参考资料:
常用聚类度量指标
sklearn聚类性能度量:main
轮廓系数及可视化中心点
聚类算法内部度量:
1. 轮廓系数(Silhouette Coefficient)
函数:
def silhouette_score(X, labels, metric=‘euclidean’, sample_size=None,
random_state=None, **kwds):
函数值说明:
所有样本的s i 的均值称为聚类结果的轮廓系数,定义为S,是该聚类是否合理、有效的度量。聚类结果的轮廓系数的取值在【-1,1】之间,值越大,说明同类样本相距约近,不同样本相距越远,则聚类效果越好。
2. CH分数(Calinski Harabasz Score )
函数:
def calinski_harabasz_score(X, labels):
函数值说明:
类别内部数据的协方差越小越好,类别之间的协方差越大越好,这样的Calinski-Harabasz分数会高。 总结起来一句话:CH index的数值越大越好。
3. 戴维森堡丁指数(DBI)——davies_bouldin_score
函数:
def davies_bouldin_score(X, labels):
函数值说明:
注意:DBI的值最小是0,值越小,代表聚类效果越好。
import pandas as pdfrom numpy import uniquefrom numpy import wherefrom matplotlib import pyplotfrom sklearn import metricsfrom sklearn.cluster import DBSCANimport matplotlib.pyplot as pltdata = pd.read_excel('cluster_data.xlsx')eps_list = []si_list = []ch_list = []dbi_list = []"""聚类-内部度量Calinski-Harabaz Index:在scikit-learn中, Calinski-Harabasz Index对应的方法是metrics.calinski_harabaz_score.CH指标通过计算类中各点与类中心的距离平方和来度量类内的紧密度,通过计算各类中心点与数据集中心点距离平方和来度量数据集的分离度,CH指标由分离度与紧密度的比值得到。从而,CH越大代表着类自身越紧密,类与类之间越分散,即更优的聚类结果。sklearn.metrics.silhouette_score:轮廓系数silhouette_sample对于一个样本点(b - a)/max(a, b)a平均类内距离,b样本点到与其最近的非此类的距离。silihouette_score返回的是所有样本的该值,取值范围为[-1,1]。这些度量均是越大越好"""# 初始参数聚类model = DBSCAN(min_samples=2)# 模型拟合与聚类预测X = data[['x', 'y']].valuesyhat = model.fit_predict(X)# 检索唯一群集clusters = unique(yhat)# 为每个群集的样本创建散点图for cluster in clusters:# 获取此群集的示例的行索引row_ix = where(yhat == cluster)# 创建这些样本的散布pyplot.scatter(X[row_ix, 0], X[row_ix, 1], label=cluster)# 绘制散点图pyplot.xlabel('x')pyplot.ylabel('y')plt.legend()pyplot.show()eps_cal = 1while eps_cal < 30:model = DBSCAN(eps=eps_cal, min_samples=2)label_list = model.fit_predict(data)# 轮廓系数cluster_score_si = metrics.silhouette_score(data, label_list)cluster_score_ch = metrics.calinski_harabasz_score(data, label_list)# DBI的值最小是0,值越小,代表聚类效果越好。cluster_score_DBI = metrics.davies_bouldin_score(data, label_list)eps_list.append(eps_cal)si_list.append(cluster_score_si)ch_list.append(cluster_score_ch)dbi_list.append(cluster_score_DBI)eps_cal += 1plt.figure()plt.plot(eps_list, si_list)plt.xlabel("dbscan-eps")plt.ylabel("silhouette_score")plt.title("dbscan-eps-si")plt.show()plt.figure()plt.plot(eps_list, ch_list)plt.xlabel("dbscan-eps")plt.ylabel("calinski_harabasz_score")plt.title("dbscan-eps-ch")plt.show()plt.figure()plt.plot(eps_list, dbi_list)plt.xlabel("dbscan-eps")plt.ylabel("davies_bouldin_score")plt.title("dbscan-eps-dbi")plt.show()# eps经过参数调优,选择22为合适值model = DBSCAN(eps=22, min_samples=2)# 模型拟合与聚类预测X = data[['x', 'y']].valuesyhat = model.fit_predict(X)# 检索唯一群集clusters = unique(yhat)# 为每个群集的样本创建散点图for cluster in clusters:# 获取此群集的示例的行索引row_ix = where(yhat == cluster)# 创建这些样本的散布pyplot.scatter(X[row_ix, 0], X[row_ix, 1], label=cluster)# 绘制散点图pyplot.xlabel('x')pyplot.ylabel('y')plt.legend()pyplot.show()
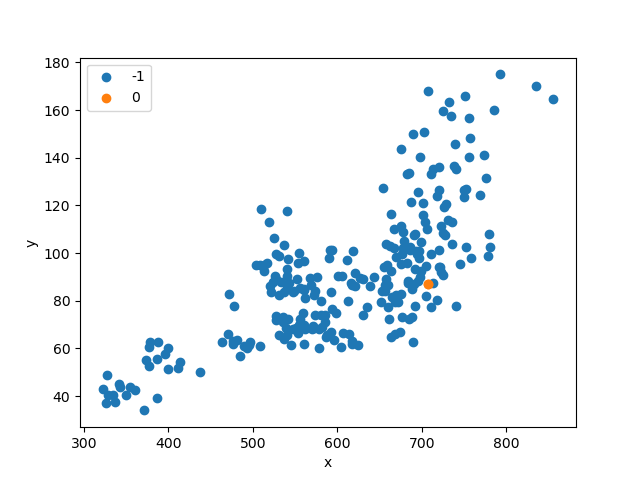
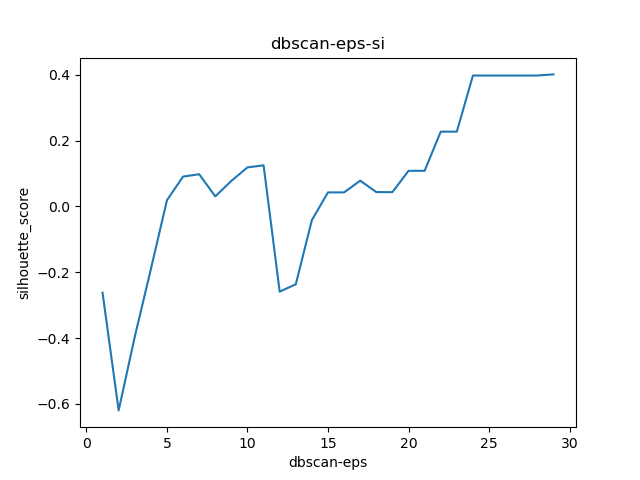
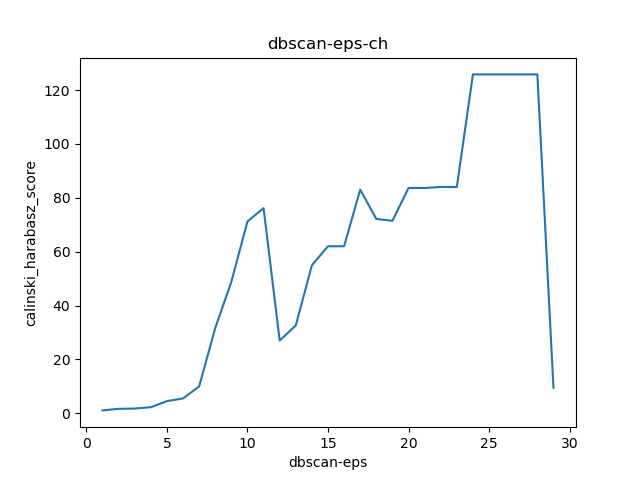
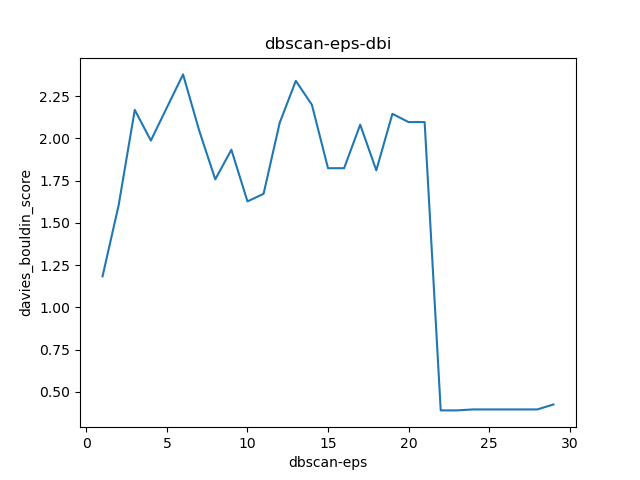
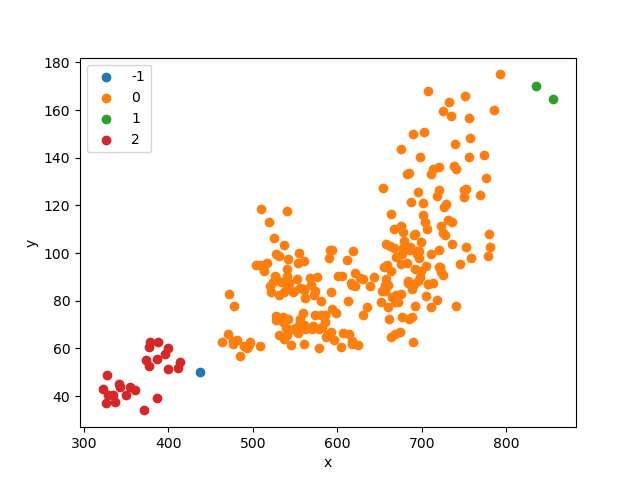
数据及代码
https://github.com/SeafyLiang/machine_learning_study/blob/master/cluster/cluster_measure.py

若有收获,就点个赞吧
0 人点赞
