时间序列分析就是发现时间序列的变动规律并使用该规律来预测的统计技术。时间序列分析基于以下三个假设:
- 假设事物发展规律趋势会延续到未来。
- 预测所依据的数据没有不规则性。
- 不考虑事物发展之间的因果关系。
时间序列分析主要包括两方面内容:第一是序列分解;第二是序列预测。
代码及数据地址:
https://github.com/SeafyLiang/machine_learning_study/tree/master/time_series
一、时间序列分解
一个时间序列包含三种影响因素:
- 长期趋势:在一个相当长的时间内表现为一种近似直线的持续向上、向下或平稳的趋势。
- 季节变动:受季节变化影响所形成的一种长度和幅度固定的短期周期波动,“季节”指的是周期,可以是周、月、年等。
- 不规则变动:受偶然因素的影响所形成的不规则波动,如股票市场受利好或者利空信息的影响,使得股票价格产生的波动。
时间序列按照季节性来分类,分为季节性时间序列和非季节性时间序列。
1.1 非季节性时间序列分解
MA(Moving Average)
移动平均是一种简单平滑技术,它通过在时间序列上逐项推移取一定项数的均值,来表现指标的长期变化和发展趋势。
SMA(Simple Moving Average)
简单移动平均将时间序列上前n个数值做简单的算术平均。
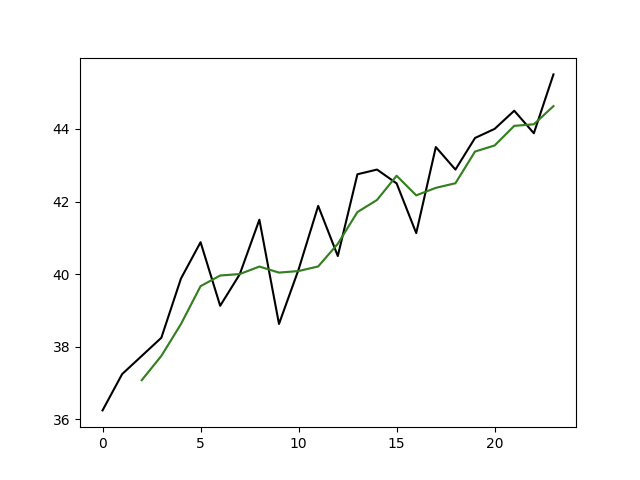
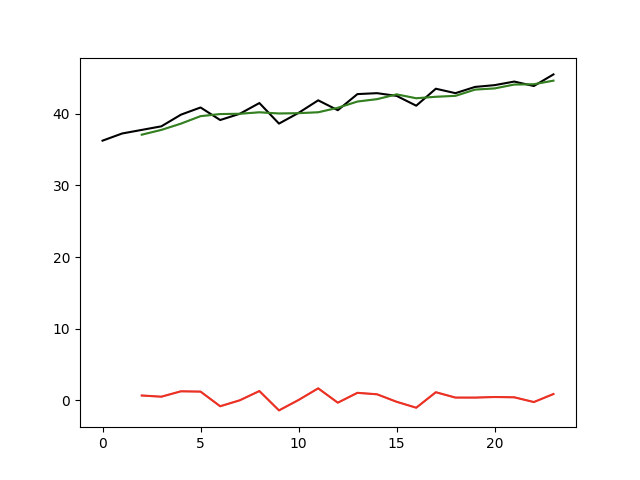
import pandas as pdimport numpy as npimport matplotlib.pyplot as pltdata = pd.read_csv('data/非季节性时间序列.csv', encoding='utf8', engine='python')original_data = data['公司A']def sma_demo():# 将非季节性的时间序列,分解为趋势部分和不规则部分# SMA 简单移动平均sma_data = original_data.rolling(3).mean()plt.plot(data.index, original_data, 'k-',data.index, sma_data, 'g-')plt.show()# 平滑后的曲线,波动性基本被消除# 加入随机误差random_error = original_data - sma_dataplt.plot(data.index, original_data, 'k-',data.index, sma_data, 'g-',data.index, random_error, 'r-')plt.show()# 随机误差在0附件波动,均值趋向于0if __name__ == '__main__':sma_demo()
WMA(Weighted Moving Average)
加权移动平均在基于简单移动平均的基础上,对时间序列上前n期的每一期数值赋予对应的权重。
它的基本思想是,提升近期的数据并减弱远期数据对当前预测值的影响,使平滑值更贴近最近的变化趋势。
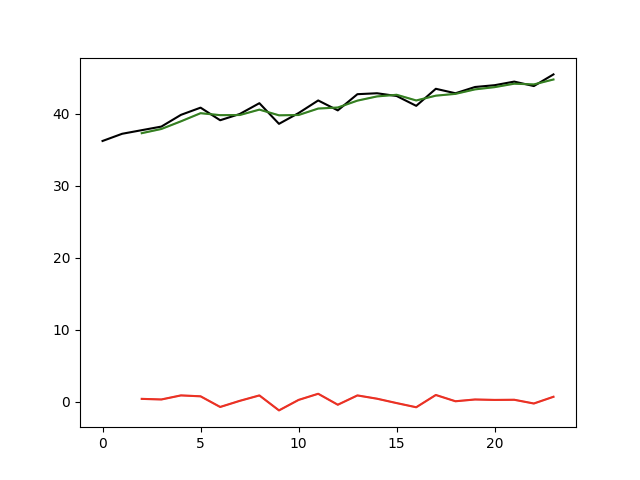
import pandas as pdimport numpy as npimport matplotlib.pyplot as pltdata = pd.read_csv('data/非季节性时间序列.csv', encoding='utf8', engine='python')original_data = data['公司A']def wma_demo():# WMA 加权移动平均# 定义窗口大小wl = 3# 定义每个窗口值的权重ww = [1 / 6, 2 / 6, 3 / 6]def wma(window):return np.sum(window * ww)sma_data = original_data.rolling(wl).aggregate(wma)random_error = original_data - sma_dataplt.plot(data.index, original_data, 'k-',data.index, sma_data, 'g-',data.index, random_error, 'r-')plt.show()if __name__ == '__main__':wma_demo()
1.2 季节性时间序列
季节性时间序列,是指在一个时间序列中,若经过n个时间间隔后,呈现出相似的波动,则称该序列具有以n为周期的季节性特性。
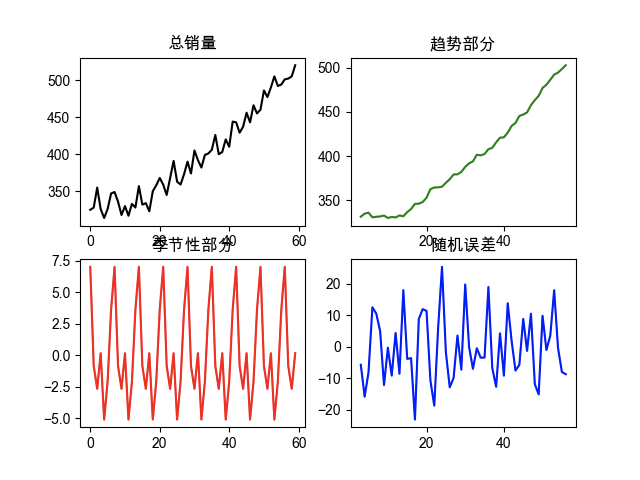
import pandas as pdimport statsmodels.apiimport matplotlib.pyplot as pltplt.rcParams['font.sans-serif'] = ['Arial Unicode MS']data = pd.read_csv('data/季节性时间序列.csv', encoding='utf8', engine='python')total_sales = data['总销量'].values# 执行季节性时间序列分解'''statsmodels.api.tsa.seasonal_decompose(x, freq=None)x:要分解的季节性时间序列freq:时间序列的周期,需要自己根据业务来判断数据的周期'''tsr = statsmodels.api.tsa.seasonal_decompose(total_sales, period=7)# 获取趋势部分trend = tsr.trend# 获取季节性部分seasonal = tsr.seasonal# 获取随机误差部分random_error = tsr.resid# 生成2*2的子图fig, ((ax1, ax2), (ax3, ax4)) = plt.subplots(2, 2)ax1.set_title('总销量')ax1.plot(data.index, total_sales, 'k-')ax2.set_title('趋势部分')ax2.plot(data.index, trend, 'g-')ax3.set_title('季节性部分')ax3.plot(data.index, seasonal, 'r-')ax4.set_title('随机误差')ax4.plot(data.index, random_error, 'b-')plt.show()
二、序列预测
时间序列预测,是根据时间序列反映出来的发展过程、方向和趋势,进行类推或延伸,借以预测下一段时间或以后若干周期内可能达到的水平。
时间序列预测使用时间序列的均值、方差和协方差这三个统计量来刻画时间序列的本质特征。若这些统计量的值在过去和未来仍保持不变,则为平稳的时间序列。
2.1 不平稳时间序列转换成平稳的时间序列
如果时间序列不平稳,则需要通过差分等技术手段,把它转换成平稳的时间序列,然后再进行预测。
差分(Integrated)
在pandas模块中,使用diff函数,即可对数据进行差分。
单位根检验法
可以使用单位根检验法来检验一个时间序列的平稳性。其中的p-value代表有多大的概率不是一个平稳的时间序列。
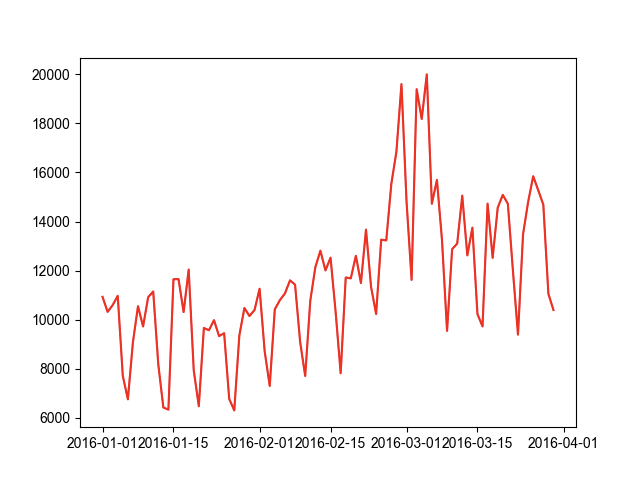
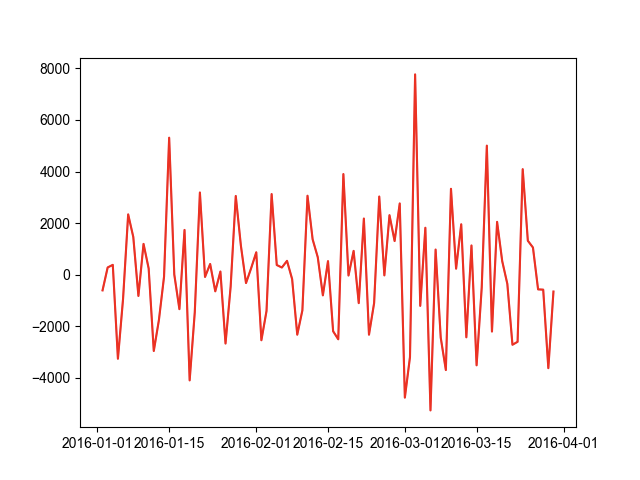
import pandas as pdimport matplotlib.pyplot as plt# 单位根检验法import statsmodels.tsa.stattools as tsplt.rcParams['font.sans-serif'] = ['Arial Unicode MS']'''一个平稳的时间序列指的是,未来的时间序列,它的均值、方差和协方差必定与现在的时间序列相等。若时间序列不平稳,则需要通过差分等技术手段,把它转换成平稳的时间序列,然后再进行预测。'''data = pd.read_csv('data/时间序列预测.csv', encoding='utf8', engine='python')# 设置索引为时间格式data.index = pd.to_datetime(data.date, format='%Y%m%d')# 删除date列,已经保存到索引中了del data['date']plt.figure()plt.plot(data, 'r')plt.show()# 使用单位根检验法检验是否是平稳的时间序列# 封装一个方法,方便解读adfuller函数的结果def tagADF(t):result = pd.DataFrame(index=["Test Statistic Value","p-value", "Lags Used","Number of Observations Used","Critical Value(1%)","Critical Value(5%)","Critical Value(10%)"], columns=['value'])result['value']['Test Statistic Value'] = t[0]result['value']['p-value'] = t[1]result['value']['Lags Used'] = t[2]result['value']['Number of Observations Used'] = t[3]result['value']['Critical Value(1%)'] = t[4]['1%']result['value']['Critical Value(5%)'] = t[4]['5%']result['value']['Critical Value(10%)'] = t[4]['10%']return result# 使用ADF单位根检验法,检验时间序列的稳定性adf_data = ts.adfuller(data.value)# 解读ADF单位根检验结果adfResult = tagADF(adf_data)print(adfResult)# value# Test Statistic Value -1.16364# p-value 0.689038# Lags Used 12# Number of Observations Used 77# Critical Value(1%) -3.518281# Critical Value(5%) -2.899878# Critical Value(10%) -2.587223# 68%的概率不是一个平稳的时间序列,故通过差分转换成平稳的时间序列# 对数据进行差分,删除第一个位置的空值diff = data.value.diff(1).dropna()plt.figure()plt.plot(diff, 'r')plt.show()# 使用ADF单位根检验法,检验时间序列的稳定性adf_diff = ts.adfuller(diff)# 解读ADF单位根检验结果adfResult = tagADF(adf_diff)print(adfResult)# value# Test Statistic Value -4.993859# p-value 0.000023# Lags Used 12# Number of Observations Used 76# Critical Value(1%) -3.519481# Critical Value(5%) -2.900395# Critical Value(10%) -2.587498# 0.000023<0.05,认为差分后的时间序列是平稳的时间序列
2.2 自回归模型-AR
自回归模型本质是一个线性回归模型,“自”描述的是当前值与历史值之间的关系。通过一个超参数p,把时间序列格式的样本转换为线性回归模型的样本。
2.3 移动平均模型-MA
移动平均模型描述的是自回归模型部分的累计误差。
移动平均模型的意义在于,找到较少参数的移动平均模型,来替代较多参数的自回归模型。
2.4 自回归移动平均模型-ARMA
ARMA模型就是AR模型和MA模型的组合,将因变量仅对它的滞后值以及随机误差项的现值和滞后值进行回归所建立的模型。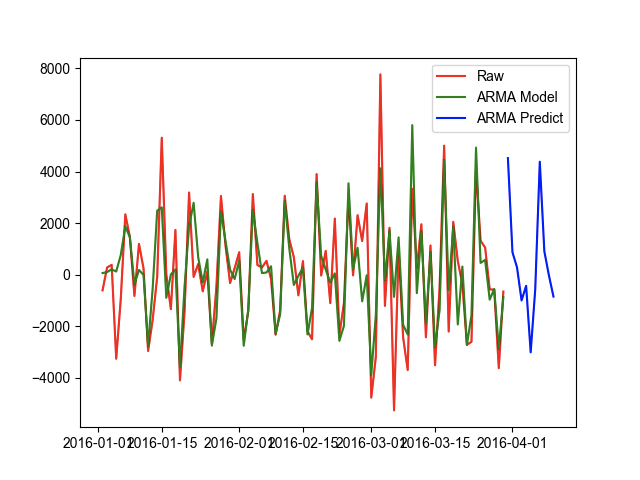
2.5 时序预测代码-AR, MA, ARMA
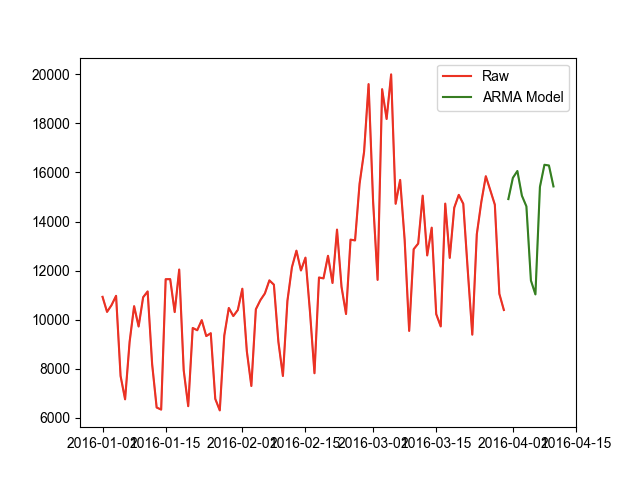
import statsmodels.api as smimport pandas as pdimport matplotlib.pyplot as pltimport warningswarnings.filterwarnings("ignore")plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']data = pd.read_csv('data/时间序列预测.csv', encoding='utf8', engine='python')# 设置索引为时间格式data.index = pd.to_datetime(data.date, format='%Y%m%d')# 删除date列,已经保存到索引中了del data['date']diff = data.value.diff(1).dropna()plt.figure()plt.plot(diff, 'r')plt.show()def ar_demo():'''自回归:return:'''# 使用 AR 建模arModel = sm.tsa.AR(diff)# 使用 AR 模型的 select_order 方法# 自动根据 AIC 指标,选择最优的 p 值p = arModel.select_order(maxlag=30,ic='aic')print(p)# 使用最优的 p 值进行建模arModel = arModel.fit(maxlag=p)# 对时间序列模型进行评估delta = arModel.fittedvalues - diffscore = 1 - delta.var() / diff.var()print(score)def sma_demo():'''简单移动平均:return:'''sma_data = diff.rolling(3).mean()plt.plot(diff.index, diff, 'k-',diff.index, sma_data, 'g-')plt.show()def arma_demo():# ARMA模型,使用AIC指标# AR模型从1-15中选择最优的p# MA模型从1-15中选择最优的q# 执行时间非常长,作者执行了10个小时左右# ic = sm.tsa.arma_order_select_ic(# diff,# max_ar=15,# max_ma=15,# ic='aic'# )# 选择最优参数order = (6, 6)armaModel = sm.tsa.ARMA(diff, order).fit()# 评估模型得分delta = armaModel.fittedvalues - diffscore = 1 - delta.var() / diff.var()print(score)# 预测接下来10天的值p = armaModel.predict(start='2016-03-31',end='2016-04-10')# 封装一个对差分的数据进行还原的函数def revert(diffValues, *lastValue):for i in range(len(lastValue)):result = []lv = lastValue[i]for dv in diffValues:lv = dv + lvresult.append(lv)diffValues = resultreturn diffValues# 对差分的数据进行还原r = revert(p, 10395)plt.figure()plt.plot(diff, 'r',label='Raw')plt.plot(armaModel.fittedvalues, 'g',label='ARMA Model')plt.plot(p, 'b', label='ARMA Predict')plt.legend()plt.show()r = pd.DataFrame({'value': r}, index=p.index)plt.figure()plt.plot(data.value, c='r',label='Raw')plt.plot(r, c='g',label='ARMA Model')plt.legend()plt.show()if __name__ == '__main__':ar_demo()sma_demo()arma_demo()

若有收获,就点个赞吧
0 人点赞
