向量长度Cla = class_number ##类别数ci = 1 # input chanel sizekernel_num = 250 # output chanel size# embed_dim = trial.suggest_int("n_embedding", 200, 300, 50)self.embed = nn.Embedding(Vocab, embed_dim, padding_idx=1)self.conv_region = nn.Conv2d(ci, kernel_num, (3, embed_dim), stride=1)self.conv = nn.Conv2d(kernel_num, kernel_num, (3, 1), stride=1)self.max_pool = nn.MaxPool2d(kernel_size=(3, 1), stride=2)self.max_pool_2 = nn.MaxPool2d(kernel_size=(2, 1))self.padding = nn.ZeroPad2d((0, 0, 1, 1)) # top bottomself.relu = nn.ReLU()self.fc = nn.Linear(kernel_num, Cla)def forward(self, x):x = self.embed(x) # x: (batch, seq_len, embed_dim)x = x.unsqueeze(1) # x: (batch, 1, seq_len, embed_dim)m = self.conv_region(x) # [batch_size, 250, seq_len-3+1, 1]x = self.padding(m) # [batch_size, 250, seq_len, 1]x = self.relu(x) # [batch_size, 250, seq_len, 1]x = self.conv(x) # [batch_size, 250, seq_len-3+1, 1]x = self.padding(x) # [batch_size, 250, seq_len, 1]x = self.relu(x) # [batch_size, 250, seq_len, 1]x = self.conv(x) # [batch_size, 250, seq_len-3+1, 1]x = x + mwhile x.size()[2] > 2:x = self._block(x)if x.size()[2] == 2:x = self.max_pool_2(x) # [batch_size, 250, 1, 1]x = x.squeeze() # [batch_size, 250]logit = F.log_softmax(self.fc(x), dim=1)return logitdef _block(self, x): # for example: [batch_size, 250, 4, 1]px = self.max_pool(x) # [batch_size, 250, 1, 1]x = self.padding(px) # [batch_size, 250, 3, 1]x = F.relu(x)x = self.conv(x) # [batch_size, 250, 1, 1]x = self.padding(x)x = F.relu(x)x = self.conv(x)# Short Cutx = x + pxreturn x
4.8 Capsule
import torch# 在Config里加一个embedding_dim变量,用于控制词向量维度from Config import SEED,class_number,load_embedding,embedding_dimtorch.manual_seed(SEED)torch.backends.cudnn.deterministic = Trueimport DataSetimport torch.nn as nnimport torch.nn.functional as Fclass GRULayer(nn.Module):def __init__(self, hidden_size,embed_dim):super(GRULayer, self).__init__()self.gru = nn.GRU(input_size=embed_dim, hidden_size=hidden_size, bidirectional=True)def init_weights(self):ih = (param.data for name, param in self.named_parameters() if 'weight_ih' in name)hh = (param.data for name, param in self.named_parameters() if 'weight_hh' in name)b = (param.data for name, param in self.named_parameters() if 'bias' in name)for k in ih:nn.init.xavier_uniform_(k)for k in hh:nn.init.orthogonal_(k)for k in b:nn.init.constant_(k, 0)def forward(self, x):return self.gru(x)class CapsuleLayer(nn.Module):def __init__(self, input_dim_capsule, num_capsule, dim_capsule, routings, activation='default'):super(CapsuleLayer, self).__init__()self.num_capsule = num_capsuleself.dim_capsule = dim_capsuleself.routings = routingsself.t_epsilon = 1e-7 # 计算squash需要的参数if activation == 'default':self.activation = self.squashelse:self.activation = nn.ReLU(inplace=True)self.W = nn.Parameter(nn.init.xavier_normal_(torch.empty(1, input_dim_capsule, num_capsule * dim_capsule)))def forward(self, x):u_hat_vecs = torch.matmul(x, self.W)batch_size = x.size(0)input_num_capsule = x.size(1)u_hat_vecs = u_hat_vecs.view((batch_size, input_num_capsule, self.num_capsule, self.dim_capsule))u_hat_vecs = u_hat_vecs.permute(0, 2, 1, 3)b = torch.zeros_like(u_hat_vecs[:, :, :, 0])outputs = 0for i in range(self.routings):b = b.permute(0, 2, 1)c = F.softmax(b, dim=2)c = c.permute(0, 2, 1)b = b.permute(0, 2, 1)outputs = self.activation(torch.einsum('bij,bijk->bik', (c, u_hat_vecs)))if i < self.routings - 1:b = torch.einsum('bik,bijk->bij', (outputs, u_hat_vecs))return outputsdef squash(self, x, axis=-1):s_squared_norm = (x ** 2).sum(axis, keepdim=True)scale = torch.sqrt(s_squared_norm + self.t_epsilon)return x / scaleclass Capsule(nn.Module):def __init__(self,Vocab = len(DataSet.getTEXT().vocab),embed_dim = embedding_dim,num_classes = class_number):super(Capsule, self).__init__()# 一些参数self.hidden_size = 128self.num_capsule = 10self.dim_capsule = 16self.routings = 5self.dropout_p = 0.25# 1. 词嵌入self.embed = nn.Embedding(Vocab,embed_dim)if load_embedding == "w2v":weight_matrix = DataSet.getTEXT().vocab.vectorsself.embed.weight.data.copy_(weight_matrix)elif load_embedding == "glove":weight_matrix = DataSet.getTEXT().vocab.vectorsself.embed.weight.data.copy_(weight_matrix)# self.embedding = nn.Embedding(args.n_vocab, args.embed, padding_idx=args.n_vocab - 1)# 2. 一层gruself.gru = GRULayer(hidden_size=self.hidden_size,embed_dim=embed_dim)self.gru.init_weights() # 对gru的参数进行显性初始化# 3. capsuleself.capsule = CapsuleLayer(input_dim_capsule=self.hidden_size * 2, num_capsule=self.num_capsule,dim_capsule=self.dim_capsule, routings=self.routings)# 4. 分类层self.classify = nn.Sequential(nn.Dropout(p=self.dropout_p, inplace=True),nn.Linear(self.num_capsule * self.dim_capsule, num_classes),)def forward(self, input_ids):batch_size = input_ids.size(0)embed = self.embed(input_ids)# print(embed.size()) # torch.Size([2, 128, 300])output, _ = self.gru(embed) # output.size() torch.Size([2, 128, 256])cap_out = self.capsule(output)# print(cap_out.size()) # torch.Size([2, 10, 16])cap_out = cap_out.view(batch_size, -1)return self.classify(cap_out)
5 Train_fine_tune 训练和精调
5.1 模型字典和载入设备
- 为了提升复用性,希望在Config中设置
model_name的字符串即可更换不同模型进行训练,在一开始根据模型名称创建一个字典,在后续模型创建时调用该字典即可实现希望的效果。 - device设置使用GPU ```python import os import pandas as pd import torch import torch.nn.functional as F from tqdm import tqdm from sklearn.metrics import accuracy_score,precision_score,recall_score,f1_score,cohen_kappa_score from Config import * import DataSet from model.TextCNN import TextCNN from model.TextRCNN import TextRCNN from model.TextRNN import TextRNN from model.TextRNN_Attention import TextRNN_Attention from model.Transformer import Transformer from model.FastText import FastText
model_select = {“TextCNN”:TextCNN(), “TextRNN”:TextRNN(), “TextRCNN”:TextRCNN(), “TextRNN_Attention”:TextRNN_Attention(), “Transformer”:Transformer(), “FastText”:FastText(), } device = torch.device(‘cuda’ if torch.cuda.is_available() else ‘cpu’)
<a name="CL8Q7"></a>## 5.1 评价函数使用`sklearn.metrics`可以方便地得到各种评价指标,封装为一个函数,并存入字典中,后续结果只需要操对结果字典进行操作。<br />其中`round`是控制小数点位数```pythondef mutil_metrics(y_true,y_predict,type_avrage='macro'):result = {}result["acc"] = accuracy_score(y_true=y_true,y_pred=y_predict)result["precision"] = precision_score(y_true=y_true,y_pred=y_predict,average=type_avrage)result["recall"] = recall_score(y_true=y_true, y_pred=y_predict, average=type_avrage)result["f1"] = f1_score(y_true=y_true, y_pred=y_predict, average=type_avrage)# result["kappa"] = cohen_kappa_score(y1=y_true, y2=y_predict)for k,v in result.items():result[k] = round(v,5)return result
5.2 训练和验证
1)训练和验证
训练验证学习过torch的应该清楚流程,两个for循环,一个遍历epoch,一个遍历以batch为单位的数据迭代器,一个batch一个batch的操作,验证可以放在几个batch之后,也可以一个epoch验证一次
def train_model(train_iter, dev_iter, model, name, device):model = model.to(device)optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)scheduler = torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones=[15, 25], gamma=0.6)model.train()best_score = 0early_stopping = 0print('training...')# 每一个epochfor epoch in range(1, epochs + 1):model.train()total_loss = 0.0train_score = 0total_train_num = len(train_iter)progress_bar = tqdm(enumerate(train_iter), total=len(train_iter))# 每一步等于一个Batchfor i,batch in progress_bar:feature = batch.texttarget = batch.labelwith torch.no_grad():feature = torch.t(feature)feature, target = feature.to(device), target.to(device)optimizer.zero_grad()# 输入模型,得到输出概率分布logit = model(feature)# 使用损失函得到损失loss = F.cross_entropy(logit, target)# 反向传播梯度loss.backward()optimizer.step()scheduler.step()total_loss += loss.item()# 计算评估分数result = mutil_metrics(target.cpu().numpy(),torch.argmax(logit, dim=1).cpu().numpy(),type_avrage='macro')train_score += result[best_metric]# 进入验证阶段print('>>> Epoch_{}, Train loss is {}, {}:{} \n'.format(epoch,loss.item()/total_train_num, best_metric,train_score/total_train_num))model.eval()total_loss = 0.0vaild_score= 0total_valid_num = len(dev_iter)for i, batch in enumerate(dev_iter):feature = batch.text # (W,N) (N)target = batch.labelwith torch.no_grad():feature = torch.t(feature)feature, target = feature.to(device), target.to(device)out = model(feature)loss = F.cross_entropy(out, target)total_loss += loss.item()valid_result = mutil_metrics(target.cpu().numpy(),torch.argmax(out, dim=1).cpu().numpy(),type_avrage='binary')vaild_score += valid_result[best_metric]print('>>> Epoch_{}, Valid loss:{}, {}:{} \n'.format(epoch, total_loss/total_valid_num, best_metric,vaild_score/total_valid_num))if(vaild_score/total_valid_num > best_score):early_stopping = 0print('save model...')best_score = vaild_score/total_valid_numsaveModel(model, name=name)else:early_stopping += 1if early_stopping == early_stopping_nums:break
3)保存模型
保存模型函数,以模型名称为文件名保存最佳模型
def saveModel(model,name):torch.save(model, 'done_model/'+name+'_model.pkl')
5.3 测试和保存实验记录
1)测试
def test_model(test_iter, name, device):model = torch.load('done_model/'+name+'_model.pkl')model = model.to(device)model.eval()y_true = []y_pred = []for batch in test_iter:feature = batch.texttarget = batch.labelwith torch.no_grad():feature = torch.t(feature)feature, target = feature.to(device), target.to(device)out = model(feature)y_true.extend(target.cpu().numpy())y_pred.extend(torch.argmax(out, dim=1).cpu().numpy())result = mutil_metrics(y_true, y_pred, type_avrage='macro')print('>>> Test {} Result:{} \n'.format(name,result))from sklearn.metrics import classification_reportprint(classification_report(y_true, y_pred, target_names=label_list, digits=3))save_experimental_details(result)
2)保存实验记录
训练完成模型,肯定要保存实验记录,除了最终的结果还有实验的一些重要参数,其次也应该增添任务信息,方便对不同任务进行分析。
def save_experimental_details(test_result):save_path = os.path.join(data_path, task_name, result_file)var = [task_name, model_name, SEED, batch_size, max_length, learning_rate]names = ['task_dataset', 'model_name','Seed', 'Batch_size', 'Max_lenth', 'lr']vars_dict = {k: v for k, v in zip(names, var)}results = dict(test_result, **vars_dict)keys = list(results.keys())values = list(results.values())if not os.path.exists(save_path):ori = []ori.append(values)new_df = pd.DataFrame(ori, columns=keys)new_df.to_csv(os.path.join(data_path,task_name,result_file), index=False,sep='\t')else:df = pd.read_csv(save_path,sep='\t')new = pd.DataFrame(results, index=[1])df = df.append(new, ignore_index=True)df.to_csv(save_path, index=False,sep='\t')data_diagram = pd.read_csv(save_path,sep='\t')print('test_results \n', data_diagram)
6 Classify 分类预测
预测部分,摆烂了,写不动了,随便看看吧
其中,model_predict返回单条数据的分类结果;predict_csv则是预测一整个文件,拥有批处理或提交比赛数据。
import jiebaimport torchimport DataSetimport pandas as pdimport osimport refrom Config import max_length, label_list,model_name,data_path,task_name,predict_filedevice = torch.device('cuda' if torch.cuda.is_available() else 'cpu')def x_tokenize(x):str = re.sub('[^\u4e00-\u9fa5]', "", x)return jieba.lcut(str)def getModel(name):model = torch.load('done_model/'+name+'_model.pkl')return modeldef model_predict(model, sentence):model.eval()tokenized = x_tokenize(sentence)indexed = [DataSet.getTEXT().vocab.stoi[t] for t in tokenized]if(len(indexed) > max_length):indexed = indexed[:max_length]else:for i in range(max_length-len(indexed)):indexed.append(DataSet.getTEXT().vocab.stoi['<pad>'])tensor = torch.LongTensor(indexed).to(device)tensor = tensor.unsqueeze(1)tensor = torch.t(tensor)out = torch.softmax(model(tensor),dim=1)result = label_list[torch.argmax(out, dim=1)]response = {k:v for k,v in zip(label_list,out.cpu().detach().numpy()[0])}return response,resultdef predict_csv(model):model.eval()outs = []df = pd.read_csv(os.path.join(data_path,task_name,predict_file),sep='\t')for sentence in df["query"]:tokenized = x_tokenize(sentence)indexed = [DataSet.getTEXT().vocab.stoi[t] for t in tokenized]if(len(indexed) > max_length):indexed = indexed[:max_length]else:for i in range(max_length-len(indexed)):indexed.append(DataSet.getTEXT().vocab.stoi['<pad>'])tensor = torch.LongTensor(indexed).to(device)tensor = tensor.unsqueeze(1)tensor = torch.t(tensor)out = label_list[torch.argmax(model(tensor),dim=1)]outs.append(out)df["label"] = outssumbit = df[["query","label"]]sumbit.to_csv(os.path.join(data_path,task_name,"predict.txt"),index=False,sep='\t')def load_model():model = getModel(model_name)model = model.to(device)return modelif __name__=="__main__":model = load_model()sent1 = '你要那么确定百分百,家里房子卖了,上'response, result = model_predict(model, sent1)print('概率分布:{}\n预测标签:{}'.format(response,result))predict_csv(model)
7 app.py 应用部署
7.1 改写app.py文件
把Classify的model_predict和load_modelimport进来,无需对之前的predict函数整体进行改动,需要修改两个地方:
- 在app下方添加一行
model = load_model()加载已训练的model - 在modelpredict()中将model添加进去 ```python from Classify import modelpredict,load_model from flask import Flask, render_template, request app = Flask(__name,template_folder=’templates’,static_folder=”templates”,static_url_path=’’)
model = load_model()
前端表单数据获取和响应
@app.route(‘/predict’,methods=[‘GET’,’POST’]) def predict(): isHead = False if request.method == ‘POST’: sent1 = request.form.get(‘sentence1’) sent2 = request.form.get(‘sentence2’) text = sent1 + sent2
# 通过预测函数得到响应,result是预测的标签,response是软标签logitsresponse,result = model_predict(model,sentence)return render_template('index.html',isHead=isHead,sent1=sent1,sent2=sent2,response=response,result=result)
@app.route(‘/‘,methods=[‘GET’,’POST’]) def index(): isHead = True return render_template(‘index.html’,isHead=isHead)
if name == ‘main‘: app.run() ```
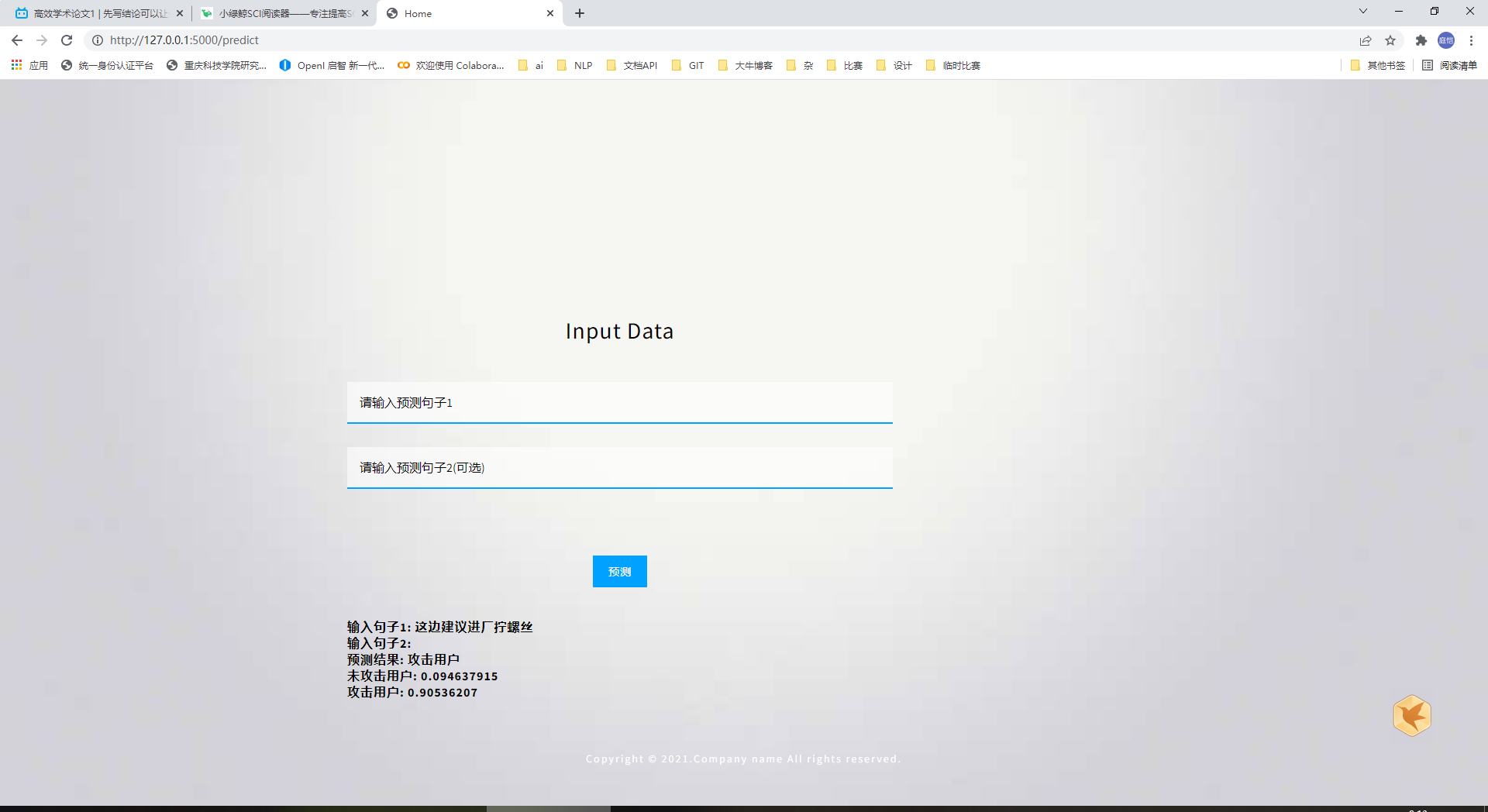
7.2 文本分类部署效果

若有收获,就点个赞吧
0 人点赞
